对于有扩展平台以适应更高负载经验的工程师和管理员来说,复制(replication)是不可或缺的。复制可以让其他服务器拥有一个不断更新的数据副本,从而使得拥有数据副本的服务器可以用于处理客户端发送的读请求。关系数据库通常会使用一个主服务器(master)向多个从服务器(slave)发送更新,并使用从服务器来处理所有读请求。Redis也采用了同样的方法来实现自己的复制特性,并将其用作扩展性能的一种手段。本节将对Redis的复制配置选项进行讨论,并说明Redis在进行复制时的各个步骤。
尽管Redis的性能非常优秀,但它也会遇上没办法快速处理请求的情况,特别是在对集合和有序集合进行操作的时候,涉及的元素可能会有上万个甚至上百万个,在这种情况下,执行操作所花费的时间可能需要以秒来进行计算,而不是毫秒或者微秒。但即使一个命令只需要花费10毫秒就能完成,单个Redis实例(instance)1秒也只能处理100个命令。
SUNIONSTORE命令的性能作为对Redis性能的一个参考,在主频为2.4GHz的英特尔酷睿2处理器上,对两个分别包含10000个元素的集合执行SUNIONSTORE命令并产生一个包含20000个元素的结果集合,需要花费Redis七八毫秒的时间。
在需要扩展读请求的时候,或者在需要写入临时数据的时候,用户可以通过设置额外的Redis从服务器来保存数据集的副本。在接收到主服务器发送的数据初始副本(initialcopyofthedata)之后,客户端每次向主服务器进行写入时,从服务器都会实时地得到更新。在部署好主从服务器之后,客户端就可以向任意一个从服务器发送读请求了,而不必再像之前一样,总是把每个读请求都发送给主服务器(客户端通常会随机地选择使用哪个从服务器,从而将负载平均分配到各个从服务器上)。
接下来的一节将介绍配置Redis主从服务器的方法,并说明Redis在整个复制过程中所做的各项操作。
对Redis的复制相关选项进行配置
当从服务器连接主服务器的时候,主服务器会执行BGSAVE操作。因此为了正确地使用复制特性,用户需要保证主服务器已经正确地设置了dir选项和dbfilename选项,并且这两个选项所指示的路径和文件对于Redis进程来说都是可写的(writable)。
尽管有多个不同的选项可以控制从服务器自身的行为,但开启从服务器所必须的选项只有slaveof一个。如果用户在启动Redis服务器的时候,指定了一个包含slaveofhostport选项的配置文件,那么Redis服务器将根据该选项给定的IP地址和端口号来连接主服务器。对于一个正在运行的Redis服务器,用户可以通过发送SLAVEOFnoone命令来让服务器终止复制操作,不再接受主服务器的数据更新;也可以通过发送SLAVEOF host port命令来让服务器开始复制一个新的主服务器。
开启Redis的主从复制特性并不需要进行太多的配置,但了解Redis服务器是如何变成主服务器或者从服务器的,对于我们来说将是非常有用的和有趣的过程。
Redis复制的启动过程
本章前面曾经说过,从服务器在连接一个主服务器的时候,主服务器会创建一个快照文件并将其发送至从服务器,但这只是主从复制执行过程的其中一步。表4-2完整地列出了当从服务器连接主服务器时,主从服务器执行的所有操作。
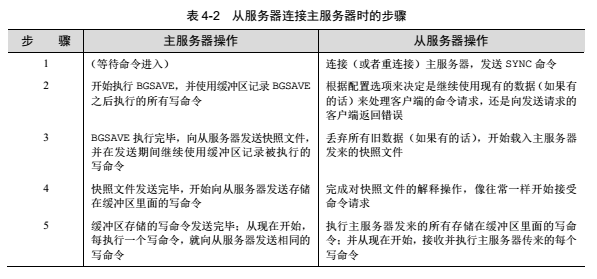
通过使用表4-2所示的办法,Redis在复制进行期间也会尽可能地处理接收到的命令请求,但是,如果主从服务器之间的网络带宽不足,或者主服务器没有足够的内存来创建子进程和创建记录写命令的缓冲区,那么Redis处理命令请求的效率就会受到影响。因此,尽管这并不是必须的,但在实际中最好还是让主服务器只使用50%~65%的内存,留下30%~45%的内存用于执行BGSAVE命令和创建记录写命令的缓冲区。
设置从服务器的步骤非常简单,用户既可以通过配置选项SLAVEOFhostport来将一个Redis服务器设置为从服务器,又可以通过向运行中的Redis服务器发送SLAVEOF命令来将其设置为从服务器。如果用户使用的是SLAVEOF配置选项,那么Redis在启动时首先会载入当前可用的任何快照文件或者AOF文件,然后连接主服务器并执行表4-2所示的复制过程。如果用户使用的是SLAVEOF命令,那么Redis会立即尝试连接主服务器,并在连接成功之后,开始表4-2所示的复制过程。
从服务器在进行同步时,会清空自己的所有数据。因为有些用户在第一次使用从服务器时会忘记这件事,所以这里要特别提醒一下:从服务器在与主服务器进行初始连接时,数据库中原有的所有数据都将丢失,并被替换成主服务器发来的数据。
警告:Redis不支持主主复制(master-masterreplication)因为Redis允许用户在服务器启动之后使用SLAVEOF命令来设置从服务器选项(slavingoptions),所以可能会有读者误以为可以通过将两个Redis实例互相设置为对方的主服务器来实现多主复制(multi-masterreplication)(甚至可能会在一个循环里面将多个实例互相设置为主服务器)。遗憾的是,这种做法是行不通的:被互相设置为主服务器的两个Redis实例只会持续地占用大量处理器资源并且连续不断地尝试与对方进行通信,根据客户端连接的服务器的不同,客户端的请求可能会得到不一致的数据,或者完全得不到数据。
当多个从服务器尝试连接同一个主服务器的时候,就会出现表4-3所示的两种情况中的其中一种。

在大部分情况下,Redis都会尽可能地减少复制所需的工作,然而,如果从服务器连接主服务器的时间并不凑巧,那么主服务器就需要多做一些额外的工作。另一方面,当多个从服务器同时连接主服务器的时候,同步多个从服务器所占用的带宽可能会使得其他命令请求难以传递给主服务器,与主服务器位于同一网络中的其他硬件的网速可能也会因此而降低。
主从链
有些用户发现,创建多个从服务器可能会造成网络不可用——当复制需要通过互联网进行或者需要在不同数据中心之间进行时,尤为如此。因为Redis的主服务器和从服务器并没有特别不同的地方,所以从服务器也可以拥有自己的从服务器,并由此形成主从链(master/slavechaining)。
从服务器对从服务器进行复制在操作上和从服务器对主服务器进行复制的唯一区别在于,如果从服务器X拥有从服务器Y,那么当从服务器X在执行表4-2中的步骤4时,它将断开与从服务器Y的连接,导致从服务器Y需要重新连接并重新同步(resync)。
当读请求的重要性明显高于写请求的重要性,并且读请求的数量远远超出一台Redis服务器可以处理的范围时,用户就需要添加新的从服务器来处理读请求。随着负载不断上升,主服务器可能会无法快速地更新所有从服务器,或者因为重新连接和重新同步从服务器而导致系统超载。为了缓解这个问题,用户可以创建一个由Redis主从节点(master/slavenode)组成的中间层来分担主服务器的复制工作,如图4-1所示。
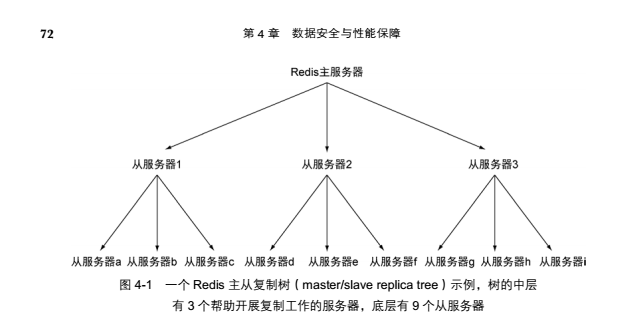
尽管主从服务器之间并不一定要像图4-1那样组成一个树状结构,但记住并理解这种树状结构对于Redis复制来说是可行的(possible)并且是合理的(reasonable),将有助于读者理解之后的内容。AOF持久化(参考:Redis数据持久化)的同步选项可以控制数据丢失的时间长度:通过将每个写命令同步到硬盘里面,用户几乎可以不损失任何数据(除非系统崩溃或者硬盘驱动器损坏),但这种做法会对服务器的性能造成影响;另一方面,如果用户将同步的频率设置为每秒一次,那么服务器的性能将回到正常水平,但故障可能会造成1秒的数据丢失。通过同时使用复制和AOF持久化,我们可以将数据持久化到多台机器上面。
为了将数据保存到多台机器上面,用户首先需要为主服务器设置多个从服务器,然后对每个从服务器设置appendonly yes选项和appendfsync everysec选项(如果有需要的话,也可以对主服务器进行相同的设置),这样的话,用户就可以让多台服务器以每秒一次的频率将数据同步到硬盘上了。但这还只是第一步:因为用户还必须等待主服务器发送的写命令到达从服务器,并且在执行后续操作之前,检查数据是否已经被同步到了硬盘里面。
参考资料
黄健宏:<Redis实战>