前述
写了一个基于MD5算法的文件监听程序,通过不同的文件能够生成不同的哈希函数,来实现实现判断文件夹中的文件的增加、修改、删除和过滤含有特定字符的文件名的文件。
需求说明
需要实现对一个文件夹下的文件的增加、修改和删除的监控, 一旦发生上述操作,则进行提示。可以选择过滤掉文件名中的特定字符和只监听文件名中含有特定字符的文件。
简述
- 首先,关于文件的增加、修改、删除的反馈,可以想到利用MD5等类似的加密算法,因为文件本身可以生成哈希值,只要文件内容或者文件名被修改过,就会生成和修改之前的哈希值不同的值,因此可以利用dict来存储,一个文件名对应一个哈希值来存储。其中增加和删除就对应一个新增加的键值对和一个减少的键值对,而修改则可以理解为删除了旧的文件、增加了一个新的文件。
MD5算法可以直接利用第三方的 hashlib 库来实现
1 m = hashlib.md5() 2 myFile = open(full_path, 'rb') 3 for line in myFile.readlines(): #以行为单位不断更新哈希值,避免文件过大导致一次产生大量开销 4 m.update(line) #最后可以得到整个文件的哈希值
- 第二,关于滤掉文件名中的特定字符和只监听文件名中含有特定字符的文件的功能,这个其实非常简单,只需要用 list 分别对需要过滤和必须存在字符串进行存储, 然后利用标志位和字符串的子串包含性进行判断就可以了,只有满足条件的文件可以产生哈希值,产生哈希值也就意味着被监听了。
判断字符串中是否含有字串最常用的方法是 in 和 string 中的 find 方法,这里就不再赘述,可以直接看下面的代码
- 第三,因为要同时监控多个文件夹,所以必须要利用到线程来处理,创建一个线程池来存储线程, 线程利用了 threading 库,并且实现一个线程类来处理线程的操作
class myListener(threading.Thread):
1 thread1 = myListener(mydir, json_list_include, json_list_exclude) #生成线程
说明
需要额外说明的一点是,在传输需要监听的文件夹、必须包含的字段以及过滤字段的时候,我这里是利用配置文件的形式来存储的。说到底,是利用 toml 格式的数据进行的传输,toml格式和 json格式相比,用户的可读性更强一些,为了便于博客展示,因此利用了 toml 格式
首先利用代码生成了一下toml格式的文件,以后再想用的话,程序打包之后,可以直接修改配置文件来实现对程序的控制。
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 # Author: JYRoooy
4 import collections
5 import json
6 import toml
7 if __name__ == '__main__':
8 myOrderDict = collections.OrderedDict
9 myOrderDict = {'dict':[{'path':'E:/testing', 'include':['log_'], 'exclude': ['.swp', '.swx', 'tmp']},{'path':'E:/tmp', 'include':['.record'], 'exclude': ['.tmp']}]}
10 myToml = toml.dump(myOrderDict, open('E:/python/code/PythonProject/tomlConfig.txt','w+'))
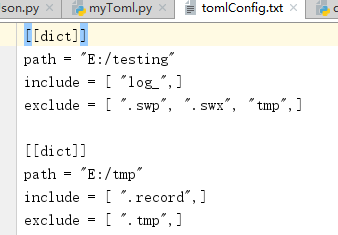
toml文件
格式说明, 一个 dict 对应一个监听的文件夹和需要 过滤(exculde) 和 含有(include) 的字段,解释一下,这里的字段只是文件名的字段,监控 E:/testing 目录下的文件,要包含 log_ 字段的文件,且不包含 .swp .swx .tmp 字段的文件, 并且监控 E:/tmp 目录下的文件,要包含 .record 字段的文件,且不包含 .tmp 的文件。
代码
完整程序的代码,具体解释可以看注释
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author: JYRoooy 4 import toml 5 import hashlib 6 import os 7 import sys 8 import time 9 import importlib 10 import threading 11 importlib.reload(sys) 12 13 class myListener(threading.Thread): 14 ''' 15 监听类 16 ''' 17 def __init__(self, input_dir, filt_in, filt_ex): #文件夹路径,必须包含的字符,必须过滤的字符 18 threading.Thread.__init__(self) 19 self.input_dir = input_dir 20 self.filt_in = filt_in 21 self.filt_ex = filt_ex 22 self.dict = {} #用来存储文件名和对应的哈希值 23 self.file_list = [] #存储每一次扫描时的文件的文件名 24 self.pop_list = [] #存储需要删除的文件名 25 26 def run(self): 27 while (1): #保证文件夹一直处于被监听的状态 28 for cur_dir, dirs, files in os.walk(self.input_dir): 29 if files != []: 30 self.file_list = [] 31 for each_file_1 in files: 32 each_file = each_file_1 33 if self.filt_in: #判断文件名中是否有必须存在的字段 34 flagone = 0 35 for i in range(len(self.filt_in)): 36 if self.filt_in[i] in each_file: 37 flagone += 1 38 if flagone == 0: 39 continue 40 41 if self.filt_ex: #判断文件名中是否有必须过滤掉的字段 42 flagtwo = 0 43 for i in range(len(self.filt_ex)): 44 if self.filt_ex[i] in each_file: 45 flagtwo = 1 46 if flagtwo==1: 47 continue 48 49 self.file_list.append(each_file) 50 full_path = os.path.join(cur_dir, each_file) 51 m = hashlib.md5() #实例化md5算法 52 53 myFile = open(full_path, 'rb') 54 55 for line in myFile.readlines(): 56 m.update(line) 57 if each_file not in self.dict.keys(): #如果当前的dict中没有这个文件,那么就添加进去 58 self.dict[each_file] = m.hexdigest() #生成哈希值 59 print('文件夹:' +cur_dir+ "中的文件名为:" + each_file + "的文件为新文件" + time.strftime('%Y-%m-%d %H:%M:%S', 60 time.localtime(time.time()))) 61 if each_file in self.dict.keys() and self.dict[each_file] != m.hexdigest(): #如果当前dict中有这个文件,但是哈希值不同,说明文件被修改过,则需要对字典进行更新 62 print('文件夹:' +cur_dir+ "中的文件名为:" + each_file + "的文件被修改于" + time.strftime('%Y-%m-%d %H:%M:%S', 63 time.localtime(time.time()))) 64 self.dict[each_file] = m.hexdigest() 65 myFile.close() 66 pop_list = [] 67 for i in self.dict.keys(): 68 if i not in self.file_list: #当字典中有不在当前文件名列表中时,说明文件已经被删除 69 print('文件夹:' +cur_dir+ '中的文件名为:' + i + "的文件已被删除!!!" + time.strftime('%Y-%m-%d %H:%M:%S', 70 time.localtime(time.time()))) 71 pop_list.append(i) 72 for i in pop_list: 73 self.dict.pop(i) 74 75 time.sleep(2) 76 77 if __name__ == '__main__': 78 threads = [] #用来存储线程的线程池 79 with open('E:/python/code/PythonProject/tomlConfig.txt','r+') as f: #读取toml格式的文件,并分解格式 80 mytoml = toml.load(f) 81 myList = mytoml['dict'] 82 for i in range(len(myList)): #因为可能同时需要监听多个文件夹,所以利用线程池处理多线程 83 json_list_include = [] 84 json_list_exclude = [] 85 mydir = myList[i]['path'] 86 for sublist in range(len(myList[i]['include'])): 87 json_list_include.append(myList[i]['include'][sublist]) 88 for sublist in range(len(myList[i]['exclude'])): 89 json_list_exclude.append(myList[i]['exclude'][sublist]) 90 thread1 = myListener(mydir, json_list_include, json_list_exclude) #生成线程 91 threads.append(thread1) 92 93 for t in threads: #开启所有线程 94 t.start();
运行结果
两个文件夹中的文件
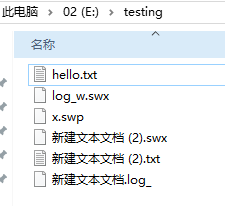
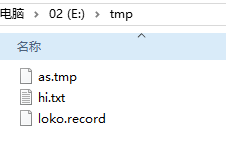
第一次运行程序, 可以看到已经按照过滤规则完成了过滤和监听

修改 loko.record 文件为 loko.re,再来看结果

可以看到已经完成了监听,因为 loko.re 文件,并符合监听的规则,所以不做出监听,而我们前面说过,一个修改相当于一个删除和一个新建操作,所以监听程序提示原文件被删除了
写在后面
其他的效果我就不一一展示了。
程序也没有实现很复杂的效果,代码已经上传 github -- https://github.com/JYRoy/MyFileListener
已经更新了Java版本的代码 https://www.cnblogs.com/jyroy/p/10575190.html
欢迎大佬们交流~