最近有人反映淘宝的搜索功能要登录才能用,原先的直接爬取的方法挂了。稍微把之前的代码修改了一下,登录采用最简单的复制cookie来解决。
顺便说一下,这只是根据搜索的的索引界面获取的信息,并未深入的获取每个具体商品的信息。为了以后有拓展空间,便于爬取详细的商品信息,我顺便把详情页的URL拿下来了。
淘宝的页面其实并未做多大改变(吐槽一下:淘宝的程序员也挺懒的),之前的代码只要加上登录功能就能使用。
直接上代码:
import requests from bs4 import BeautifulSoup import re from xlwt import Workbook import xlrd import sys R = requests.Session() URL = "https://s.taobao.com/search?q=" """ Get_Html()函数功能:根据搜索的关键字和页数信息,获取包含数据的HTML源码 参数: keyword:字符串,搜索的关键字 page:字符串,页数 返回值: text:字符串,包含数据的HTML源码 """ def Get_Html(keyword,page): url = URL+keyword+"&ie=utf8&s="+str(page) cookies = {} raw_cookies = #这里copy你的cookie,我自然不可能放我的 for lies in raw_cookies.split(';'): key,word = lies.split('=',1) cookies[key] = word res = R.get(url,cookies = cookies) text = res.text return text """ Get_Data()函数功能:从包含数据的HTML源码中解析出需要的数据 参数: text:字符串,是一些包含数据的HTML源码 返回值: data:字符串,包含需要数据的json字符串 """ def Get_Data( text): reg = r',"data":{"spus":[({.+?)]}},"header":' reg = re.compile(reg) data = re.findall(reg, text)[0] return data """ Download_Data()函数功能:将获取的数据选择一部分写入excel表格,如果想写入数据库,这部分代码需要自己写 参数: data:包含数据的json字符串 N:写入excel表的第几行 sheet:excel表的一张表的句柄 """ def Download_Data( data, N, sheet ): Date = eval(data) for d in Date: sheet.write(N,0,d['title']) sheet.write(N,1,d['price']) sheet.write(N,2," ".join([t['tag'] for t in d['tag_info']])) sheet.write(N,3,d['url'][2:]) N = N + 1 return N """ 主调函数,函数工作流程大致如下: 1.创建存储数据需要的sheet表格,目前只获取四个个特征:手机名、价格、特点和商品链接 2.按照关键字进行搜索,然后将获得的数据全部存入创建好的sheet中。 参数: keyword:要搜索的关键字 """ def main(keyword): book = Workbook() sheet = book.add_sheet(keyword) sheet.write(0,0,'品牌') sheet.write(0,1,'价格') sheet.write(0,2,'特点') sheet.write(0,3,'链接') book.save('淘宝数据.xls') k = 0 N = 1 i = 0 while(True): text = Get_Html(keyword,i*48) try: data = Get_Data(text) N = Download_Data(data,N,sheet) except: break book.save('淘宝数据.xls') print('下载第' + str(i+1) + '页完成') i = i + 1 print('全部数据收集完成') if __name__ == '__main__': keyword = sys.argv[1] main(keyword)
只要把上面的Get_HTML()函数中的 raw_cookies 修改成你的 cookie 就可以了,至于怎么获取 cookie ,Google吧!
下面是我以"华为手机"为关键字的部分搜索结果: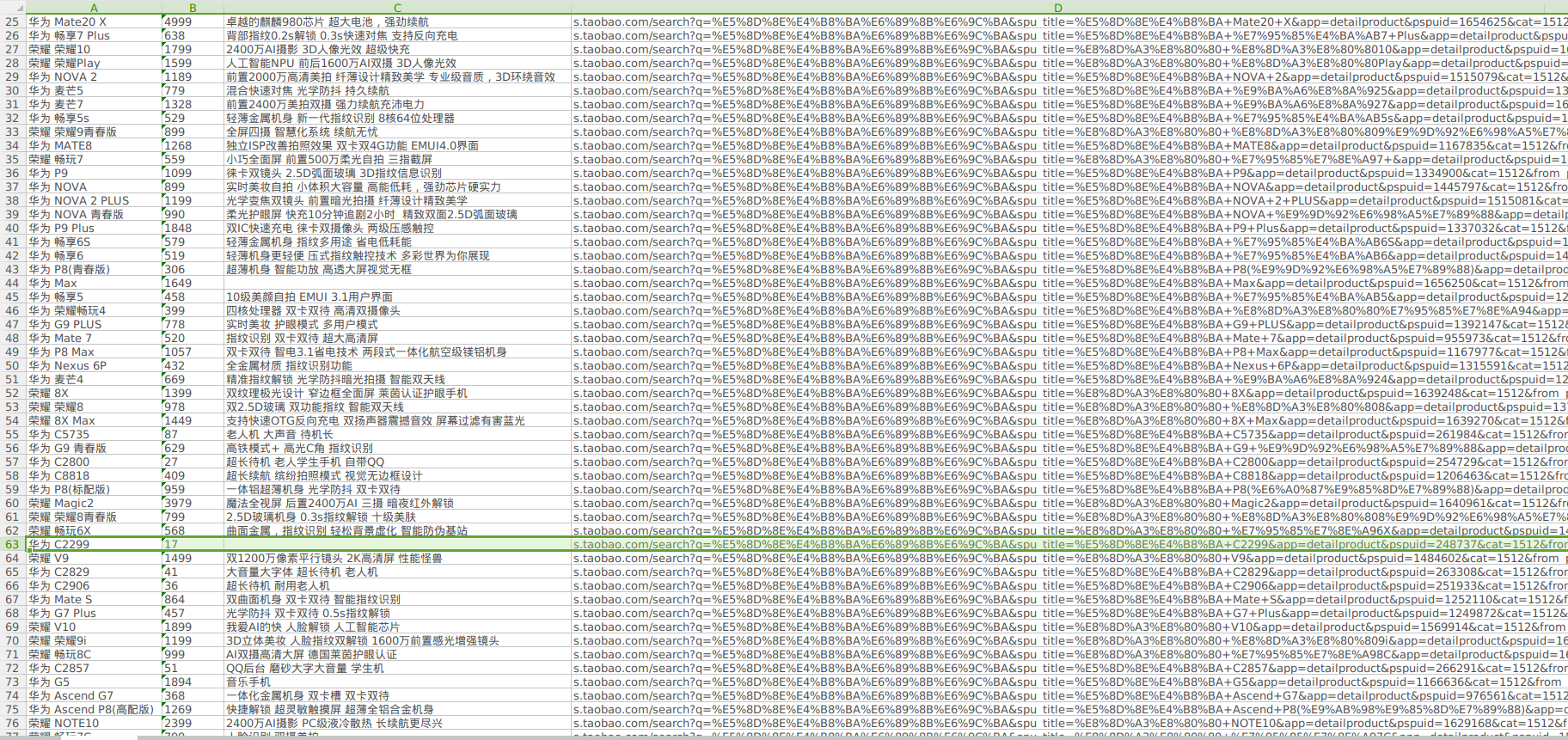
发现了一个17块的华为手机,复制链接一看:
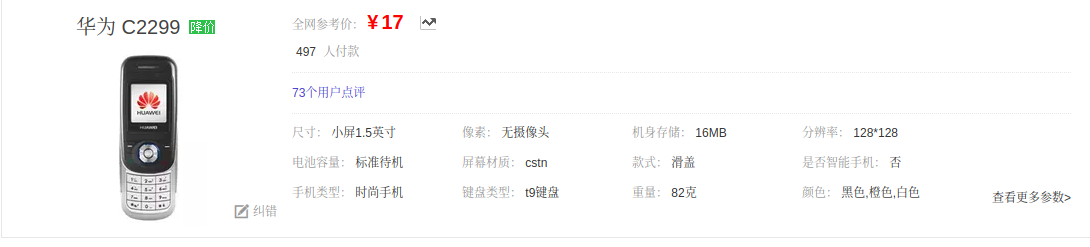
果然...
上面这个页面的信息和评论信息才是更有用的数据,以后有时间再看弄不弄吧!