这里面包含了如何在kafka+sparkStreaming集成后的开发,也包含了一部分的优化。
一:说明
1.官网
指导网址:http://spark.apache.org/docs/1.6.1/streaming-kafka-integration.html

2.SparkStream+kafka
Use Receiver
内部使用kafka的high lenel consumer API
consumer offset 只能保持到zk/kafka中,只能通过配置进行offset的相关操作
Direct
内部使用的是kafka的simple consumer api
自定义对kafka的offset偏移量进行控制操作
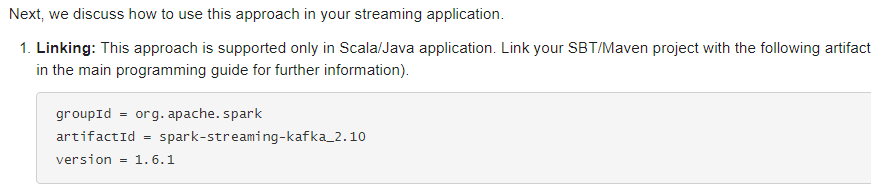
集成依赖pom配置:
二:单Receiver的程序
1.先启动服务
在这里需要启动kafka的生产者
2.程序
1 package com.stream.it 2 3 import kafka.serializer.StringDecoder 4 import org.apache.spark.storage.StorageLevel 5 import org.apache.spark.streaming.dstream.ReceiverInputDStream 6 import org.apache.spark.streaming.kafka.KafkaUtils 7 import org.apache.spark.streaming.{Seconds, StreamingContext} 8 import org.apache.spark.{SparkConf, SparkContext} 9 10 object KafkaWordcount { 11 def main(args: Array[String]): Unit = { 12 val conf=new SparkConf() 13 .setAppName("spark-streaming-wordcount") 14 .setMaster("local[*]") 15 val sc=SparkContext.getOrCreate(conf) 16 val ssc=new StreamingContext(sc,Seconds(15)) 17 18 /* 19 def createStream[K: ClassTag, V: ClassTag, U <: Decoder[_]: ClassTag, T <: Decoder[_]: ClassTag]( 20 ssc: StreamingContext, 21 kafkaParams: Map[String, String], 22 topics: Map[String, Int], 23 storageLevel: StorageLevel 24 ): ReceiverInputDStream[(K, V)] 25 */ 26 val kafkaParams=Map("group.id"->"stream-sparking-0", 27 "zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka", 28 "auto.offset.reset"->"smallest" 29 ) 30 val topics=Map("beifeng"->1) 31 val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder]( 32 ssc, //给定sparkStreaming的上下文 33 kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接 34 topics, //给定读取对应的topic的名称以及读取数据的线程数量 35 StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别 36 ).map(_._2) 37 38 39 val resultWordcount=dStream 40 .filter(line=>line.nonEmpty) 41 .flatMap(line=>line.split(" ").map((_,1))) 42 .reduceByKey(_+_) 43 resultWordcount.foreachRDD(rdd=>{ 44 rdd.foreachPartition(iter=>iter.foreach(println)) 45 }) 46 47 //启动 48 ssc.start() 49 //等到 50 ssc.awaitTermination() 51 } 52 }
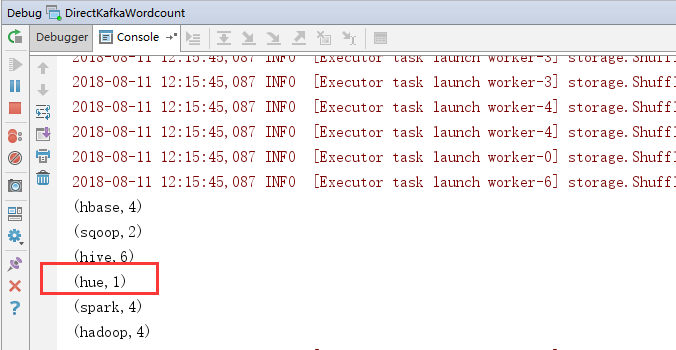
3.效果
在kafka producer输入内容,将会在控制台上进行展示
三:多Receiver
1.说明
当当个reveiver接收的数据被限制的时候,可以使用多个receiver
2.程序
1 package com.stream.it 2 3 import kafka.serializer.StringDecoder 4 import org.apache.spark.storage.StorageLevel 5 import org.apache.spark.streaming.kafka.KafkaUtils 6 import org.apache.spark.streaming.{Seconds, StreamingContext} 7 import org.apache.spark.{SparkConf, SparkContext} 8 9 object MulReceiverKafkaWordcount { 10 def main(args: Array[String]): Unit = { 11 val conf=new SparkConf() 12 .setAppName("spark-streaming-wordcount2") 13 .setMaster("local[*]") 14 val sc=SparkContext.getOrCreate(conf) 15 val ssc=new StreamingContext(sc,Seconds(15)) 16 17 /* 18 def createStream[K: ClassTag, V: ClassTag, U <: Decoder[_]: ClassTag, T <: Decoder[_]: ClassTag]( 19 ssc: StreamingContext, 20 kafkaParams: Map[String, String], 21 topics: Map[String, Int], 22 storageLevel: StorageLevel 23 ): ReceiverInputDStream[(K, V)] 24 */ 25 val kafkaParams=Map("group.id"->"stream-sparking-0", 26 "zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka", 27 "auto.offset.reset"->"smallest" 28 ) 29 val topics=Map("beifeng"->4) 30 val dStream1=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder]( 31 ssc, //给定sparkStreaming的上下文 32 kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接 33 topics, //给定读取对应的topic的名称以及读取数据的线程数量 34 StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别 35 ).map(_._2) 36 37 val dStream2=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder]( 38 ssc, //给定sparkStreaming的上下文 39 kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接 40 topics, //给定读取对应的topic的名称以及读取数据的线程数量 41 StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别 42 ).map(_._2) 43 44 //合并dstream 45 val dStream=dStream1.union(dStream2) 46 47 48 val resultWordcount=dStream 49 .filter(line=>line.nonEmpty) 50 .flatMap(line=>line.split(" ").map((_,1))) 51 .reduceByKey(_+_) 52 resultWordcount.foreachRDD(rdd=>{ 53 rdd.foreachPartition(iter=>iter.foreach(println)) 54 }) 55 56 //启动 57 ssc.start() 58 //等到 59 ssc.awaitTermination() 60 } 61 }
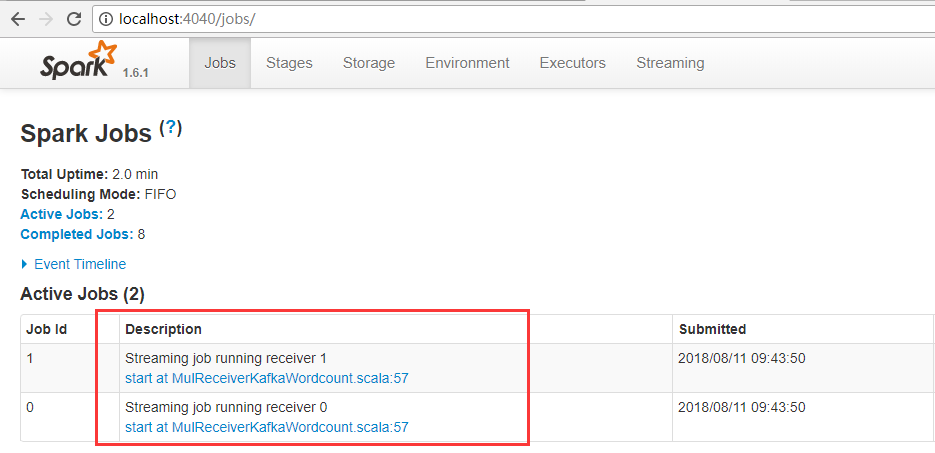
3.效果
一条数据是一个event
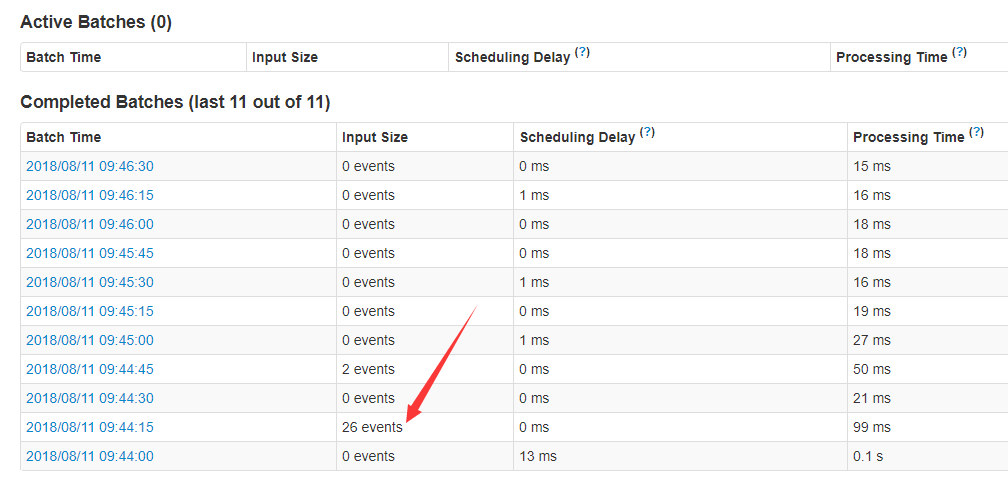
这里有两个receiver。
四:Direct
1.说明
直接读取,不存在receiver
不足,kafkaParams指定连接kafka的参数,内部使用的是kafka的SimpleConsumerAPI,所以,offset只能从头或者从尾开始读取,不能设置。
topics:topic的名称
2.程序
1 package com.stream.it 2 3 import kafka.serializer.StringDecoder 4 import org.apache.spark.storage.StorageLevel 5 import org.apache.spark.streaming.kafka.KafkaUtils 6 import org.apache.spark.streaming.{Seconds, StreamingContext} 7 import org.apache.spark.{SparkConf, SparkContext} 8 9 object DirectKafkaWordcount { 10 def main(args: Array[String]): Unit = { 11 val conf=new SparkConf() 12 .setAppName("spark-streaming-wordcount") 13 .setMaster("local[*]") 14 val sc=SparkContext.getOrCreate(conf) 15 val ssc=new StreamingContext(sc,Seconds(15)) 16 25 val kafkaParams=Map( 26 "metadata.broker.list"->"linux-hadoop01.ibeifeng.com:9092,linux-hadoop01.ibeifeng.com:9093,linux-hadoop01.ibeifeng.com:9094", 27 "auto.offset.reset"->"smallest" 28 ) 29 val topics=Set("beifeng") 30 val dStream=KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder]( 31 ssc, 32 kafkaParams, 33 topics).map(_._2) 34 35 val resultWordcount=dStream 36 .filter(line=>line.nonEmpty) 37 .flatMap(line=>line.split(" ").map((_,1))) 38 .reduceByKey(_+_) 39 resultWordcount.foreachRDD(rdd=>{ 40 rdd.foreachPartition(iter=>iter.foreach(println)) 41 }) 42 43 //启动 44 ssc.start() 45 //等到 46 ssc.awaitTermination() 47 } 48 }
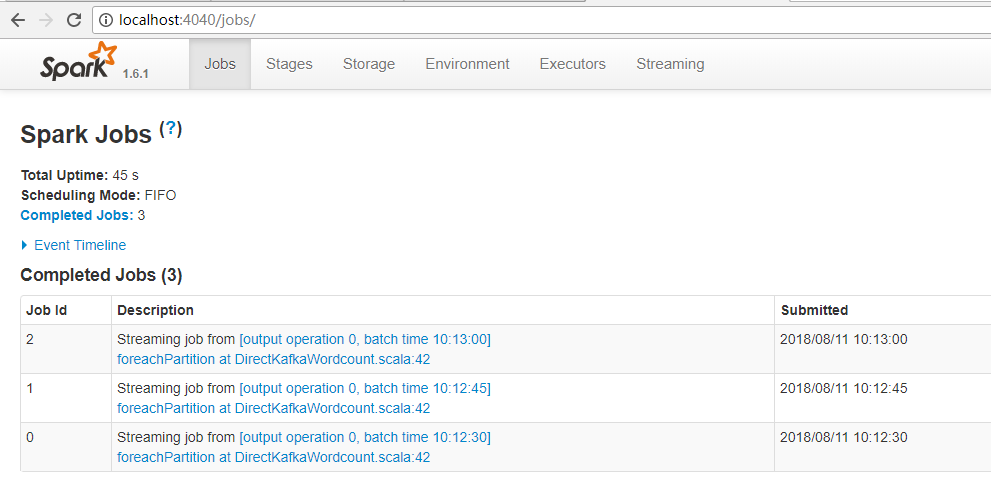
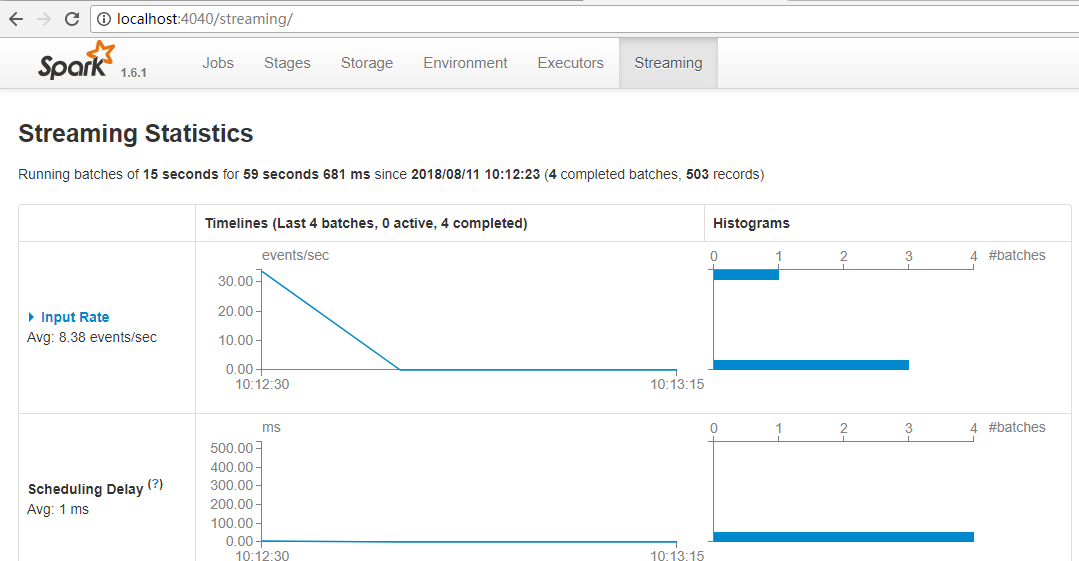
3.效果
没有receiver。
五:Direct实现是累加器管理offset偏移量
1.程序
kafkaParams 中只有这个参数下才能生效。
数据先进行保存或者打印,然后更新accumulable中的offset,然后下一批的dstream进行更新offset。
累加器需要在外面进行定义。
1 package com.stream.it 2 3 import scala.collection.mutable 4 import kafka.common.TopicAndPartition 5 import kafka.message.MessageAndMetadata 6 import kafka.serializer.StringDecoder 7 import org.apache.spark.storage.StorageLevel 8 import org.apache.spark.streaming.kafka.KafkaUtils 9 import org.apache.spark.streaming.{Seconds, StreamingContext} 10 import org.apache.spark.{Accumulable, AccumulableParam, SparkConf, SparkContext} 11 12 object AccumubaleKafkaWordcount { 13 def main(args: Array[String]): Unit = { 14 val conf=new SparkConf() 15 .setAppName("spark-streaming-wordcount") 16 .setMaster("local[*]") 17 val sc=SparkContext.getOrCreate(conf) 18 val ssc=new StreamingContext(sc,Seconds(15)) 19 val accumu = DroppedAccumulable.getInstance(sc) 20 21 val kafkaParams = Map( 22 "metadata.broker.list" -> "linux-hadoop01.ibeifeng.com:9092,linux-hadoop01.ibeifeng.com:9093,linux-hadoop01.ibeifeng.com:9094,linux-hadoop01.ibeifeng.com:9095" 23 ) 24 25 // TODO: 从某一个存储offset的地方读取offset偏移量数据, redishbase其他地方..... 26 val fromOffsets = Map( 27 TopicAndPartition("beifeng", 0) -> -1L, // 如果这里给定的偏移量是异常的,会直接从kafka中读取偏移量数据(largest) 28 TopicAndPartition("beifeng", 1) -> 0L, 29 TopicAndPartition("beifeng", 2) -> 0L, 30 TopicAndPartition("beifeng", 3) -> 0L 31 ) 32 33 34 val dstream = KafkaUtils.createDirectStream[String, String, kafka.serializer.StringDecoder, kafka.serializer.StringDecoder, String]( 35 ssc, // 上下文 36 kafkaParams, // kafka连接 37 fromOffsets, 38 (message: MessageAndMetadata[String, String]) => { 39 // 这一块在Executor上被执行 40 // 更新偏移量offset 41 val topic = message.topic 42 val paritionID = message.partition 43 val offset = message.offset 44 accumu += (topic, paritionID) -> offset 45 // 返回value的数据 46 message.message() 47 } 48 ) 49 50 val resultWordCount = dstream 51 .filter(line => line.nonEmpty) 52 .flatMap(line => line.split(" ").map((_, 1))) 53 .reduceByKey(_ + _) 54 55 56 resultWordCount.foreachRDD(rdd => { 57 // 在driver上执行 58 try { 59 rdd.foreachPartition(iter => { 60 // 代码在executor上执行 61 // TODO: 这里进行具体的数据保存操作 62 iter.foreach(println) 63 }) 64 65 // TODO: 在这里更新offset, 将数据写入到redishbase其他地方..... 66 accumu.value.foreach(println) 67 } catch { 68 case e: Exception => // nothings 69 } 70 }) 71 72 73 74 //启动 75 ssc.start() 76 //等到 77 ssc.awaitTermination() 78 } 79 } 80 object DroppedAccumulable { 81 private var instance: Accumulable[mutable.Map[(String, Int), Long], ((String, Int), Long)] = null 82 83 def getInstance(sc: SparkContext): Accumulable[mutable.Map[(String, Int), Long], ((String, Int), Long)] = { 84 if (instance == null) { 85 synchronized { 86 if (instance == null) instance = sc.accumulable(mutable.Map[(String, Int), Long]())(param = new AccumulableParam[mutable.Map[(String, Int), Long], ((String, Int), Long)]() { 87 /** 88 * 将t添加到r中 89 * 90 * @param r 91 * @param t 92 * @return 93 */ 94 override def addAccumulator(r: mutable.Map[(String, Int), Long], t: ((String, Int), Long)): mutable.Map[(String, Int), Long] = { 95 val oldOffset = r.getOrElse(t._1, t._2) 96 if (t._2 >= oldOffset) r += t 97 else r 98 } 99 100 override def addInPlace(r1: mutable.Map[(String, Int), Long], r2: mutable.Map[(String, Int), Long]): mutable.Map[(String, Int), Long] = { 101 r2.foldLeft(r1)((r, t) => { 102 val oldOffset = r.getOrElse(t._1, t._2) 103 if (t._2 >= oldOffset) r += t 104 else r 105 }) 106 } 107 108 override def zero(initialValue: mutable.Map[(String, Int), Long]): mutable.Map[(String, Int), Long] = mutable.Map.empty[(String, Int), Long] 109 }) 110 } 111 } 112 113 // 返回结果 114 instance 115 } 116 }
2.效果
可以将以前的信息打出来。