后来重新复习的时候,发现这篇文章不错:https://www.cnblogs.com/z-sm/p/5691760.html
一:前提
1.安装条件
Java Scala
zookeeper
Kafka
2.使用版本
使用的版本是0.8.2.1

------------------

二:伪分布式安装
1.解压
kafka_2.10-0.8.2.1
2.拷贝server.properties

3.依次修改四个文件
官网上:说明这三个配置项是必要的。

主要要配置的有:
broker.id=0 :服务器唯一标识
port=9092 :服务器监听端口
host.name=linux-hadoop01.ibeifeng.com : 服务器监听主机名
log.dirs=/opt/modules/kafka_2.10-0.8.2.1/data/0 :kafka数据存储路径
zookeeper.connect=linux-hadoop01.ibeifeng.com:2181/kafka :元数据管理的zookeeper的配置信息
需要修改四个文件,这里只写第一个。
1 # Licensed to the Apache Software Foundation (ASF) under one or more 2 # contributor license agreements. See the NOTICE file distributed with 3 # this work for additional information regarding copyright ownership. 4 # The ASF licenses this file to You under the Apache License, Version 2.0 5 # (the "License"); you may not use this file except in compliance with 6 # the License. You may obtain a copy of the License at 7 # 8 # http://www.apache.org/licenses/LICENSE-2.0 9 # 10 # Unless required by applicable law or agreed to in writing, software 11 # distributed under the License is distributed on an "AS IS" BASIS, 12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 13 # See the License for the specific language governing permissions and 14 # limitations under the License. 15 # see kafka.server.KafkaConfig for additional details and defaults 16 17 ############################# Server Basics ############################# 18 19 # The id of the broker. This must be set to a unique integer for each broker. 20 broker.id=0 21 22 ############################# Socket Server Settings ############################# 23 24 # The port the socket server listens on 25 port=9092 26 27 # Hostname the broker will bind to. If not set, the server will bind to all interfaces 28 host.name=linux-hadoop01.ibeifeng.com 29 30 # Hostname the broker will advertise to producers and consumers. If not set, it uses the 31 # value for "host.name" if configured. Otherwise, it will use the value returned from 32 # java.net.InetAddress.getCanonicalHostName(). 33 #advertised.host.name=<hostname routable by clients> 34 35 # The port to publish to ZooKeeper for clients to use. If this is not set, 36 # it will publish the same port that the broker binds to. 37 #advertised.port=<port accessible by clients> 38 39 # The number of threads handling network requests 40 num.network.threads=3 41 42 # The number of threads doing disk I/O 43 num.io.threads=8 44 45 # The send buffer (SO_SNDBUF) used by the socket server 46 socket.send.buffer.bytes=102400 47 48 # The receive buffer (SO_RCVBUF) used by the socket server 49 socket.receive.buffer.bytes=102400 50 51 # The maximum size of a request that the socket server will accept (protection against OOM) 52 socket.request.max.bytes=104857600 53 54 55 ############################# Log Basics ############################# 56 57 # A comma seperated list of directories under which to store log files 58 log.dirs=/opt/modules/kafka_2.10-0.8.2.1/data/0 59 60 # The default number of log partitions per topic. More partitions allow greater 61 # parallelism for consumption, but this will also result in more files across 62 # the brokers. 63 num.partitions=1 64 65 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. 66 # This value is recommended to be increased for installations with data dirs located in RAID array. 67 num.recovery.threads.per.data.dir=1 68 69 ############################# Log Flush Policy ############################# 70 71 # Messages are immediately written to the filesystem but by default we only fsync() to sync 72 # the OS cache lazily. The following configurations control the flush of data to disk. 73 # There are a few important trade-offs here: 74 # 1. Durability: Unflushed data may be lost if you are not using replication. 75 # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush. 76 # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks. 77 # The settings below allow one to configure the flush policy to flush data after a period of time or 78 # every N messages (or both). This can be done globally and overridden on a per-topic basis. 79 80 # The number of messages to accept before forcing a flush of data to disk 81 #log.flush.interval.messages=10000 82 83 # The maximum amount of time a message can sit in a log before we force a flush 84 #log.flush.interval.ms=1000 85 86 ############################# Log Retention Policy ############################# 87 88 # The following configurations control the disposal of log segments. The policy can 89 # be set to delete segments after a period of time, or after a given size has accumulated. 90 # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens 91 # from the end of the log. 92 93 # The minimum age of a log file to be eligible for deletion 94 log.retention.hours=168 95 96 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining 97 # segments don't drop below log.retention.bytes. 98 #log.retention.bytes=1073741824 99 100 # The maximum size of a log segment file. When this size is reached a new log segment will be created. 101 log.segment.bytes=1073741824 102 103 # The interval at which log segments are checked to see if they can be deleted according 104 # to the retention policies 105 log.retention.check.interval.ms=300000 106 107 # By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires. 108 # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction. 109 log.cleaner.enable=false 110 111 ############################# Zookeeper ############################# 112 113 # Zookeeper connection string (see zookeeper docs for details). 114 # This is a comma separated host:port pairs, each corresponding to a zk 115 # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". 116 # You can also append an optional chroot string to the urls to specify the 117 # root directory for all kafka znodes. 118 zookeeper.connect=linux-hadoop01.ibeifeng.com:2181/kafka 119 120 # Timeout in ms for connecting to zookeeper 121 zookeeper.connection.timeout.ms=6000
4.启动ZK
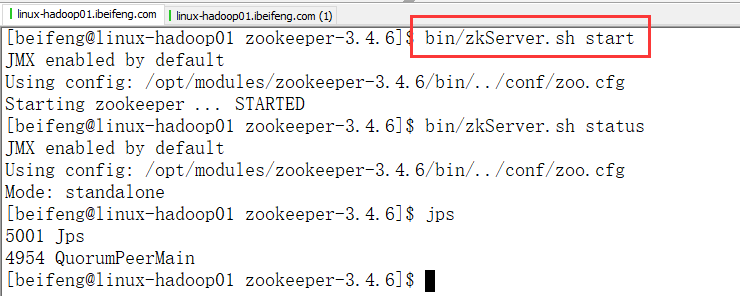
5.进入zkCli

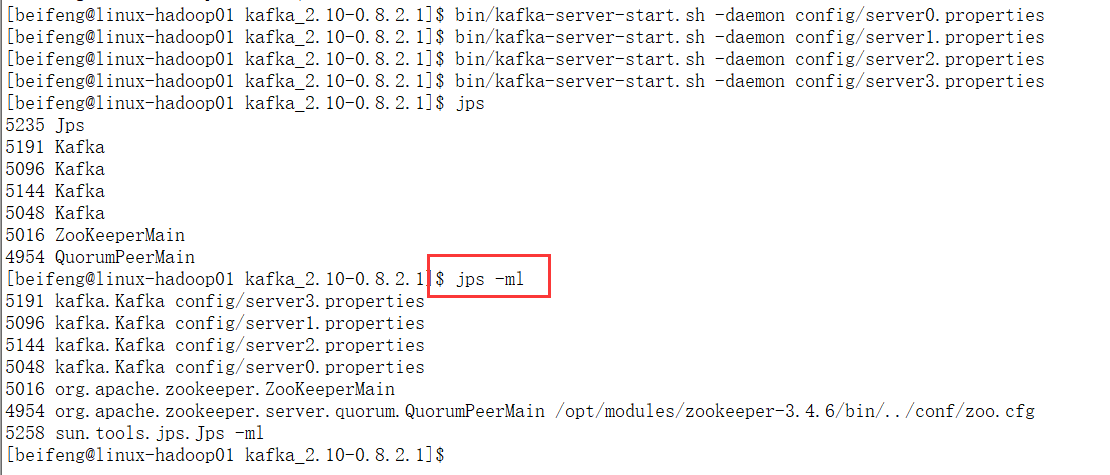
6.启动kafka

具体的jps
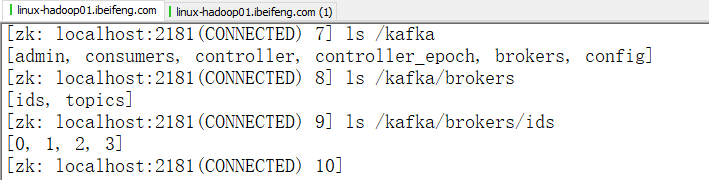
7.这个时候再看zkCli

看ids:
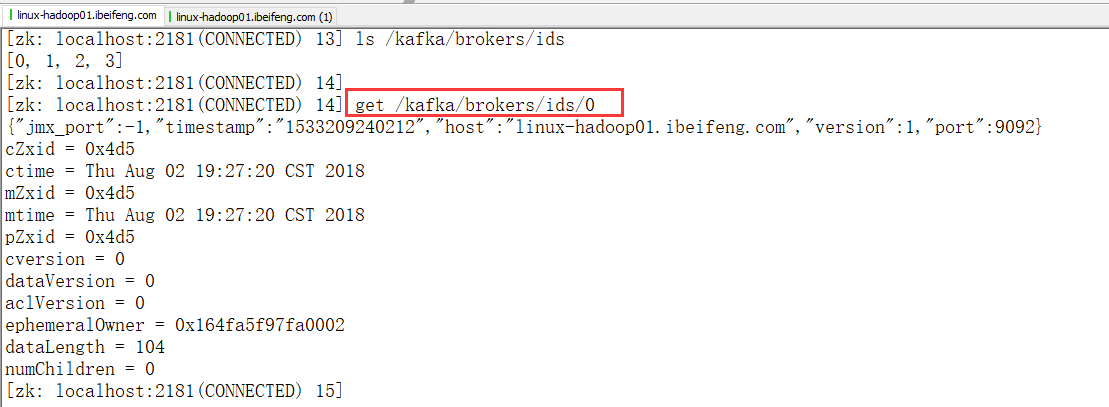
看ids=0的值:
8.关闭命令