先思考一个问题:
看下面的表数据
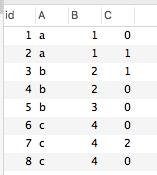
问题:现在需要在 A 和 B 相同的前提下对 C desc排序,然后拿到排序中不是第一个的数据?也就是说拿到下面的数据
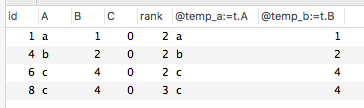
只用一条 SQL 实现:
1 select * from ( 2 select 3 t.*, 4 if(@temp_a=t.A and @temp_b=t.B,@rank:=@rank+1,@rank:=1) rank, 5 @temp_a:=t.A, 6 @temp_b:=t.B 7 from 8 (select * from test order by A asc,B asc,C desc) t, 9 (select @temp_a:=null,@temp_b:=null,@rank:=null) r 10 ) ret 11 where ret.rank > 1
此 SQL 的关键点就是使用标记变量和空表对数据打 tag,也就是上面的 rank 变量,然后不断迭代判断,对打完标记的表进行过滤即可,用处很多,适当扩展可以实现很多复杂的查询。