一:使用场景
1.应用场景
数据的累加
一段时间内的数据的累加
2.说明
每个批次都输出自己批次的数据,
这个时候,可以使用这个API,使得他们之间产生联系。
3.说明2
在累加器的时候,起到的效果和这里的说明想法有些相同,都可以输出上一个批次的信息
二:程序
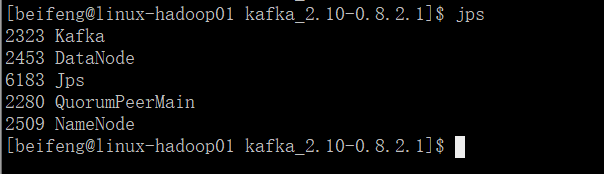
1.需要启动一些服务
需要使用hadoop
2.程序
1 package com.stream.it 2 3 import kafka.serializer.StringDecoder 4 import org.apache.spark.rdd.RDD 5 import org.apache.spark.storage.StorageLevel 6 import org.apache.spark.streaming.kafka.KafkaUtils 7 import org.apache.spark.streaming.{Seconds, StreamingContext} 8 import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} 9 10 object UpdateStateByKeyKafkaWordcount { 11 def main(args: Array[String]): Unit = { 12 val conf=new SparkConf() 13 .setAppName("spark-streaming-wordcount") 14 .setMaster("local[*]") 15 val sc=SparkContext.getOrCreate(conf) 16 val ssc=new StreamingContext(sc,Seconds(15)) 17 18 val kafkaParams=Map("group.id"->"stream-sparking-0", 19 "zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka", 20 "auto.offset.reset"->"smallest" 21 ) 22 val topics=Map("beifeng"->1) 23 val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder]( 24 ssc, //给定sparkStreaming的上下文 25 kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接 26 topics, //给定读取对应的topic的名称以及读取数据的线程数量 27 StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别 28 ).map(_._2) 29 30 31 // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir 32 // 路径对应的文件夹不能存在 33 ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") 34 44 /** 45 def updateStateByKey[S: ClassTag]( 46 updateFunc: (Seq[V], Option[S]) => Option[S], 47 partitioner: Partitioner, 48 initialRDD: RDD[(K, S)] 49 ): DStream[(K, S)] 50 */ 51 52 val resultWordcount=dStream 53 .filter(line=>line.nonEmpty) 54 .flatMap(line=>line.split(" ").map((_,1))) 55 .reduceByKey(_+_) 56 .updateStateByKey( 57 (values: Seq[Int], state: Option[Long]) => { 58 // 从value中获取累加值 59 val sum = values.sum 60 61 // 获取以前的累加值 62 val oldStateSum = state.getOrElse(0L) 63 64 // 更新状态值并返回 65 Some(oldStateSum + sum) 66 } 69 ) 70 71 72 resultWordcount.foreachRDD(rdd=>{ 73 rdd.foreachPartition(iter=>iter.foreach(println)) 74 }) 75 76 //启动 77 ssc.start() 78 //等到 79 ssc.awaitTermination() 80 } 81 }
三:updateStateByKey的优化
1.说明
主要的情况是,程序停止,刚刚累加的数据不再存在。
重启后效果如下:
只剩下,已经被checkPoint的数据,后面的数据不再存在。
2.优化的程序
多加两个参数。
1 package com.stream.it 2 3 import kafka.serializer.StringDecoder 4 import org.apache.spark.rdd.RDD 5 import org.apache.spark.storage.StorageLevel 6 import org.apache.spark.streaming.kafka.KafkaUtils 7 import org.apache.spark.streaming.{Seconds, StreamingContext} 8 import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} 9 10 object UpdateStateByKeyKafkaWordcount { 11 def main(args: Array[String]): Unit = { 12 val conf=new SparkConf() 13 .setAppName("spark-streaming-wordcount") 14 .setMaster("local[*]") 15 val sc=SparkContext.getOrCreate(conf) 16 val ssc=new StreamingContext(sc,Seconds(15)) 17 18 val kafkaParams=Map("group.id"->"stream-sparking-0", 19 "zookeeper.connect"->"linux-hadoop01.ibeifeng.com:2181/kafka", 20 "auto.offset.reset"->"largest" 21 ) 22 val topics=Map("beifeng"->1) 23 val dStream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder]( 24 ssc, //给定sparkStreaming的上下文 25 kafkaParams, //kafka的参数信息,通过kafka HightLevelComsumerApi连接 26 topics, //给定读取对应的topic的名称以及读取数据的线程数量 27 StorageLevel.MEMORY_AND_DISK_2 //数据接收器接收到kafka的数据后的保存级别 28 ).map(_._2) 29 30 31 // 当调用updateStateByKey函数API的时候,必须给定checkpoint dir 32 // 路径对应的文件夹不能存在 33 ssc.checkpoint("hdfs://linux-hadoop01.ibeifeng.com:8020/beifeng/spark/streaming/chkdir01") 34 35 // 初始化updateStateByKey用到的状态值 36 // 从保存状态值的地方(HBase)读取状态值, 这里采用模拟的方式 37 val initialRDD: RDD[(String, Long)] = sc.parallelize( 38 Array( 39 ("hadoop", 100L), 40 ("spark", 25L) 41 ) 42 ) 43 44 /** 45 def updateStateByKey[S: ClassTag]( 46 updateFunc: (Seq[V], Option[S]) => Option[S], 47 partitioner: Partitioner, 48 initialRDD: RDD[(K, S)] 49 ): DStream[(K, S)] 50 */ 51 52 val resultWordcount=dStream 53 .filter(line=>line.nonEmpty) 54 .flatMap(line=>line.split(" ").map((_,1))) 55 .reduceByKey(_+_) 56 .updateStateByKey( 57 (values: Seq[Int], state: Option[Long]) => { 58 // 从value中获取累加值 59 val sum = values.sum 60 61 // 获取以前的累加值 62 val oldStateSum = state.getOrElse(0L) 63 64 // 更新状态值并返回 65 Some(oldStateSum + sum) 66 }, 67 new HashPartitioner(ssc.sparkContext.defaultParallelism), // 分区器 68 initialRDD // 初始化状态值 69 ) 70 71 72 resultWordcount.foreachRDD(rdd=>{ 73 rdd.foreachPartition(iter=>iter.foreach(println)) 74 }) 75 76 //启动 77 ssc.start() 78 //等到 79 ssc.awaitTermination() 80 } 81 }
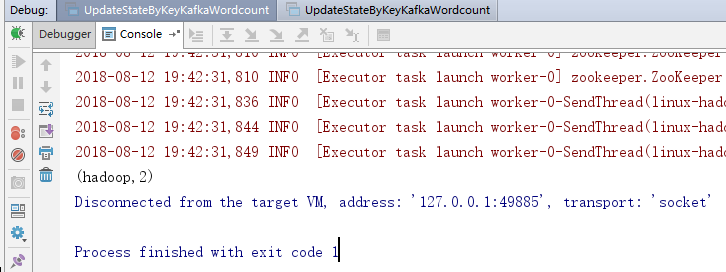
3.运行效果

4.注意点
需要有checkPoint的路径。
累加值存在硬盘中,长时间不访问会被删除。