package cn.itheima.lucene; import java.io.File; import java.util.ArrayList; import java.util.List; import org.apache.commons.io.FileUtils; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.TextField; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.LongField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; import org.junit.Test; import org.wltea.analyzer.lucene.IKAnalyzer; public class IndexManagerTest { @Test public void testIndexCreate() throws Exception{ //创建文档列表,保存多个Docuemnt List<Document> docList = new ArrayList<Document>(); //指定文件所在目录 File dir = new File("E:\01传智课程\黑28期0523\Lucene&Solr\01.参考资料\searchsource"); //循环文件夹取出文件 for(File file : dir.listFiles()){ //文件名称 String fileName = file.getName(); //文件内容 String fileContext = FileUtils.readFileToString(file); //文件大小 Long fileSize = FileUtils.sizeOf(file); //文档对象,文件系统中的一个文件就是一个Docuemnt对象 Document doc = new Document(); //第一个参数:域名 //第二个参数:域值 //第三个参数:是否存储,是为yes,不存储为no /*TextField nameFiled = new TextField("fileName", fileName, Store.YES); TextField contextFiled = new TextField("fileContext", fileContext, Store.YES); TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);*/ //是否分词:要,因为它要索引,并且它不是一个整体,分词有意义 //是否索引:要,因为要通过它来进行搜索 //是否存储:要,因为要直接在页面上显示 TextField nameFiled = new TextField("fileName", fileName, Store.YES); //是否分词: 要,因为要根据内容进行搜索,并且它分词有意义 //是否索引: 要,因为要根据它进行搜索 //是否存储: 可以要也可以不要,不存储搜索完内容就提取不出来 TextField contextFiled = new TextField("fileContext", fileContext, Store.NO); //是否分词: 要, 因为数字要对比,搜索文档的时候可以搜大小, lunene内部对数字进行了分词算法 //是否索引: 要, 因为要根据大小进行搜索 //是否存储: 要, 因为要显示文档大小 LongField sizeFiled = new LongField("fileSize", fileSize, Store.YES); //将所有的域都存入文档中 doc.add(nameFiled); doc.add(contextFiled); doc.add(sizeFiled); //将文档存入文档集合中 docList.add(doc); } //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 Analyzer analyzer = new IKAnalyzer(); //指定索引和文档存储的目录 Directory directory = FSDirectory.open(new File("E:\dic")); //创建写对象的初始化对象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建索引和文档写对象 IndexWriter indexWriter = new IndexWriter(directory, config); //将文档加入到索引和文档的写对象中 for(Document doc : docList){ indexWriter.addDocument(doc); } //提交 indexWriter.commit(); //关闭流 indexWriter.close(); } @Test public void testIndexDel() throws Exception{ //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 Analyzer analyzer = new IKAnalyzer(); //指定索引和文档存储的目录 Directory directory = FSDirectory.open(new File("E:\dic")); //创建写对象的初始化对象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建索引和文档写对象 IndexWriter indexWriter = new IndexWriter(directory, config); //删除所有 //indexWriter.deleteAll(); //根据名称进行删除 //Term词元,就是一个词, 第一个参数:域名, 第二个参数:要删除含有此关键词的数据 indexWriter.deleteDocuments(new Term("fileName", "apache")); //提交 indexWriter.commit(); //关闭 indexWriter.close(); } /** * 更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象 * 如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象 * @throws Exception */ @Test public void testIndexUpdate() throws Exception{ //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 Analyzer analyzer = new IKAnalyzer(); //指定索引和文档存储的目录 Directory directory = FSDirectory.open(new File("E:\dic")); //创建写对象的初始化对象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //创建索引和文档写对象 IndexWriter indexWriter = new IndexWriter(directory, config); //根据文件名称进行更新 Term term = new Term("fileName", "web"); //更新的对象 Document doc = new Document(); doc.add(new TextField("fileName", "xxxxxx", Store.YES)); doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO)); doc.add(new LongField("fileSize", 100L, Store.YES)); //更新 indexWriter.updateDocument(term, doc); //提交 indexWriter.commit(); //关闭 indexWriter.close(); } }
第一个test运行后会在指定目录生成文件。查看这些需要查看器
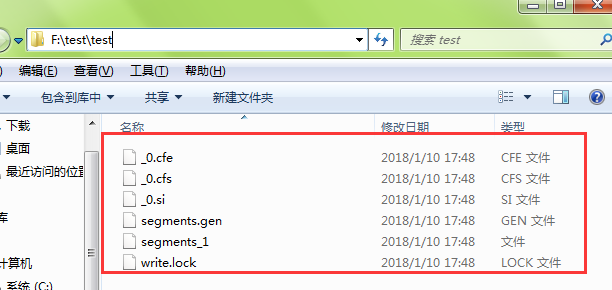
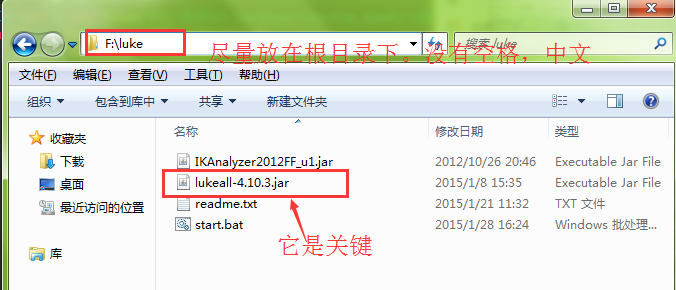
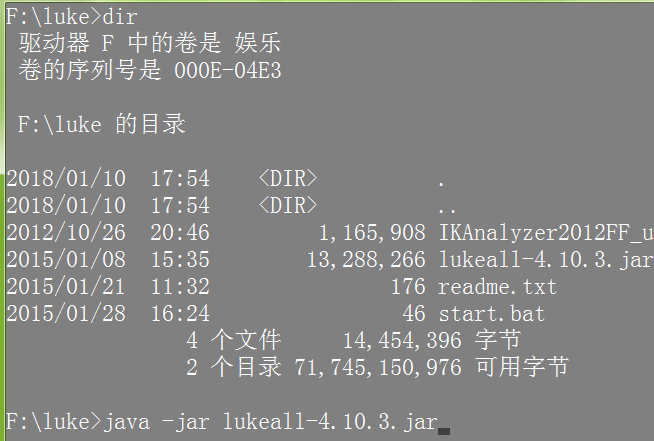
----------------------------------------------------------
package cn.itheima.lucene; import java.io.File; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.BooleanClause.Occur; import org.apache.lucene.search.BooleanQuery; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.MatchAllDocsQuery; import org.apache.lucene.search.NumericRangeQuery; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; import org.wltea.analyzer.lucene.IKAnalyzer; public class IndexSearchTest { @Test public void testIndexSearch() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器 //默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索 QueryParser queryParser = new QueryParser("fileContext", analyzer); //查询语法=域名:搜索的关键字 Query query = queryParser.parse("fileName:web"); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } } @Test public void testIndexTermQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //创建词元:就是词, Term term = new Term("fileName", "apache"); //使用TermQuery查询,根据term对象进行查询 TermQuery termQuery = new TermQuery(term); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(termQuery, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } } @Test public void testNumericRangeQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //根据数字范围查询 //查询文件大小,大于100 小于1000的文章 //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值 Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } } @Test public void testBooleanQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //布尔查询,就是可以根据多个条件组合进行查询 //文件名称包含apache的,并且文件大小大于等于100 小于等于1000字节的文章 BooleanQuery query = new BooleanQuery(); //根据数字范围查询 //查询文件大小,大于100 小于1000的文章 //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值 Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //创建词元:就是词, Term term = new Term("fileName", "apache"); //使用TermQuery查询,根据term对象进行查询 TermQuery termQuery = new TermQuery(term); //Occur是逻辑条件 //must相当于and关键字,是并且的意思 //should,相当于or关键字或者的意思 //must_not相当于not关键字, 非的意思 //注意:单独使用must_not 或者 独自使用must_not没有任何意义 query.add(termQuery, Occur.MUST); query.add(numericQuery, Occur.MUST); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } } @Test public void testMathAllQuery() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); //查询所有文档 MatchAllDocsQuery query = new MatchAllDocsQuery(); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } } @Test public void testMultiFieldQueryParser() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致) Analyzer analyzer = new IKAnalyzer(); String [] fields = {"fileName","fileContext"}; //从文件名称和文件内容中查询,只有含有apache的就查出来 MultiFieldQueryParser multiQuery = new MultiFieldQueryParser(fields, analyzer); //输入需要搜索的关键字 Query query = multiQuery.parse("apache"); //指定索引和文档的目录 Directory dir = FSDirectory.open(new File("E:\dic")); //索引和文档的读取对象 IndexReader indexReader = IndexReader.open(dir); //创建索引的搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 TopDocs topdocs = indexSearcher.search(query, 5); //一共搜索到多少条记录 System.out.println("=====count=====" + topdocs.totalHits); //从搜索结果对象中获取结果集 ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){ //获取docID int docID = scoreDoc.doc; //通过文档ID从硬盘中读取出对应的文档 Document document = indexReader.document(docID); //get域名可以取出值 打印 System.out.println("fileName:" + document.get("fileName")); System.out.println("fileSize:" + document.get("fileSize")); System.out.println("============================================================"); } } }
-----------------------------------------------下面总结----------------------------------------------------
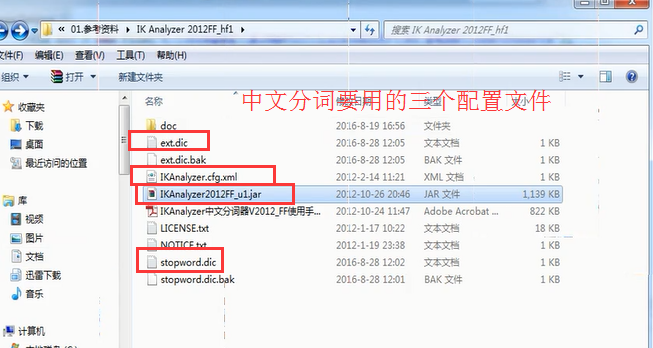
-------------------------------------------中文分词需要-------------------------------------------------