1.远程集群测试
import org.apache.spark.{SparkContext, SparkConf} import scala.math.random /** * 利用spark进行圆周率的计算 * Created by 汪本成 on 2016/6/10. */ object test { def main(args: Array[String]) {
//这一行重要,连接集群测试 //要测试的集群路径 //自己编译器要打的项目jar包(下面有如何打成jar包示例) val conf = new SparkConf().setAppName("SparkPai").setMaster("spark://192.168.1.116:7077").setJars(List("D:\IntelliJ IDEA 15.0.2\workplace\test\out\artifacts\test_jar\test.jar")) val sc = new SparkContext(conf) //分片数 val slices = if (args.length > 0) args(0).toInt else 2 //为避免溢出,n不超过int的最大值 val n = math.min(10000L*slices, Int.MaxValue).toInt //计数 val count = sc.parallelize(1 until n, slices).map{ lines => //小于1的随机数 val x = random*2 - 1 //小于1的随机数 val y = random*2 - 1 //点到圆心的的值,小于1计数一次,超出1就不计算 if (x*x + y*y < 1) 1 else 0 }.reduce(_+_) //汇总累加落入的圆中的次数 //count / n是概率,count落入圆中次的数,n是总次数; println("Pai is roughly " + 4.0 * count / n) sc.stop() } }
2.非集群,单机测试。
import org.apache.spark.sql.SparkSession import org.apache.spark.SparkConf object T2 { def main(args: Array[String]) { //单击不用集群就不用指定集群路径 //本地单击 val conf=new SparkConf().setAppName("CreateDF").setMaster("local[2]") val spark = SparkSession .builder().config(conf) .getOrCreate() // val df = spark.read.json("file:\C:\Users\Administrator\Desktop\spark-2.2.1\spark-2.2.1-bin-hadoop2.7\examples\src\main\resources\people.json") df.show() } }
3.给项目打包
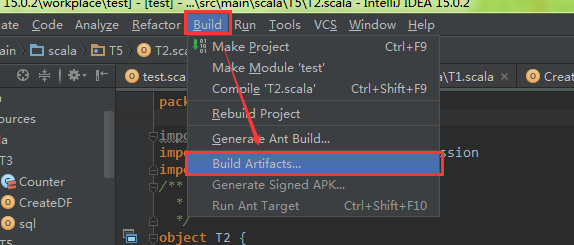
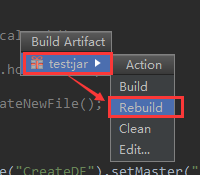
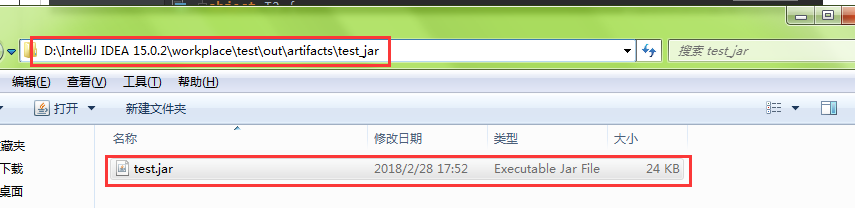
4.运行自己打的项目jar包(下面以 spark221.jar 为例)
//运行
spark-submit --class SQL spark221.jar
//或
spark-submit --class sql test.jar --master yarn

示例2:
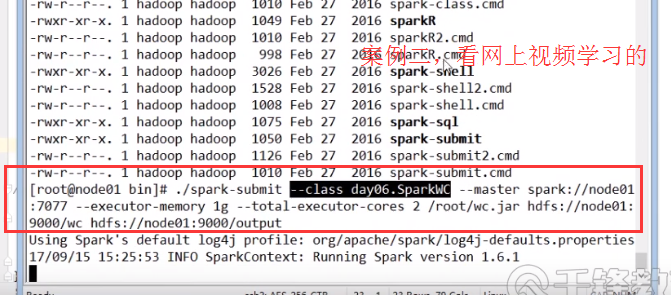
Ⅰ 打开sparkUI界面
1)首先启动打开一个spark-shell 就有了
[root@hadoop-2 bin]# spark-shell
然后访问浏览器地址:http://192.168.1.116:4040