1、 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import sys import matplotlib.image as img import numpy as np # 读取一张图片 image = img.imread("./1.jpg") print('原图片文件大小:', image.size) print('原图片占内存大小:', sys.getsizeof(image)) print('原图片的数据结构: ', image) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.title("原图片") plt.imshow(image) plt.show()
原图片大小及数据结构

原图片:

# 用kmeans对图片像素颜色进行聚类 image = image[::3, ::3] # 降低分辨率 X = image.reshape(-1, 3) print(image.shape, X.shape) n_colors = 64 model = KMeans(n_colors) labels = model.fit_predict(X) # 获取每个像素的颜色类别 colors = model.cluster_centers_ # 获取每个类别的颜色 new_image = colors[labels].reshape(image.shape) # 以聚类中收替代原像素颜色,还原为二维 print('压缩图片文件大小:', new_image.size) print('压缩图片占内存大小:', sys.getsizeof(new_image)) print('压缩图片的数据结构: ', new_image) img.imsave('D://机器学习/2.jpg', new_image)
压缩图片大小以及数据结构:

原图和压缩图片大小比较:

plt.title("压缩图片") plt.imshow(new_image.astype(np.uint8)) # 把颜色平均值转为整数 plt.show() plt.title("二次压缩图片") plt.imshow(new_image.astype(np.uint8)[::3, ::3]) # 压缩图片进一步压缩,隔3个像素选取 plt.show()
两次压缩图片效果:


2. 观察学习与生活中可以用K均值解决的问题。
观察广州市天河区的房价,数据如下:

我们要观察建筑面积和建楼年份对楼房的价格有和影响,所以选出这三列来构建一个新的数据框,并转为数组:

接着构建模型,完成构建之后,我们把聚类中心(0,1,2)划分为三个数组:

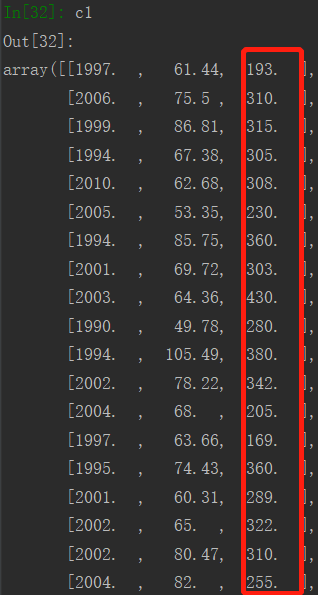
查看a1,b1,c1:(有点误差)
①a1:400 < 总价 < 1000(中价楼盘)

②b1:总价 >1000(高价楼盘)

③c1:总价 <= 400 (低价楼盘)
进行数据可视化,把数据按楼房价格划分,大致可分为高、中、低价三类。可视化结果如下图:
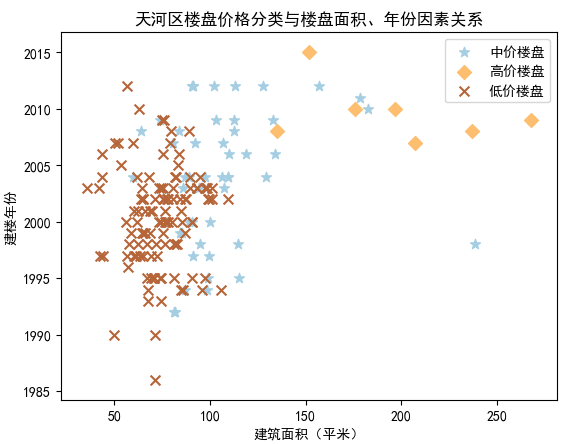
可以发现,建筑面积越大建筑年份越新的那一类价格越高,低价的大多都是占地小,或者建成时间比较长,房子比较老。如果想购买房源,可以对照这两个因素,就差不多有一个价格的预估啦。
代码如下:
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans import pandas as pd house = pd.read_csv('house.csv', index_col=0) # 读取数据 data1 = house[house['区域'] == '天河'] # 取区域在天河区的数据 test_data = data1[['建楼年份', '建筑面积(平米)', '总价']] # 取其中三列作为数据样本 data = np.array(test_data) # 进行类型转换 model = KMeans(n_clusters=3) # 构建模型 model.fit(data) y = model.predict(data) # 进行预测,分类 model.cluster_centers_ a = [] b = [] c = [] d = []
# 数据按聚类中心分类,用于后面可视化 for i in range(len(data)): if y[i] == 0: a.append(data[i, :]) a1 = np.array(a) elif y[i] == 1: b.append(data[i, :]) b1 = np.array(b) else: c.append(data[i, :]) c1 = np.array(c) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.scatter(a1[:, 1], a1[:, 0], s=55, c='#A6CEE3', marker="*") # 聚类中心=0类 plt.scatter(b1[:, 1], b1[:, 0], s=50, c='#FDBF6F', marker="D") # 聚类中心=1类 plt.scatter(c1[:, 1], c1[:, 0], s=50, c='#B66538', marker="x") # 聚类中心=2类 plt.legend(['中价楼盘', '高价楼盘', '低价楼盘']) plt.ylabel("建楼年份") plt.xlabel("建筑面积(平米)") plt.title("天河区楼盘价格分类与楼盘面积、年份因素关系") plt.show()