1.数据采集层介绍
生成的日志文件,需要通过flume采集,然后同步至kafaka,再从kafaka 通过flume同步至hdfs,主要是为了练习使用的技术,设计上面不用纠结。
2.flume source的选择
Taildir Source
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#taildir-source
Watch the specified files, and tail them in nearly real-time once detected new lines appended to the each files. If the new lines are being written, this source will retry reading them in wait for the completion of the write.
This source is reliable and will not miss data even when the tailing files rotate. It periodically writes the last read position of each files on the given position file in JSON format. If Flume is stopped or down for some reason, it can restart tailing from the position written on the existing position file.
3.flume channel的选择
kafka-channel
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#kafka-channel
The events are stored in a Kafka cluster (must be installed separately). Kafka provides high availability and replication, so in case an agent or a kafka broker crashes, the events are immediately available to other sinks
The Kafka channel can be used for multiple scenarios:
- With Flume source and sink - it provides a reliable and highly available channel for events
- With Flume source and interceptor but no sink - it allows writing Flume events into a Kafka topic, for use by other apps 我们用这个
- With Flume sink, but no source - it is a low-latency, fault tolerant way to send events from Kafka to Flume sinks such as HDFS, HBase or Solr
4.flume Interceptor
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-interceptors
lume has the capability to modify/drop events in-flight. This is done with the help of interceptors. Interceptors are classes that implement org.apache.flume.interceptor.Interceptor interface. An interceptor can modify or even drop events based on any criteria chosen by the developer of the interceptor. Flume supports chaining of interceptors.
自定义一个拦截器
https://github.com/Eric-chenjy/log_collector.git
5.flume Channel Selectors
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-channel-selectors
If the type is not specified, then defaults to “replicating”.
我们用:Multiplexing Channel Selector
6.flume agent配置文件
[hadoop@hadoop103 myagents]$ pwd /opt/module/flume/myagents [hadoop@hadoop103 myagents]$ cat test #a1是agengt的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔 a1.sources = r1 a1.channels = c1 c2 a1.sources.r1.type = TAILDIR a1.sources.r1.channels = c1 c2 a1.sources.r1.positionFile = /opt/module/flume/test/taildir_position.json a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /tmp/logs/^app.*log$ #拦截器 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.eric.dw.flume.MyInterceptor$Builder #定义ChannelSelector a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = topic a1.sources.r1.selector.mapping.topic_start = c1 a1.sources.r1.selector.mapping.topic_event = c2 #channel a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.channels.c1.kafka.topic = topic_start #不要header信息 a1.channels.c1.parseAsFlumeEvent=false a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.channels.c2.kafka.topic = topic_event a1.channels.c2.parseAsFlumeEvent=false [hadoop@hadoop103 myagents]$
启动
[hadoop@hadoop103 myagents]$ flume-ng agent -c conf/ -n a1 -f f1.conf -Dflume.root.logger=DEBUG
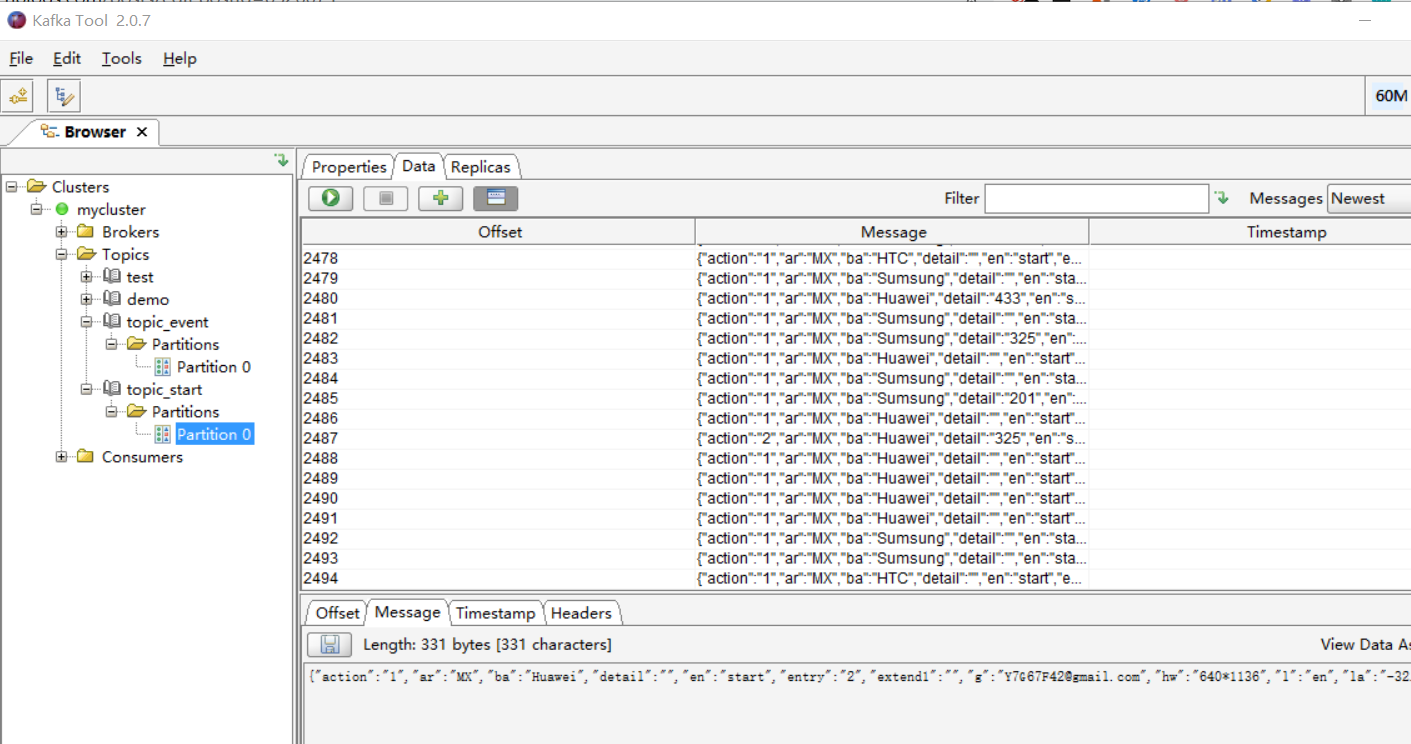
7.验证
8.分发和采集启动脚本编写
分发
[hadoop@hadoop103 flume]$ xsync myagents/ 要分发的文件目录是:/opt/module/flume/myagents ----------------hadoop102----------------- sending incremental file list myagents/ myagents/test sent 1266 bytes received 35 bytes 2602.00 bytes/sec total size is 1166 speedup is 0.90 ----------------hadoop103----------------- sending incremental file list sent 54 bytes received 13 bytes 44.67 bytes/sec total size is 1166 speedup is 17.40 ----------------hadoop104----------------- sending incremental file list myagents/ myagents/test sent 1266 bytes received 35 bytes 2602.00 bytes/sec total size is 1166 speedup is 0.90
[hadoop@hadoop103 flume]$ xsync lib/ 要分发的文件目录是:/opt/module/flume/lib ----------------hadoop102----------------- sending incremental file list lib/ lib/ETLInterceptor-1.0-SNAPSHOT.jar sent 8248 bytes received 35 bytes 16566.00 bytes/sec total size is 52043090 speedup is 6283.12 ----------------hadoop103----------------- sending incremental file list sent 3375 bytes received 13 bytes 6776.00 bytes/sec total size is 52043090 speedup is 15361.01 ----------------hadoop104----------------- sending incremental file list lib/ lib/ETLInterceptor-1.0-SNAPSHOT.jar sent 8248 bytes received 35 bytes 16566.00 bytes/sec total size is 52043090 speedup is 6283.12 [hadoop@hadoop103 flume]$ pwd /opt/module/flume
脚本编写
[hadoop@hadoop103 bin]$ cat f1
#!/bin/bash
#1.start或者stop命令判断
if(($#!=1))
then
echo "请输入start|stop参数"
exit;
fi
#start和stop脚本编写
cmd=cmd
if [ $1 = start ]
then
cmd="nohup flume-ng agent -c $FLUME_HOME/conf/ -n a1 -f $FLUME_HOME/myagents/f1.conf -Dflume.root.logger=DEBUG,co
nsole > /home/hadoop/log/f1.log 2>&1 &"elif [ $1 = stop ]
then
cmd="ps -ef|grep f1.conf |grep -v grep|awk -F ' ' '{print $2}'|xargs kill -9"
else
echo "请输入start|stop参数"
exit;
fi
#执行脚本
for i in hadoop102 hadoop103
do
echo $i
echo $cmd
ssh $i $cmd
done
[hadoop@hadoop103 bin]$
使用
[hadoop@hadoop103 bin]$ f1 stop
hadoop102
ps -ef|grep myagents |grep -v grep|awk -F ' ' '{print $2}'|xargs kill -9
usage: kill [ -s signal | -p ] [ -a ] pid ...
kill -l [ signal ]
hadoop103
ps -ef|grep myagents |grep -v grep|awk -F ' ' '{print $2}'|xargs kill -9
usage: kill [ -s signal | -p ] [ -a ] pid ...
kill -l [ signal ]
[hadoop@hadoop103 bin]$ f1 start
hadoop102
nohup flume-ng agent -c /opt/module/flume/conf/ -n a1 -f /opt/module/flume/myagents/test -Dflume.root.logger=DEBUG,con
sole > /home/hadoop/log/f1.log 2>&1 &hadoop103
nohup flume-ng agent -c /opt/module/flume/conf/ -n a1 -f /opt/module/flume/myagents/test -Dflume.root.logger=DEBUG,con
sole > /home/hadoop/log/f1.log 2>&1 &[hadoop@hadoop103 bin]$ xcall jps
要执行的命令是: jps
----------------hadoop102-----------------
27412 NodeManager
7061 QuorumPeerMain
30165 Jps
27494 JobHistoryServer
30088 Application
27291 DataNode
27181 NameNode
11375 Kafka
----------------hadoop103-----------------
5860 Application
5940 Jps
9590 ResourceManager
9335 DataNode
7690 Kafka
2588 QuorumPeerMain
9709 NodeManager
----------------hadoop104-----------------
1489 Jps
27498 NodeManager
11403 Kafka
27293 DataNode
26670 QuorumPeerMain
[hadoop@hadoop103 bin]$
9.数据从kafaka到hdfs配置:基本配置
flume相关配置,使用KafkaSource,FileChannel,HDFFSSink
flume agent配置文件
[hadoop@hadoop103 myagents]$ pwd /opt/module/flume/myagents [hadoop@hadoop103 myagents]$ ll total 8 -rw-rw-r-- 1 hadoop hadoop 2386 Nov 20 11:13 f2.conf -rw-rw-r-- 1 hadoop hadoop 1166 Nov 16 19:08 test [hadoop@hadoop103 myagents]$ cat f2.conf ## 组件 a1.sources=r1 r2 a1.channels=c1 c2 a1.sinks=k1 k2 ## source1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r1.kafka.topics=topic_start a1.sources.r1.kafka.consumer.auto.offset.reset=earliest a1.sources.r1.kafka.consumer.group.id=CG_Start ## source2 a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r2.batchSize = 5000 a1.sources.r2.batchDurationMillis = 2000 a1.sources.r2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r2.kafka.topics=topic_event a1.sources.r2.kafka.consumer.auto.offset.reset=earliest a1.sources.r2.kafka.consumer.group.id=CG_Event ## channel1 a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/ a1.channels.c1.maxFileSize = 2146435071 a1.channels.c1.capacity = 1000000 a1.channels.c1.keep-alive = 6 ## channel2 a1.channels.c2.type = file a1.channels.c2.checkpointDir = /opt/module/flume/checkpoint/behavior2 a1.channels.c2.dataDirs = /opt/module/flume/data/behavior2/ a1.channels.c2.maxFileSize = 2146435071 a1.channels.c2.capacity = 1000000 a1.channels.c2.keep-alive = 6 ## sink1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = logstart- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = second ##sink2 a1.sinks.k2.type = hdfs a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d a1.sinks.k2.hdfs.filePrefix = logevent- a1.sinks.k2.hdfs.round = true a1.sinks.k2.hdfs.roundValue = 10 a1.sinks.k2.hdfs.roundUnit = second ## 不要产生大量小文件 a1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k2.hdfs.rollInterval = 10 a1.sinks.k2.hdfs.rollSize = 134217728 a1.sinks.k2.hdfs.rollCount = 0 ## 控制输出文件是原生文件。 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k2.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = lzop a1.sinks.k2.hdfs.codeC = lzop ## 拼装 a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1 a1.sources.r2.channels = c2 a1.sinks.k2.channel= c2 [hadoop@hadoop103 myagents]$
启动:flume-ng agent -c conf/ -n a1 -f myagents/f2.conf -Dflume.root.logger=DEBUG,console
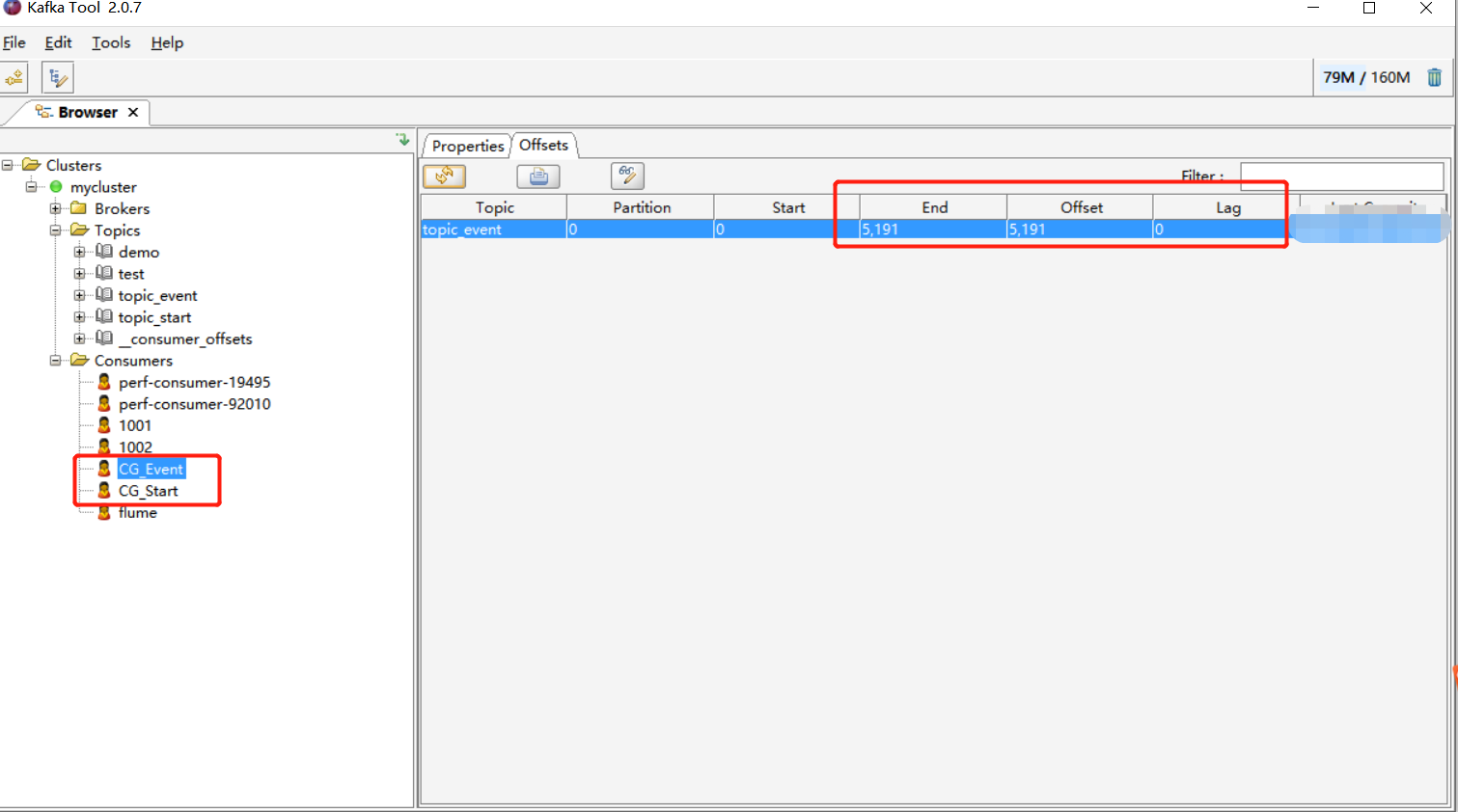
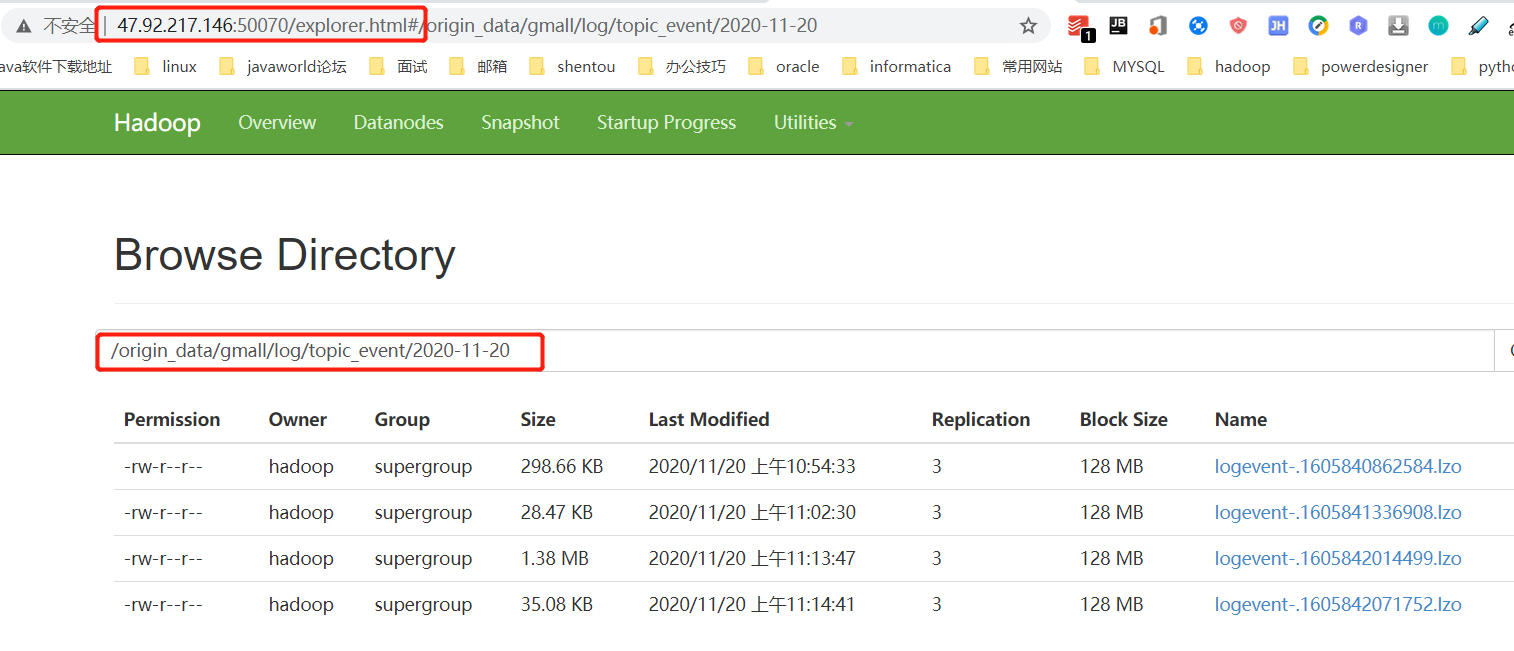
查看:
10.数据从kafaka到hdfs配置:启动脚本编写
因为第二次采集规划在104执行,所以需要把f2.conf 进行同步
[hadoop@hadoop103 flume]$ xsync myagents/ 要分发的文件目录是:/opt/module/flume/myagents ----------------hadoop102----------------- sending incremental file list myagents/ myagents/f1.conf myagents/f2.conf sent 2248 bytes received 78 bytes 1550.67 bytes/sec total size is 3552 speedup is 1.53 ----------------hadoop103----------------- sending incremental file list sent 77 bytes received 13 bytes 180.00 bytes/sec total size is 3552 speedup is 39.47 ----------------hadoop104----------------- sending incremental file list myagents/ myagents/f1.conf myagents/f2.conf sent 2248 bytes received 78 bytes 4652.00 bytes/sec total size is 3552 speedup is 1.53
启动脚本
[hadoop@hadoop103 bin]$ pwd
/home/hadoop/bin
[hadoop@hadoop103 bin]$ ll
total 32
-rwxrw-r-- 1 hadoop hadoop 232 Nov 9 12:10 ct
-rwxrw-r-- 1 hadoop hadoop 251 Nov 10 20:45 dt
-rwxrw-r-- 1 hadoop hadoop 562 Nov 20 12:17 f1
-rwxrw-r-- 1 hadoop hadoop 531 Nov 20 11:24 f2
-rwxrw-r-- 1 hadoop hadoop 333 Nov 10 22:14 hd
-rwxrw-r-- 1 hadoop hadoop 265 Nov 13 11:43 kf
-rwxrw-r-- 1 hadoop hadoop 225 Nov 10 20:28 lg
-rwxrw-r-- 1 hadoop hadoop 235 Nov 13 10:42 zk
[hadoop@hadoop103 bin]$ cat f2
#!/bin/bash
#1.start或者stop命令判断
if(($#!=1))
then
echo "请输入start|stop参数"
exit;
fi
#start和stop脚本编写
cmd=cmd
if [ $1 = start ]
then
cmd="nohup flume-ng agent -c $FLUME_HOME/conf/ -n a1 -f $FLUME_HOME/myagents/f2.conf -Dflume.root.logger=DEBUG
,console > /home/hadoop/log/f2.log 2>&1 &"elif [ $1 = stop ]
then
cmd="ps -ef|grep f2.conf |grep -v grep|awk -F ' ' '{print $2}'|xargs kill -9"
else
echo "请输入start|stop参数"
exit;
fi
#执行脚本,只在104上运行
ssh hadoop104 $cmd
[hadoop@hadoop103 bin]$
11.一键启动脚本编写
[hadoop@hadoop103 bin]$ cat onekeyboot
#!/bin/bash
#一键启动或者停止集群的脚本编写
#命令传入参数检测
if(($#!=1))
then
echo "请输入start|stop参数"
exit;
fi
#定义一个函数,用了计算kafka进程启动的个数
function countKafkaBrokers()
{
count=0
count=$(xcall jps|grep Kafka|wc -l)
return $count
}
#启动
if [ $1 = start ]
then
hd start
zk start
kf start
#kafka启动完成后,才能启动f1和f2
while [ 1 ]
do
countKafkaBrokers
if(($?==3))
then
break
fi
sleep 2s
done
f1 start
f2 start
xcall jps
exit;
elif [ $1 = stop ]
then
f1 stop
f2 stop
kf stop
#kafka停止完毕,才能停止zookeepser
while [ 1 ]
do
countKafkaBrokers
if(($?==0))
then
break
fi
sleep 2s
done
zk stop
hd stop
xcall jps
exit;
else
echo "请输入start|stop参数"
exit;
fi
[hadoop@hadoop103 bin]$