1. 序
词是句子组成的基本单元,不像英语句子已经分好词了,中文处理的第一步就是中文分词。
分词中面临的三大基本问题
- 分词规范
- 分词歧义
- 未登录词的识别
中文分词算法大概分为两大类
第一类:基于字符串匹配
即扫描字符串,如果发现字符串的子串和词相同,就算匹配。这类分词通常会加入一些启发式规则,比如“正向/反向最大匹配”, “长词优先” 等策略。
优点:速度快,都是O(n)时间复杂度,实现简单,效果尚可
缺点:就是对歧义和未登录词处理不好
案例:庖丁解牛分词器就是基于字符串匹配的分词。
- 歧义的例子很简单"长春市/长春/药店"、 "长春/市长/春药/店"
- 未登录词即词典中没有出现的词,当然也就处理不好
第二类:基于统计以及机器学习的分词方式
这类分词基于人工标注的词性和统计特征,对中文进行建模,即根据观测到的数据(标注好的语料)对模型参数进行估计,即训练。 在分词阶段再通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。常见的序列标注模型有HMM和CRF。
优点:很好处理歧义和未登录词问题,效果比基于字符串匹配效果好
缺点:需要大量的人工标注数据,较慢的分词速度
案例:Stanford Word Segmenter
2. 基于字符串匹配的中文分词(以前向最大匹配为例)

参考代码
def WordSeg(Inputfile, Outputfile): f = file(Inputfile) w = file(Outputfile, 'w') for line in f: line = line.strip().decode('utf-8') senList = [] newsenList = [] tmpword = '' for i in range(len(line)): if line[i] in StopWord: senList.append(tmpword) senList.append(line[i]) tmpword = '' else: tmpword += line[i] if i == len(line) - 1: senList.append(tmpword) #Pre for key in senList: if key in StopWord: newsenList.append(key) else: tmplist = PreSenSeg(key, span) for keyseg in tmplist: newsenList.append(keyseg) Prewriteline = '' for key in newsenList: Prewriteline = Prewriteline + key + ' ' w.write(Prewriteline.encode('utf-8') + ' ') f.close() w.close() def PreSenSeg(sen, span): post = span if len(sen) < span: post = len(sen) cur = 0 revlist = [] while 1: if cur >= len(sen): break s = re.search(u"^[0|1|2|3|4|5|6|7|8|9|uff11|uff12|uff13|uff14|uff15|uff16|uff17|uff18|uff19|uff10|u4e00|u4e8c|u4e09|u56db|u4e94|u516d|u4e03|u516b|u4e5d|u96f6|u5341|u767e|u5343|u4e07|u4ebf|u5146|uff2f]+", sen[cur:]) if s: if s.group() != '': revlist.append(s.group()) cur = cur + len(s.group()) post = cur + span if post > len(sen): post = len(sen) s = re.search(u"^[a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z|uff41|uff42|uff43|uff44|uff45|uff46|uff47|uff48|uff49|uff47|uff4b|uff4c|uff4d|uff4e|uff4f|uff50|uff51|uff52|uff53|uff54|uff55|uff56|uff57|uff58|uff59|uff5a|uff21|uff22|uff23|uff24|uff25|uff26|uff27|uff28|uff29|uff2a|uff2b|uff2c|uff2d|uff2e|uff2f|uff30|uff31|uff32|uff33|uff35|uff36|uff37|uff38|uff39|uff3a]+", sen[cur:]) if s: if s.group() != '': revlist.append(s.group()) cur = cur + len(s.group()) post = cur + span if post > len(sen): post = len(sen) if (WordDic.has_key(sen[cur:post])) or (cur + 1 == post): if sen[cur:post] != '': revlist.append(sen[cur:post]) cur = post post = post + span if post > len(sen): post = len(sen) else: post -= 1 return revlist
注意几点
- 首先根据标点切开分成小句子,标点绝对是分割的最佳标志。
- 句子中的数字(阿拉伯、汉字、阿拉伯+汉字。注意有十白千万亿)自动检测出来,不用再切割了。比如1998年=>1998 年
- 句子中的英文单词直接识别出来,不用分割了。比如:Happy New Year。
后向最大匹配与前向思路相同,只不过切分方向是从后往前。
3. 利用N-gram进行中文分词
语言模型是根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。语言模型与语言客观事实之间的关系,如同数学上的抽象直线与具体直线之间的关系。
N-gram
语言模型在自然语言处理中占有重要地位,尤其是在基于统计模型的NLP任务中得到了广泛的应用,目前主要采用的是n元语法模型(N-gram model),这种模型构建简单、直接,但同时也因为数据缺乏而必须采取平滑算法。
一个语言模型通常构建为字符串s的概率分布p(s),p(s)试图反映字符串s作为一个句子出现时的频率。例如一个人所说的100个句子中大约有一句是“OK”,那么可以任务P(OK)=0.01。而对于句子“the apple eat an chicken”,可以认为其概率为0,因为几乎没有人这么说。与语言学不同,语言模型与句子是否合乎语法没有关系。对于字串假设有l个基元(基元可以是字、词、短语等)组成句子,那么s = w1w2...wl,其概率计算公式为:
p(s)=p(w1)p(w2|w1)p(w3|w1w2).......p(wl|w1w2...pl-1)
把第i个词wi之前的词w1w2....wi-1成为wi的“历史”。随着历史长度的增加,不同的历史数目成指数增长。如果历史长度为i-1,那么就有Li-1种不同的历史(L为词汇集的大小),这样必须在所有历史的基础上得出产生第i个词的概率。这样不可能从训练数据中正确估计出(wi|w1w2...wi-1),并且很多历史不可能从训练数据中出现。其中一种比较实际的做法基于这样的假设:第n个词的出现只与前面n-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram(只与前一个词有关)和三元的Tri-Gram(只与前两个词有关)。
二元模型为例
p(s) = p(w1|<BEG>)p(w2|w1)p(w3|w2)*****p(wl|wl-1)p(<End>|wl)
其中p(wi|wi-1) = p(wi-1wi)/p(wi-1*)
前边已经利用前向最大匹配和后向最大匹配对句子进行了中文分词。为了提高分词的准确度,可以利用N-gram比较前向、后向哪个分词的得到的概率结果更大,就取相应的分词结果。
4. 小试牛刀
1. 前向后向中文分词
数据下载:待分词文件+对应答案+词典
代码


#! -*- coding:utf-8 -*- import sys import os import re #StopWordtmp = ['。', ',', '!', '?', ':', '“', '”', '‘', '’', '(', ')', '【', '】', '{', '}', '-', '-', '~', '[', ']', '〔', '〕', '.', '@', '¥', '•', '.'] StopWordtmp = [' ', u'u3000', u'x30fb', u'u3002', u'uff0c', u'uff01', u'uff1f', u'uff1a', u'u201c', u'u201d', u'u2018', u'u2019', u'uff08', u'uff09', u'u3010', u'u3011', u'uff5b', u'uff5d', u'-', u'uff0d', u'uff5e', u'uff3b', u'uff3d', u'u3014', u'u3015', u'uff0e', u'uff20', u'uffe5', u'u2022', u'.'] WordDic = {} StopWord = [] span = 16 def InitStopword(): for key in StopWordtmp: StopWord.append(key) def InitDic(Dicfile): f = file(Dicfile) for line in f: line = line.strip().decode('utf-8') WordDic[line] = 1; f.close() print len(WordDic) print "Dictionary has built down!" def WordSeg(Inputfile, Outputfile, outputfile2): f = file(Inputfile) w = file(Outputfile, 'w') w2 = file(Outputfile2, 'w') for line in f: line = line.strip().decode('utf-8') senList = [] newsenList = [] tmpword = '' for i in range(len(line)): if line[i] in StopWord: senList.append(tmpword) senList.append(line[i]) tmpword = '' else: tmpword += line[i] if i == len(line) - 1: senList.append(tmpword) #Pre for key in senList: if key in StopWord: newsenList.append(key) else: tmplist = PreSenSeg(key, span) for keyseg in tmplist: newsenList.append(keyseg) Prewriteline = '' for key in newsenList: Prewriteline = Prewriteline + key + ' ' #Post newsenList = [] for key in senList: if key in StopWord: newsenList.append(key) else: tmplist = PostSenSeg(key, span) for keyseg in tmplist: newsenList.append(keyseg) Postwriteline = '' for key in newsenList: Postwriteline = Postwriteline + key + ' ' Postwriteline = Postwriteline.strip(' ') w.write(Prewriteline.encode('utf-8') + ' ') w2.write(Postwriteline.encode('utf-8') + ' ') f.close() w.close() w2.close() def PreSenSeg(sen, span): post = span if len(sen) < span: post = len(sen) cur = 0 revlist = [] while 1: if cur >= len(sen): break s = re.search(u"^[0|1|2|3|4|5|6|7|8|9|uff11|uff12|uff13|uff14|uff15|uff16|uff17|uff18|uff19|uff10|u4e00|u4e8c|u4e09|u56db|u4e94|u516d|u4e03|u516b|u4e5d|u96f6|u5341|u767e|u5343|u4e07|u4ebf|u5146|uff2f]+", sen[cur:]) if s: if s.group() != '': revlist.append(s.group()) cur = cur + len(s.group()) post = cur + span if post > len(sen): post = len(sen) s = re.search(u"^[a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z|uff41|uff42|uff43|uff44|uff45|uff46|uff47|uff48|uff49|uff47|uff4b|uff4c|uff4d|uff4e|uff4f|uff50|uff51|uff52|uff53|uff54|uff55|uff56|uff57|uff58|uff59|uff5a|uff21|uff22|uff23|uff24|uff25|uff26|uff27|uff28|uff29|uff2a|uff2b|uff2c|uff2d|uff2e|uff2f|uff30|uff31|uff32|uff33|uff35|uff36|uff37|uff38|uff39|uff3a]+", sen[cur:]) if s: if s.group() != '': revlist.append(s.group()) cur = cur + len(s.group()) post = cur + span if post > len(sen): post = len(sen) if (WordDic.has_key(sen[cur:post])) or (cur + 1 == post): if sen[cur:post] != '': revlist.append(sen[cur:post]) cur = post post = post + span if post > len(sen): post = len(sen) else: post -= 1 return revlist def PostSenSeg(sen, span): cur = len(sen) pre = cur - span if pre < 0: pre = 0 revlist = [] while 1: if cur <= 0: break s = re.search(u"[0|1|2|3|4|5|6|7|8|9|uff11|uff12|uff13|uff14|uff15|uff16|uff17|uff18|uff19|uff10|u4e00|u4e8c|u4e09|u56db|u4e94|u516d|u4e03|u516b|u4e5d|u96f6|u5341|u767e|u5343|u4e07|u4ebf|u5146|uff2f]+$", sen[pre:cur]) if s: if s.group() != '': revlist.append(s.group()) cur = cur - len(s.group()) pre = cur - span if pre < 0: pre = 0 s = re.search(u"^[a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z|uff41|uff42|uff43|uff44|uff45|uff46|uff47|uff48|uff49|uff47|uff4b|uff4c|uff4d|uff4e|uff4f|uff50|uff51|uff52|uff53|uff54|uff55|uff56|uff57|uff58|uff59|uff5a|uff21|uff22|uff23|uff24|uff25|uff26|uff27|uff28|uff29|uff2a|uff2b|uff2c|uff2d|uff2e|uff2f|uff30|uff31|uff32|uff33|uff35|uff36|uff37|uff38|uff39|uff3a]+", sen[pre:cur]) if s: if s.group() != '': revlist.append(s.group()) cur = cur - len(s.group()) pre = cur - span if pre < 0: pre = 0 if (WordDic.has_key(sen[pre:cur])) or (cur - 1 == pre): if sen[pre:cur] != '': revlist.append(sen[pre:cur]) cur = pre pre = pre - span if pre < 0: pre = 0 else: pre += 1 return revlist[::-1] if __name__ == "__main__": if len(sys.argv) != 5: print("Usage: python wordseg.py Dicfile Inputfile Outfile") Dicfile = sys.argv[1] Inputfile = sys.argv[2] Outputfile = sys.argv[3] Outputfile2 = sys.argv[4] InitDic(Dicfile) InitStopword() WordSeg(Inputfile, Outputfile, Outputfile2)
对比前向后向结果

评测指标
正确率 = 正确识别的个体总数 / 识别出的个体总数
召回率 = 正确识别的个体总数 / 测试集中存在的个体总数
F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
评测程序
from __future__ import division import os import sys import linecache if __name__ == "__main__": if len(sys.argv) != 3: print "Usage: python evaluate.py inputfile goldfile" exit(0) infile = sys.argv[1] goldfile = sys.argv[2] count = 1 count_right = 0 count_split = 0 count_gold = 0 f = file(infile) for line in f: inlist = line.strip().decode('utf-8').split(' ') goldlist = linecache.getline(goldfile, count).strip().decode('utf-8').split(' ') count += 1 count_split += len(inlist) count_gold += len(goldlist) tmp_in = inlist tmp_gold = goldlist for key in tmp_in: if key in tmp_gold: count_right += 1 tmp_gold.remove(key) f.close() print "count_right", count_right print "count_gold", count_gold print "count_split", count_split p = count_right / count_split r = count_right / count_gold F = 2 * p * r /(p + r) print "p:", p print "r:", r print "F:", F
结果
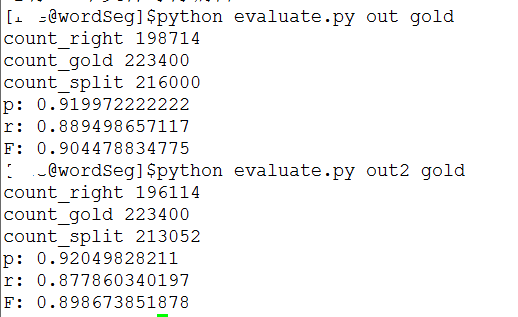
2. N-gram中文分词
数据下载:训练数据集+测试+答案+字典+评测程序+N-gram分词
参考代码
def WordSeg(Inputfile, Outputfile): f = file(Inputfile) w = file(Outputfile, 'w') dic_size = 0 for key in StatisticDic: for keys in StatisticDic[key]: dic_size += StatisticDic[key][keys] for line in f: line = line.strip().decode('utf-8') senList = [] newsenList = [] tmpword = '' for i in range(len(line)): if line[i] in StopWord: senList.append(tmpword) senList.append(line[i]) tmpword = '' else: tmpword += line[i] if i == len(line) - 1: senList.append(tmpword) #N-gram for key in senList: if key in StopWord: newsenList.append(key) else: Pretmplist = PreSenSeg(key, span) Posttmplist = PostSenSeg(key, span) tmp_pre = P(Pretmplist, dic_size) tmp_post = P(Posttmplist, dic_size) tmplist = [] if tmp_pre > tmp_post: tmplist = Pretmplist else: tmplist = Posttmplist #print 'tmplist', tmplist for keyseg in tmplist: newsenList.append(keyseg) writeline = '' for key in newsenList: writeline = writeline + key + ' ' writeline = writeline.strip(' ') w.write(writeline.encode('utf-8') + ' ') #break f.close() w.close()
运行
#! -*- coding:utf-8 -*- from __future__ import division import sys import os import re StopWordtmp = [' ', u'u3000',u'u3001', u'u300a', u'u300b', u'uff1b', u'uff02', u'u30fb', u'u25ce', u'x30fb', u'u3002', u'uff0c', u'uff01', u'uff1f', u'uff1a', u'u201c', u'u201d', u'u2018', u'u2019', u'uff08', u'uff09', u'u3010', u'u3011', u'uff5b', u'uff5d', u'-', u'uff0d', u'uff5e', u'uff3b', u'uff3d', u'u3014', u'u3015', u'uff0e', u'uff20', u'uffe5', u'u2022', u'.'] WordDic = {} StopWord = [] StatisticDic = {} span = 16 def InitStopword(): for key in StopWordtmp: StopWord.append(key) def InitDic(Dicfile): f = file(Dicfile) for line in f: line = line.strip().decode('utf-8') WordDic[line] = 1; f.close() print len(WordDic) print "Dictionary has built down!" def InitStatisticDic(StatisticDicfile): StatisticDic['<BEG>'] = {} f = file(StatisticDicfile) for line in f: chunk = line.strip().decode('utf-8').split(' ') if chunk[0] != '': if not StatisticDic['<BEG>'].has_key(chunk[0]): StatisticDic['<BEG>'][chunk[0]] = 1 else: StatisticDic['<BEG>'][chunk[0]] += 1 for i in range(len(chunk) - 1): if not StatisticDic.has_key(chunk[i]) and chunk[i] != '': StatisticDic[chunk[i]] = {} if chunk[i] != '': if not StatisticDic[chunk[i]].has_key(chunk[i+1]): StatisticDic[chunk[i]][chunk[i+1]] = 1 else: StatisticDic[chunk[i]][chunk[i+1]] += 1 if not StatisticDic.has_key(chunk[-1]) and chunk[-1] != '': StatisticDic[chunk[-1]] = {} if chunk[-1] != '': if not StatisticDic[chunk[-1]].has_key('<END>'): StatisticDic[chunk[-1]]['<END>'] = 1 else: StatisticDic[chunk[-1]]['<END>'] += 1 def WordSeg(Inputfile, Outputfile): f = file(Inputfile) w = file(Outputfile, 'w') dic_size = 0 for key in StatisticDic: for keys in StatisticDic[key]: dic_size += StatisticDic[key][keys] for line in f: line = line.strip().decode('utf-8') senList = [] newsenList = [] tmpword = '' for i in range(len(line)): if line[i] in StopWord: senList.append(tmpword) senList.append(line[i]) tmpword = '' else: tmpword += line[i] if i == len(line) - 1: senList.append(tmpword) #N-gram for key in senList: if key in StopWord: newsenList.append(key) else: Pretmplist = PreSenSeg(key, span) Posttmplist = PostSenSeg(key, span) tmp_pre = P(Pretmplist, dic_size) tmp_post = P(Posttmplist, dic_size) tmplist = [] if tmp_pre > tmp_post: tmplist = Pretmplist else: tmplist = Posttmplist #print 'tmplist', tmplist for keyseg in tmplist: newsenList.append(keyseg) writeline = '' for key in newsenList: writeline = writeline + key + ' ' writeline = writeline.strip(' ') w.write(writeline.encode('utf-8') + ' ') #break f.close() w.close() def P(tmplist, dic_size): rev = 1 if len(tmplist) < 1: return 0 ''' print 'tmplist', tmplist print "tmplist[0]", tmplist[0] print '-----------' ''' rev *= Pword(tmplist[0], '<BEG>', dic_size) rev *= Pword('<END>', tmplist[-1], dic_size) for i in range(len(tmplist)-1): rev *= Pword(tmplist[i+1], tmplist[i], dic_size) return rev def Pword(word1, word2, dic_size): #print 'word1:', word1 #print 'word2:', word2 div_up = 0 div_down = 0 if StatisticDic.has_key(word2): for key in StatisticDic[word2]: #print 'key:', key div_down += StatisticDic[word2][key] if key == word1: div_up = StatisticDic[word2][key] return (div_up+1) / (div_down + dic_size) def PreSenSeg(sen, span): post = span if len(sen) < span: post = len(sen) cur = 0 revlist = [] while 1: if cur >= len(sen): break s = re.search(u"^[0|1|2|3|4|5|6|7|8|9|uff11|uff12|uff13|uff14|uff15|uff16|uff17|uff18|uff19|uff10|u4e00|u4e8c|u4e09|u56db|u4e94|u516d|u4e03|u516b|u4e5d|u96f6|u5341|u767e|u5343|u4e07|u4ebf|u5146|uff2f]+", sen[cur:]) if s: if s.group() != '': revlist.append(s.group()) cur = cur + len(s.group()) post = cur + span if post > len(sen): post = len(sen) s = re.search(u"^[a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z|uff41|uff42|uff43|uff44|uff45|uff46|uff47|uff48|uff49|uff47|uff4b|uff4c|uff4d|uff4e|uff4f|uff50|uff51|uff52|uff53|uff54|uff55|uff56|uff57|uff58|uff59|uff5a|uff21|uff22|uff23|uff24|uff25|uff26|uff27|uff28|uff29|uff2a|uff2b|uff2c|uff2d|uff2e|uff2f|uff30|uff31|uff32|uff33|uff35|uff36|uff37|uff38|uff39|uff3a]+", sen[cur:]) if s: if s.group() != '': revlist.append(s.group()) cur = cur + len(s.group()) post = cur + span if post > len(sen): post = len(sen) if (WordDic.has_key(sen[cur:post])) or (cur + 1 == post): if sen[cur:post] != '': revlist.append(sen[cur:post]) cur = post post = post + span if post > len(sen): post = len(sen) else: post -= 1 return revlist def PostSenSeg(sen, span): cur = len(sen) pre = cur - span if pre < 0: pre = 0 revlist = [] while 1: if cur <= 0: break s = re.search(u"[0|1|2|3|4|5|6|7|8|9|uff11|uff12|uff13|uff14|uff15|uff16|uff17|uff18|uff19|uff10|u4e00|u4e8c|u4e09|u56db|u4e94|u516d|u4e03|u516b|u4e5d|u96f6|u5341|u767e|u5343|u4e07|u4ebf|u5146|uff2f]+$", sen[pre:cur]) if s: if s.group() != '': revlist.append(s.group()) cur = cur - len(s.group()) pre = cur - span if pre < 0: pre = 0 s = re.search(u"^[a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z|uff41|uff42|uff43|uff44|uff45|uff46|uff47|uff48|uff49|uff47|uff4b|uff4c|uff4d|uff4e|uff4f|uff50|uff51|uff52|uff53|uff54|uff55|uff56|uff57|uff58|uff59|uff5a|uff21|uff22|uff23|uff24|uff25|uff26|uff27|uff28|uff29|uff2a|uff2b|uff2c|uff2d|uff2e|uff2f|uff30|uff31|uff32|uff33|uff35|uff36|uff37|uff38|uff39|uff3a]+", sen[pre:cur]) if s: if s.group() != '': revlist.append(s.group()) cur = cur - len(s.group()) pre = cur - span if pre < 0: pre = 0 if (WordDic.has_key(sen[pre:cur])) or (cur - 1 == pre): if sen[pre:cur] != '': revlist.append(sen[pre:cur]) cur = pre pre = pre - span if pre < 0: pre = 0 else: pre += 1 return revlist[::-1] if __name__ == "__main__": if len(sys.argv) != 5: print("Usage: python wordseg.py Dicfile Inputfile Outfile") Dicfile = sys.argv[1] StatisticDicfile = sys.argv[2] Inputfile = sys.argv[3] Outputfile = sys.argv[4] InitDic(Dicfile) InitStatisticDic(StatisticDicfile) #print "Dic:", StatisticDic InitStopword() WordSeg(Inputfile, Outputfile)
分词结果

可以看出结果不如前向切分,但高于后向切分。原因是没有采取平滑策略,利用+1平滑后结果变为

结果超过前向、后向切分,说明有效。