1.SparkStream
入口:StreamingContext
抽象:DStream
2.SparkStreaming内部原理
当一个批次到达的时候,会产生一个rdd,这个rdd的数据就是这个批次所接收/应该处理的数据内容,内部具体执行是rdd job的调度
batchDuration: 产生RDD的间隔时间(定时任务,间隔给定时间后会生产一个RDD),产生的RDD会缓存到一个Map<Time, RDD>;RDD的调度当集合中有一个rdd的time时间超过当前时间的时候(>=),对应的rdd被触发操作
一:安装nc
1.说明
netcat(nc)是一个简单而有用的工具,被誉为网络安全界的“瑞士均道”。
不仅可以通过使用TCP或UDP协议的网络连接读写数据,同时还是一个功能强大的网络调试和探测工具,能够建立你需要的几乎所有类型的网络连接。
2.检测nc
3.安装
sudo yum install -y nc
4.检查是否可以使用
5.使用数据进行测试
在一个终端输入数据:

6.解决问题
因为,这里安装了高版本的nc,centos在6.4不适合nc。
不建议使用nc这种yum的方式。
7.卸载
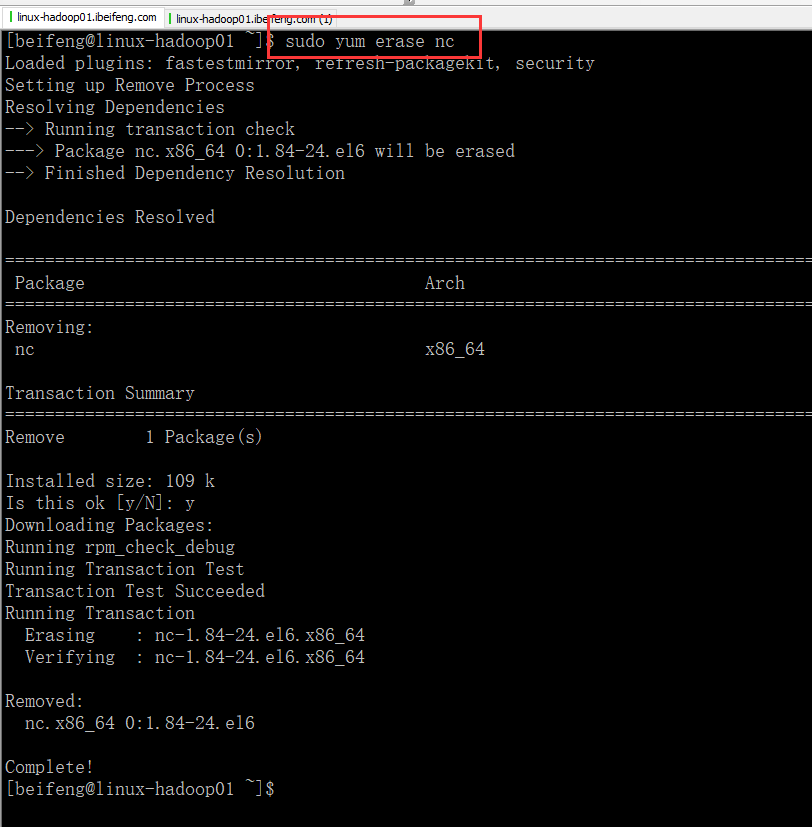
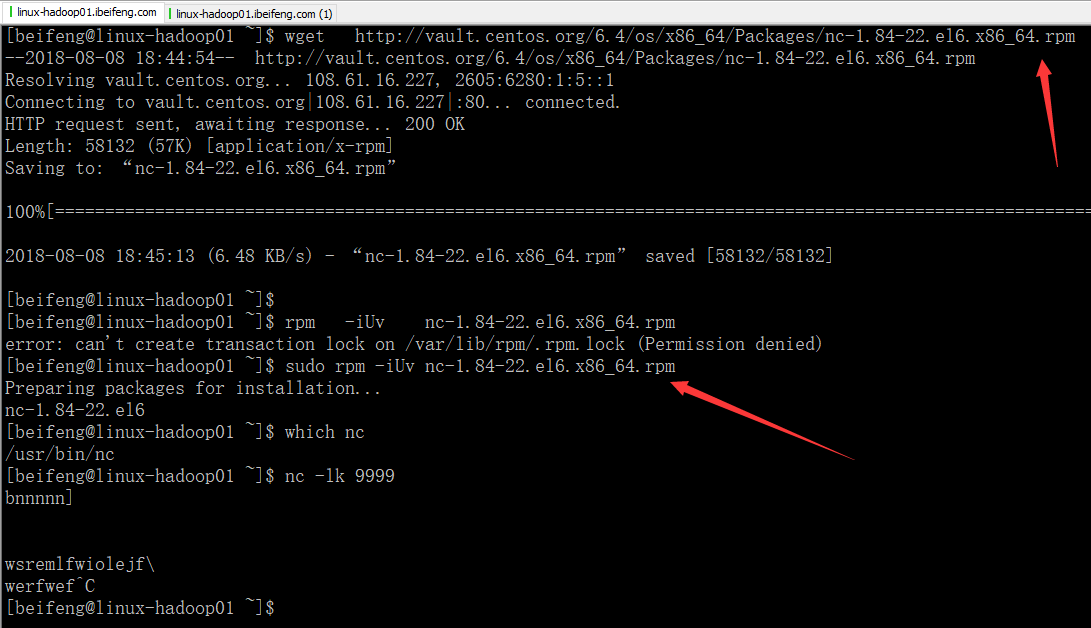
8.重新安装
下载合适的版本
wget http://vault.centos.org/6.4/os/x86_64/Packages/nc-1.84-22.el6.x86_64.rpm
rpm -iUv nc-1.84-22.el6.x86_64.rpm
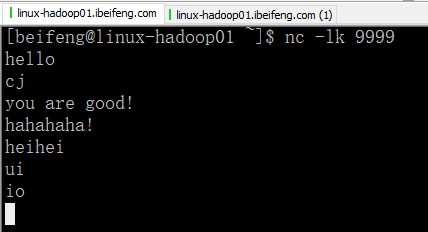
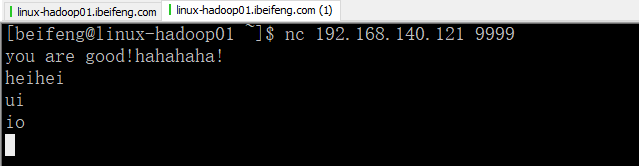
9.测试接受数据
发送:
接收:
10.yum install nc.x86_64
这样下载的nc版本是nc-1.84-24.e
版本还是高,和直接yum install nc的版本一样。
二:程序
1.程序
1 package com.stream.it 2 3 import org.apache.spark.streaming.{Seconds, StreamingContext} 4 import org.apache.spark.{SparkConf, SparkContext} 5 6 object SparkStreamWordcount { 7 def main(args: Array[String]): Unit = { 8 val conf=new SparkConf() 9 .setAppName("spark-streaming-wordcount") 10 .setMaster("local[*]") 11 val sc=SparkContext.getOrCreate(conf) 12 val ssc=new StreamingContext(sc,Seconds(15)) 13 val hostname="linux-hadoop01.ibeifeng.com" 14 val port=9999 15 val dstream=ssc.socketTextStream(hostname,port) 16 17 /** 18 * 80%的RDD上的方法可以在DStream上直接使用 19 */ 20 val resultWordcount=dstream 21 .filter(line=>line.nonEmpty) 22 .flatMap(line=>line.split(" ").map((_,1))) 23 .reduceByKey(_+_) 24 resultWordcount.foreachRDD(rdd=>{ 25 rdd.foreachPartition(iter=>iter.foreach(println)) 26 }) 27 28 //启动 29 ssc.start() 30 //等到 31 ssc.awaitTermination() 32 } 33 }
2.发送数据
3.控制台
