ES 为什么要集群
- 高可用。高可用(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
- 负载均衡。将流量均衡的分布在不同的节点上,每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。
- 高性能。将流量分发到不同机器,充分利用多机器多CPU,从串行计算到并行计算提高系统性能。
ES 集群的基本核心概念
Cluster 集群
- 一个 Elastic Search 集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识。
Node 节点
- 一个 Elastic Search 实例即一个 Node,一台机器可以有多个实例,正常使用下每个实例应该会部署在不同的机器上。Elastic Search 的配置文件中可以通过 node.master、node.data 来设置节点类型。
- node.master:表示节点是否具有成为主节点的资格
- true 代表的是有资格竞选主节点
- false 代表的是没有资格竞选主节点
- node.data:表示节点是否存储数据
Node节点组合
- 主节点+数据节点(master+data)节点即有成为主节点的资格,又存储数据
- node.master: true
- node.data: true
- 数据节点(data)节点没有成为主节点的资格,不参与选举,只会存储数据
- node.master: false
- node.data: true
- 客户端节点(client)不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
- node.master: false
- node.data: false
分片
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片(primary shard)和复制分片(replica shard)。复制分片是主分片的拷贝。默认每个主分片有一个复制分片,一个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个节点上。
搭建 ES 集群
搭建步骤
- 拷贝 elasticsearch-7.2.0 安装包3份,分别命名 elasticsearch-7.2.0-a,elasticsearch-7.2.0-b,elasticsearch-7.2.0-c。
- 分别修改 elasticsearch.yml 文件。
- 分别启动 a,b,c 三个节点。
- 打开浏览器输入:http://localhost:9200/_cat/health?v,如果返回的 node.total 是3,代表集群搭建成功
第一个 yml 文件


#集群名称 cluster.name: my-application #节点名称 node.name: node-1 #是不是有资格主节点 node.master: true #是否存储数据 node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 #网关地址 network.host: 0.0.0.0 #端口 http.port: 9200 #内部节点之间沟通端口 transport.tcp.port: 9300 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"] #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径 #path.data: /Users/louis.chen/Documents/study/search/storage/a/data #path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs
第二个 yml 文件
#集群名称 cluster.name: my-application #节点名称 node.name: node-2 #是不是有资格主节点 node.master: true #是否存储数据 node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 #网关地址 network.host: 0.0.0.0 #端口 http.port: 9201 #内部节点之间沟通端口 transport.tcp.port: 9400 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"] #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径 #path.data: /Users/louis.chen/Documents/study/search/storage/a/data #path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs
第三个 yml 文件
#集群名称 cluster.name: my-application #节点名称 node.name: node-3 #是不是有资格主节点 node.master: true #是否存储数据 node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 #网关地址 network.host: 0.0.0.0 #端口 http.port: 9202 #内部节点之间沟通端口 transport.tcp.port: 9500 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"] #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径 #path.data: /Users/louis.chen/Documents/study/search/storage/a/data #path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs
kibana
- 打开配置 kibana.yml,添加 elasticsearch.hosts: ["http://localhost:9200","http://localhost:9201","http://localhost:9202"]
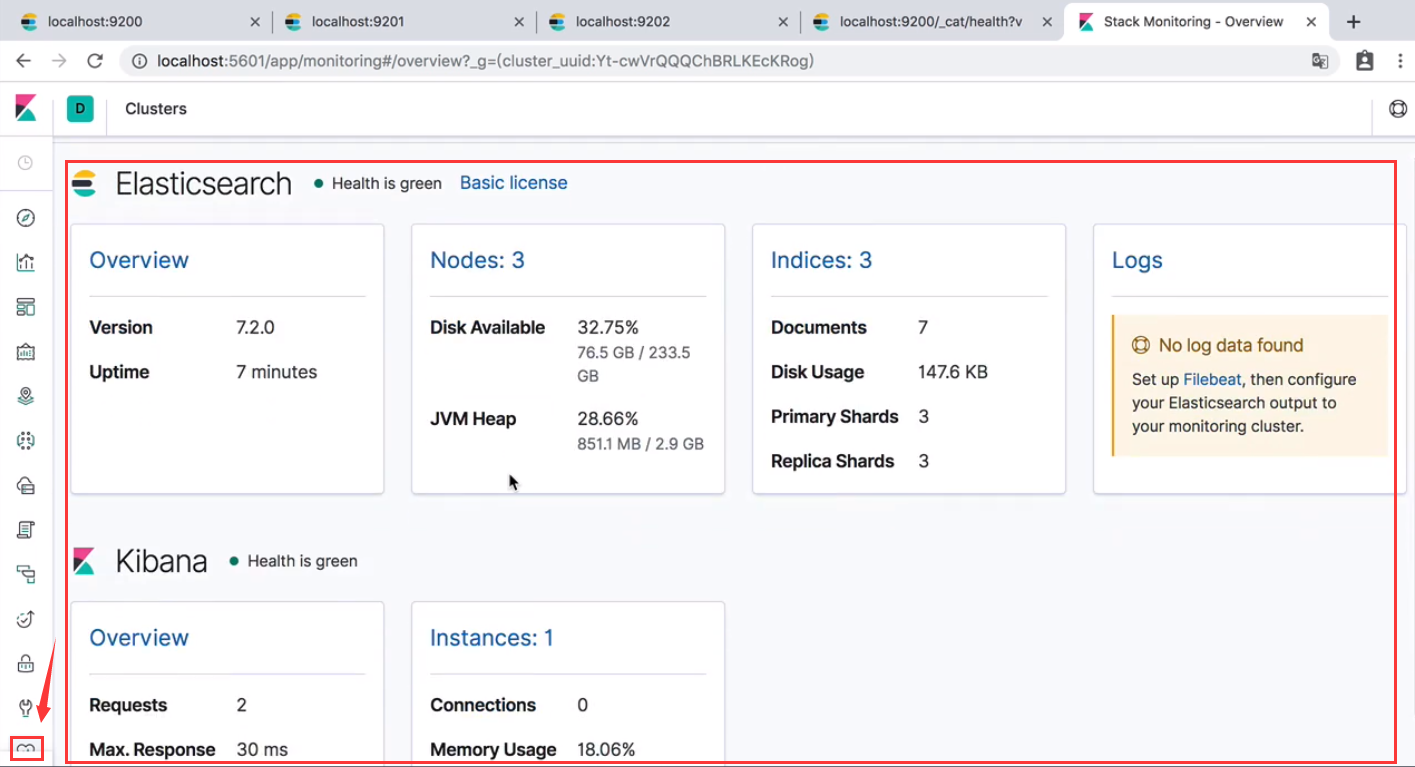
- 启动 kibana,可以看到集群信息

ES 集群健康管理
查看集群的健康状态
http://127.0.0.1:9200/_cat/health?v

- status:集群的状态,red红表示集群不可用,有故障。yellow黄表示集群不可靠但可用,一般单节点时就是此状态。green正常状态,表示集群一切正常。
- node.total:节点数,这里是3,表示该集群有三个节点。
- node.data:数据节点数,存储数据的节点数,这里是3。
- shards:表示我们把数据分成多少块存储。
- pri:主分片数,primary shards
- active_shards_percent:激活的分片百分比,这里可以理解为加载的数据分片数,只有加载所有的分片数,集群才算正常启动,在启动的过程中,如果我们不断刷新这个页面,我们会发现这个百分比会不断加大。
查看集群的索引数
http://127.0.0.1:9200/_cat/indices?v

- health:索引健康,green为正常,yellow表示索引不可靠(单节点),red索引不可用。与集群健康状态一致。
- status:状态表明索引是否打开,索引是可以关闭的。
- index:索引的名称
- uuid:索引内部分配的名称,索引的唯一表示
- pri:集群的主分片数量
- docs.count:这里统计了文档的数量。
- docs.deleted:这里统计了被删除文档的数量。
- store.size:索引的存储的总容量
- pri.store.size:主分片的容量
查看磁盘的分配情况
http://127.0.0.1:9200/_cat/allocation?v

- shards:该节点的分片数量
- disk.indices:该节点中所有索引在该磁盘所占的空间。
- disk.used:该节点已经使用的磁盘容量
- disk.avail:该节点可以使用的磁盘容量
- disk.total:该节点的磁盘容量
查看集群的节点信息
http://127.0.0.1:9200/_cat/nodes?v

- ip:ip地址
- heap.percent:堆内存使用情况
- ram.percent:运行内存使用情况
- cpu:cpu使用情况
- master:是否是主节点
查看集群的其他信息