优化器在解析含表连接的的sql时,当它根据目标sql的sql文本的写法决定表连接的类型之后,接下来要做的事情之一就是决定表连接的方法。在oracle数据库中,两个表之间的表连接方法有排序合并连接(merge sort join)、嵌套循环连接(nested loop join)、哈希连接(hash join)、笛卡尔连接(cross join)这四种方法各有其优缺点: (本篇文章待优化)
1.排序合并连接:是一种两个表在做表连接时用排序操作和合并操作来得到连接结果集的表连接方法。如果两个表t1,t2在做表连接时候使用的是排序合并连接,则oracle顺序执行如下步骤:
(1)首先以目标sql中指定的谓词条件(如有的话)去访问表t1,然后对访问结果按照表t1的连接条件列来排序,排好序的结果集我们记为结果集1.
(2)接着以目标sql中指定的谓词条件(如有的话)去访问表t2,然后对访问结果按照表t2的连接条件列来排序,排好序的结果集我们记为结果集2.
(3)最后对结果集1和结果集2进行合并,从中取出匹配记录来作为排序合并连接的最终执行结果。个人认为这个合并操作具体执行步骤:首先遍历结果集1中第一条记录,然后去结果集2中按照连接条件判断是否存在匹配的记录,然后再去取结果集1的第2条记录,按照同样的连接条件再去结果集2中判断是否存在匹配的记录,直到遍历完结果集1中所有的记录。注意:这里去结果集2中判断是否存在匹配记录时会存在一个过滤的过程。因为结果集2已经按照连接列条件完成排序,所以只需要遍历结果集2中满足上述连接条件的那部分就可以了(这部分数据在结果集2中的存储位置肯定是在一起的)。
对于排序合并连接的优缺点及使用场景,总结:
->通常情况下,排序合并连接的执行效率远不如哈希连接,但是前者的适用范围更广,因为哈希连接只能用于等值连接条件,而排序合并连接还用于其他连接条件(<,>,<=,>=)。
->通常情况下,排序合并连接并不适用于OLTP系统,其本质原因是因为对于OLTP系统而言,排序是非常昂贵的操作,当然,如果能避免排序操作,那么即使是OLTP系统,也还是可以使用排序合并连接的。比如两个表虽然是做排序合并操作,但是实际上他们并不需要排序,因为这两个表在各自的连接列上都有索引。
->从严格意义上来讲,排序合并连接并不存在驱动表的概念,但是我个人认为在执行合并的过程中,实际上还是存在驱动表和被驱动表的。
2.嵌套循环连接:(nested loops join)是一种两个表在做表连接时依靠两层嵌套循环(分别为外层循环和内层循环)来得到连接结果集的表连接方法。
如果两个表t1,t2在做表连接时使用的是嵌套循环连接,则oracle会依次顺序执行如下步骤:
(1)首先,优化器会按照一定的规则来决定表t1和t2中谁是驱动表,谁是被驱动表。驱动表用于外层循环,被驱动表用于内层循环,这里假设t1是驱动表,t2是被驱动表
(2)接着以目标sql中指定的谓词条件(如果有的话)去访问驱动表t1,访问驱动表t1后得到的结果集记为结果集1.
(3)然后遍历结果集1并同时遍历被驱动表t2,即先取出驱动结果集1中的第1条记录,接着遍历被驱动表t2并按照连接条件去判断t2中是否存在匹配的记录,然后再取出驱动结果集1中的第2条记录,按照同样的连接条件再去遍历被驱动表t2并判断t2中是否还存在匹配的记录,知道遍历完驱动结果集1中的所有记录为止。这里的外层循环是指遍历驱动结果集1所对应的循环,内层循环是指遍历被驱动表t2所对应的循环。显然,外层循环所对应的驱动结果集1有多少条记录,遍历被驱动表t2的内存循环就要做多少次,这就是所谓的嵌套循环的含义。
对于嵌套循环连接的优缺点,总结:
->如果驱动表所对应的驱动结果集的记录数较少,同时在被驱动表的连接列上又存在唯一性索引(或者在被驱动表的连接列上存在选择性很好的非唯一性索引),那么此时使用嵌套循环连接的执行效率就会非常高;但如果驱动表所对应的驱动结果集的记录数很多,即便在被驱动表的连接列上存在索引,此时使用嵌套循环连接的执行效率也不会很高。
->只要驱动结果集的记录数较少,那就具备了使用嵌套循环连接的前提条件,而驱动结果集是在对驱动表应用了目标sql中指定的谓词条件(如果有的话)后所得到的结果集,所以大表也可以作为嵌套循环连接的驱动表,关键是要看目标sql中指定的谓词条件(如果有的话)能否将驱动结果集的数据量降下来。
->嵌套循环连接有其他连接方法所没有的一个优点,嵌套循环连接可以实现快速响应。即它可以第一时间先返回已经连接过且满足条件的记录,而不必等所有的连接操作全部做完后才返回连接结果。比如排序合并连接要等到排完序后做合并操作时才能开始返回数据,而哈希连接则要等到驱动结果集所对应的hash table全部建完后才能开始返回数据。
如果oracle使用的是嵌套循环连接,且在被驱动表的连接列上存在索引,那么oracle在访问该索引时通常会使用单块读,这意味着嵌套循环连接的驱动结果有多少条记录,oracle就需要访问该索引多少次。另外,如果目标sql中的查询列并不能全部从被驱动表的相关索引中获得,那么oracle在做完嵌套循环连接后就还需要对被驱动表执行回表操作(即用连接结果集每一条记录所含的rowid去回表获取被驱动表中的相关查询列)。这个回表操作通常也会使用单块读,这意味着做完嵌套循环连接后的连接结果集有多少条记录,oracle就需要回表操作多少次。对于单块读而言,如果带访问的索引快或数据块不在buffercache中,oracle就需要消费物理io去相应的数据文件中获取。显然,在单块读的数据量不降低的情况下,如果能减少这种单块读所需要耗费的物理io数量,那么嵌套循环连接的执行效率也会随之提高。为了提高嵌套循环连接的执行效率,在oracle11g中,引入了向量io(vector io),在引入向量io后,oracle就可以将原先一批单块读所需要消费的物理io组合起来,然后用一个向量去批量处理它们,这样就实现了单块读的数量不降低的情况下减少这些单块读所需要耗费的物理io数量,从而提高执行效率。
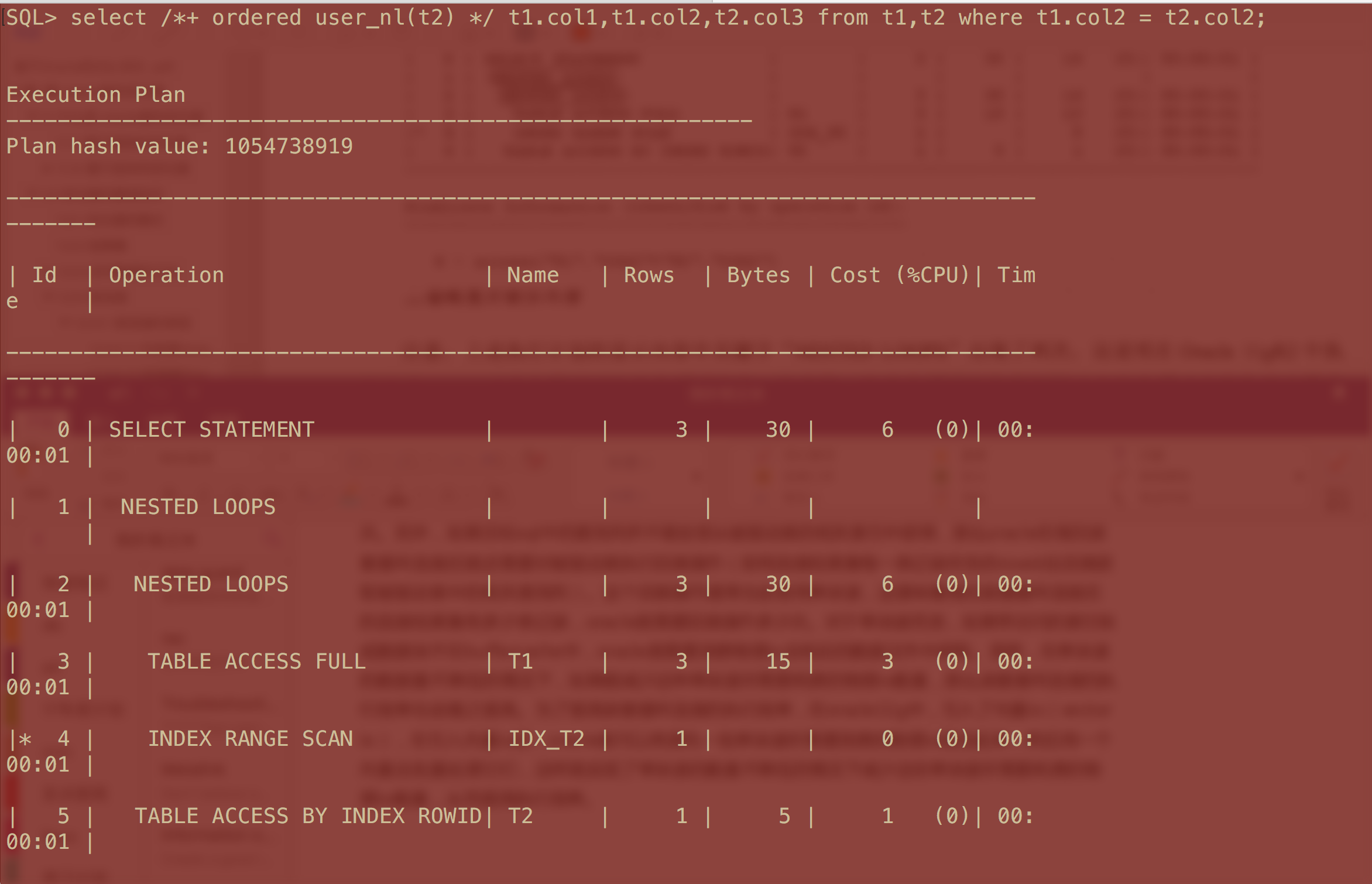
上图我们可以看到有两次nested loops,第二次嵌套循环连接的被驱动表部分所对应的执行步骤是"TABLE ACCESS BY INDEX ROWID | T2", 这可能是因为oracle想表达此时在通过rowid回表访问T2时是把一批rowid组合起来后通过一个向量io批量回表,而不是每拿到一个rowid就用一次单块读访问表。
3.哈希连接:hash join是一种两个表在做表连接时主要依靠哈希运算来得到连接结果集的表连接方法。在oracle7.3之前,oracle数据库中的常用连接方法就只有排序合并连接和嵌套循环连接两种,但这两种方法都各有其明显缺陷,对于排序合并连接,如果两个表施加了目标sql中指定的谓词条件(如果有的话)后得到的结果集很大且需要排序,则排序合并连接效率不一定高;而对于嵌套循环连接如果驱动表所对应的驱动结果集很大,即便是在被驱动表的连接列上存在索引,此时使用嵌套循环连接的执行效率也不高。为了解决上述情况下执行效率不高的问题,同时也为了给优化器提供一种新的选择,oracle在oracle7.3引入了哈希连接。从理论上来说,哈希连接的执行效率回避排序合并连接和嵌套循环连接要高,当然,实际情况并不总是这样。
在oracle10g及其以后的oracle数据库版本中,优化器(实际上是CBO,因为哈希连接仅限适用于CBO)在解析目标sql时是否考虑哈希连接是受限于隐含参数_hash_join_enabled,它的默认值是true,表示允许CBO在解析目标sql时使用哈希连接,即使该参数改成了false,使用user_hash hint依然可以让CBO在解析目标sql时考虑哈希连接,这说明user_hash hint的优先级比参数_hash_join_enabled的优先级要高。如果两个表t1,t2在做表连接时使用的是哈希连接,则oracle会依次执行如下步骤:
(1)首先oracle会根据参数hash_area_size,db_block_size,_hash_multiblock_io_count的值来决定hash partition的数量(hash partition是一个逻辑上的概念,它实际上是一组hash bucket的集合。所有hash partition的集合就被称为hash table。
(2)表t1和t2在施加了目标sql中指定的谓词条件(如果有的话)后,得到的结果集数据量较少的那个结果集就会被oracle选择哈希连接的驱动结果集,假设S是驱动结果集,B是被驱动结果集
(3)接着oracle会遍历S,读取S中的每一条记录,并对每一条记录按照该记录在表t1中的连接列做哈希运算。这个哈希运算会使用两个内置哈希函数,这两个哈希函数会同时对该连接列计算哈希值,我们把这两个内置哈希函数分别记为hash_func_1,hash_func_2,他们所计算出来的哈希值分别记为hash_value_1,hash_value_2.
(4)然后oracle会按照hash_value_1的值把相应的S中的对应记录存储在不同hash_parition的不同hash_bucket里,同时和该记录存储在一起的还有该记录用hash_func_2计算出来的hash_value_2,注意,存储在hash_bucket里的记录并不是目标表的完整行记录,只需要存储位于目标sql中与目标表相关的查询列和连接列就足够了。我们把S所对应的每一个hash_partition记录Si。
(5)在构建Si的同时,oracle会构建一个位图(bitmap),这个位图用来标记Si所包含的每一个hash bucket是否有记录(记录是否大于0)
(6)如果S的数据量巨大,那么在构建S所对应的hash table时,就会出现PGA的工作区被填满的情况,这时候oracle会把工作区中包含记录数最多的hashpartition写到磁盘上(temp表空间),接着oracle会继续构建S所对应的hash table,在继续构建的过程中,如果工作区又填满了,则oracle会继续重复上述动作,即挑选包含记录数最多的hash partition写到磁盘上。如果要构建的记录所对用的hash partition已经事先被写到磁盘,那么此时就需要去磁盘上更新hash partition,即把该条记录和hash_value_2直接加到这个已经位于磁盘上的hashpartition的相应的hash bucket中。注意,极端情况下可能会出现只有某个hash partition的部分记录还在内存中,该hash partition的剩余部分和余下的所有hash partition都已被写回到磁盘上。
(7)上述构建S所对应的hash table的过程会一直持续下去,直到遍历完S中的所有记录为止。
(8)接着,oracle会对所有的Si按照它们所包含的记录数来排序,然后把这些已经排好序的hash partition按顺序依次且尽可能全部放到内存中(pga的work area),当然如果实在放不下,放不下的那部分还是会位于磁盘上。显然,如果所有的Si本来就都在内存中,那么就不需要排序了
(9)至此oracle已经处理完S,现在可以开始处理B了
(10)oracle会遍历B,读取B中每一条记录,并按照该记录在表t2中的连接列做哈希运算,这个哈希运算和步骤3中的哈希运算是一样的。
接着oracle会按照该记录所对应的哈希值hash_value_1去Si里去找匹配的hash bucket;如果能找到匹配的则oracle还会遍历该hash bucket中的每一条记录,并校验存储于该hashbucket中的每一条记录的连接列,看是否是真的匹配,如果是真的匹配,那么对应B中记录的位于目标sql中的查询列和该hash bucket中的匹配记录便会组合起来,一起作为满足目标sql连接条件的记录返回,如果找不到匹配的hash bucket,则oracle就会去访问步骤5中构建的位图。说白了,这个位图就是表示此hash bucket的记录是否有存在在磁盘上的情况。我们把B所对应的每一个hashpartition记录Bj。
(11)上述去Si中查找匹配hash bucket和构建Bj的过程会一直持续下去,直到遍历完B中所有记录为止。
(12)至此oracle已经处理完所有位于内存中的Si和对应的Bj,现在只剩下位于磁盘上的Si和Bj还未处理。
(13)处理磁盘上的匹配
(14)对于每一对Sn和Bn,它们之中记录数最少的会被当做驱动结果集,然后oracle会用这个驱动结果集hashbucket里记录的hash_value_2来构建新的hash_table,另外一个记录数较多的会被当做被驱动结果集,然后oracle会用这个被驱动结果集hashbucket里记录的hash_value_2去上述构建的心hashtable中找匹配记录,注意,每一对Sn和Bn而言,oracle始终会选择它们中记录数较少的来作为驱动结果集,所以每一对驱动结果集都可能会发生变化,这就是所谓的动态角色互换。
(15)步骤14H中如果存在匹配记录,则该匹配记录也会作为满足目标sql连接条件的记录返回
(16)上述处理会一直持续下去,直至遍历按完所有的Sn和Bn为止
对于哈希连接的优缺点,总结:
->哈希连接不一定会排序,或者说大多数情况下不用排序
->哈希连接的驱动表所对应的连接列的可选择性应尽可能好,因为这个可选择性会影响对应hashbucket中的记录数,而hashbucket中的记录数又会直接影响从该hashbucket中查找匹配记录的效率,如果一个hashbucket里所包含的记录数过多,则可能会严重降低所对应哈希连接的执行效率,此时典型的表现就是该哈希连接执行了很长时间都没有结束,数据库所在数据库服务器上的CPU占用率很高,但是目标sql所消耗的逻辑读却很低,因为此时大部分时间都耗费在遍历上述hashbucket里的所有记录上,而遍历hashbucket里的记录这个动作发生在pga的工作区里,所以不耗费逻辑读。
->哈希连接只适用于CBO,它也只能用于等值连接条件
->哈希连接很适合于小表和大表之间做表连接且连接结果集的记录数较多的情形,特别是在小表的连接列的可选择性非常好的情况下,这时候哈希连接的执行时间可以近似看作是和全表扫描那个大表所耗费的时间相当。
->当两个表做哈希连接时,如果在施加了目标送去了中指定的谓词条件(如果有的话)后得到的数据量较小的那个结果集所对应的hash table能够完全被容纳在内存中,则此时的哈希连接的执行效率会很高
4.笛卡尔连接:又称为笛卡尔乘积(cartesian product),它是一种两个表在做表连接时没有任何连接条件的表连接方法。
如果两个表t1,t2在做表连接时使用的是笛卡尔连接,则执行步骤如下:
(1)首先以目标sql 中指定的谓词条件(如果有的话)访问表t1,此时得到的结果集我们记为结果集1,这里假设结果集1的记录数为m
(2)接着以目标sql中指定的谓词条件(如果有的话)访问表t2,此时得到的结果集我们记为结果集2,这里假设结果集2的记录数为n
(3)最后对结果集1和结果集2执行合并操作,从中取出匹配记录来作为笛卡尔连接的最终执行结果。这里的特殊之处在于对笛卡尔连接而言,因为没有连接条件,所以在对结果集1和结果集2执行合并操作时,对于结果集1的每一条记录,结果集2的所有记录都满足条件,即他们都会是匹配记录,所以上述笛卡尔连接的连接结果的记录数就是m*n。
对于笛卡尔连接的优缺点及使用场景,总结:
(1)笛卡尔连接的出现通常是由于目标sql中漏写了连接条件,所以笛卡尔连接一般都是不好的,除非刻意这么做
(2)有时候出现笛卡尔连接是因为目标sql中使用了ordered hint,同时在该sql的sql文本中位置相邻的两个表之间又没有直接的关联条件
(3)有时间出现笛卡尔连接是因为目标sql中相关表的统计信息不准。比如三个表t1,t2,t3做表连接,t1和t2的连接条件是t1.id1=t2.id1,t2和t3的连接条件为t2.id2=t3.id2,同时在表t2的连接列id1,id2上存在一个包含这两个连接列的组合索引,如果表t1,t3的统计信息不准,导致oracle认为表t1,t3都有很少的记录数,则此时oracle很可能会选择对t1,t3进行笛卡尔连接然后再和表t2座表连接。显然这种选择还是存在很大风险的,如果t1,t3表记录数很大,则该sql的执行效率就会受到严重影响。
反连接:是一种特殊的连接类型,与内连接和外连接不同,oracle数据库里并没有相关的关键字可以再sql文本中专门表示反连接。t1.x anti= t2.y 表示t1,t2做反连接,t1是驱动表,t2是被驱动表,表示t2中有满足条件t1.x=t2.y的记录存在,则表t1中满足条件的记录就会被丢弃。
当做子查询展开时,oracle经常会把那些外部where条件为not exists、not in 或<>ALL 的子查询转换成对应的反连接。
比如:select * from t1 where col2 not in (select col2 from t2);
或
select * from t1 where col2 <>all (select col2 from t2);
或
select * from t1 where not exists (select 1from t2 where col2 = t1.col2);
这三种sql在连接列上不存在null值时,是等价的,一旦连接列上有了null值,就不完全等价了
not in, <>all对null值敏感,这意味着not in后面的子查询或者常量集合一旦有null出现,则这个sql的执行结果就会成为null,即此时的执行结果不包含任何记录;但是not exists对null值不敏感,这意味着null值对not exists的执行结果不会存在什么影响。oracle11g有个隐含参数_optimizer_null_aware_antijoin如果设为false时,oracle就不走反连接(not in <>all也不会对null敏感)
半连接:是一种特殊的连接类型,与内连接和外连接不同,oracle数据库里也没有相关的关键字可以再sql文本中专门表示半连接。t1.x semi= t2.y 表示t1,t2做半连接,t1是驱动表,t2是被驱动表,表示t2中有满足条件t1.x=t2.y的记录存在,则马上停止搜索表t2。也就是说t2中满足半连接条件的记录即使有多条,表t1中也只会返回第一条满足条件的记录。所以半连接和普通的内连接不同,半连接会去重。
当做子查询展开时,oracle经常会把那些外部where条件为 exists、 in 或=ALL 的子查询转换成对应的半连接。
比如:select * from t1 where col2 in (select col2 from t2);
或
select * from t1 where col2 =all (select col2 from t2);
或
select * from t1 where exists (select 1from t2 where col2 = t1.col2);
上面三个范例sql的执行结果是一样的,而且它们的执行计划的显示内容中均有关键字“HASH SEMI"。
星型连接:通常用于数据仓库类型的应用,它是一种单个事实表(fact table)和多个维度表(dimension table)之间的连接。从严格意义上来讲,星型连接既不是额外的连接类型,也不是一种额外的连接方法,只是它有其自身很明显的、有别于其他连接类型的特征。
星型连接的各维度表之间没有直接的关联条件,其事实表和各维度表之间是基于事实表的外键列和对应维度表的主键列之间的连接,并且通常在事实表的外键列上还会存在对应的位图索引。