遇到这样一个问题:客户查询交易要求实现按照姓名实现模糊查询,单单在姓名简历索引不能解决问题,因为这种百分号在最前面的like条件是没法走索引的,但是同时我们也知道对于有百分号的like条件,如果百分号在like条件的最后面,则这种情况下是可以走索引的。那么能不能实现在不改变上述sql含义的情况下把百分号从like条件的最前面移到最后面呢?使用reverse函数就可以做到这一点。
做个试验:
create table t1 as select * from dba_tables;
create index idx_t1 on t1(object_name);
alter system flush buffer_cache; //请勿在生产环境执行此语句
select object_name,object_id from t1 where object_name like '%EMP';
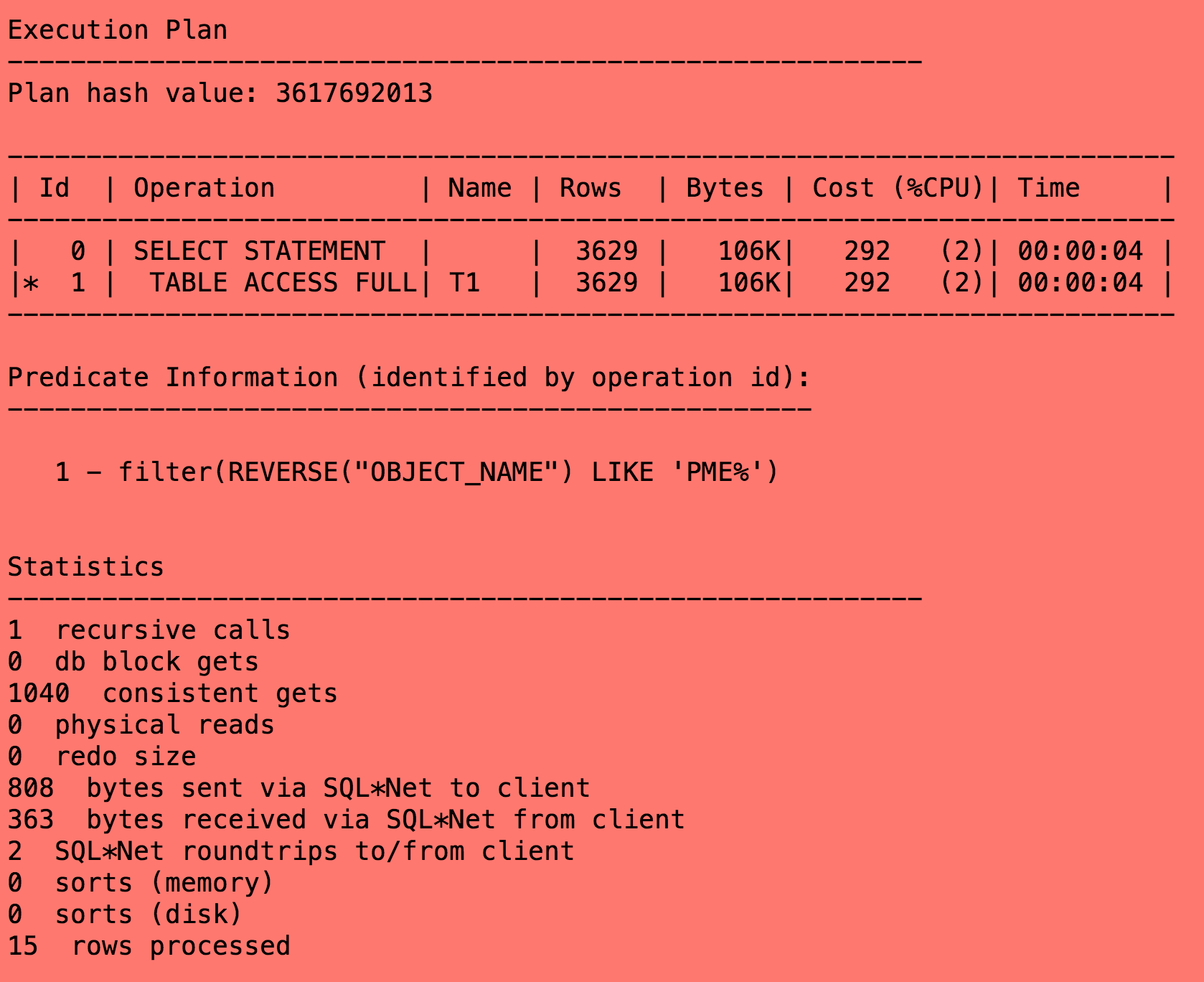
上图可得知,oracle在执行sql时没有用到索引,选择了全表扫描,读了1000多逻辑读。
下面开始转换思路:
create index idx_fun_t1 on t1(reverse(object_name));
alter system flush buffer_cache;
select object_name,object_id from t1 where reverse(object_name) like reverse('%EMP');

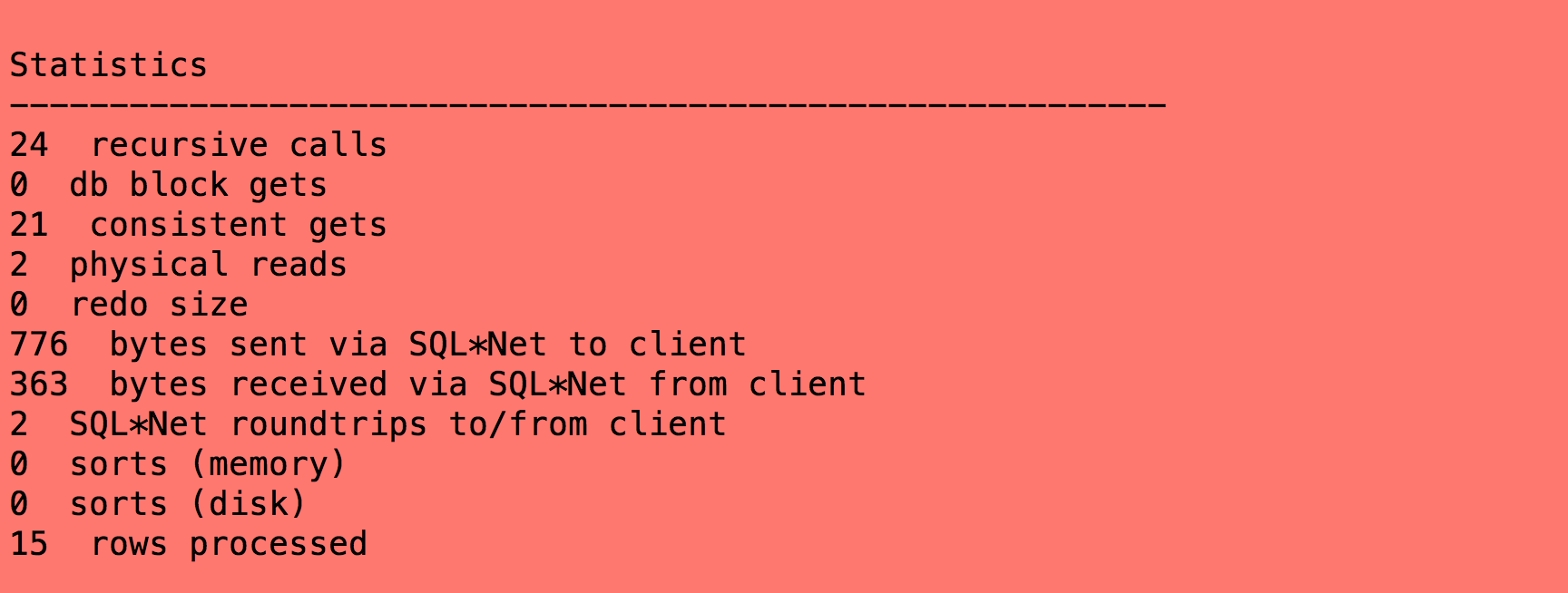
上面图片可以看到,用到了函数索引IDX_FUN_T1,这里的执行时间减少,考费的逻辑读和物理读也降到了不到30.大幅度的降低了目标sql语句的资源消耗,进而大幅缩短了目标sql的执行时间。