损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:
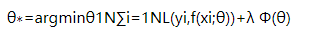
其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的Φ。
一、损失函数中正则化项L1、L2
正则化(Regularization)
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作-norm和-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项即为L1正则化项。
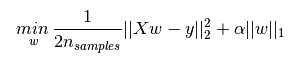
下图是Python中Ridge回归的损失函数,式中加号后面一项即为L2正则化项。
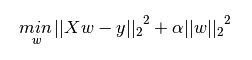
一般回归分析中回归表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量中各个元素的绝对值之和。
- L2正则化是指权值向量中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号)。
一般都会在正则化项之前添加一个系数,Python中用a表示,一些文章也用a表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
稀疏模型与特征选择
稀疏矩阵的概念
- 在矩阵中,若数值为0的元素数目远远多于非0元素的数目时,则称该矩阵为稀疏矩阵。与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。
- 稀疏矩阵其非零元素的个数远远小于零元素的个数,而且这些非零元素的分布也没有规律。
- 稀疏因子是用于描述稀疏矩阵的非零元素的比例情况。设一个n*m的稀疏矩阵A中有t个非零元素,则稀疏因子δδ的计算公式如下:δ=t/n∗m(当这个值小于等于0.05时,可以认为是稀疏矩阵)
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
L1和L2正则化的直观理解
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数:
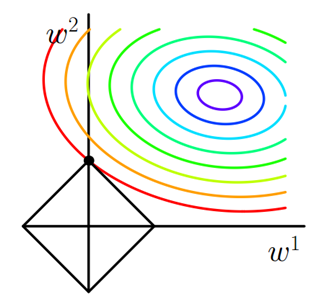
图1 L1正则化
图中线是的等值线,黑色方形是函数的图形。在图中,当等值线与图形首次相交的地方就是最优解。上图中与在的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是。可以直观想象,因为函数有很多『突出的角』(二维情况下四个,多维情况下更多),与这些角接触的机率会远大于与其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数,可以控制图形的大小。越小,的图形越大(上图中的黑色方框);越大,的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值中的可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:
图2 L2正则化
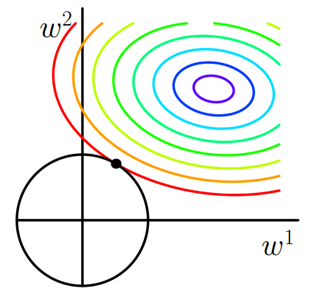
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此与相交时使得或等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化和过拟合
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
正则化参数的选择
L1正则化参数
通常越大的可以让代价函数在参数为0时取到最小值。下面是一个简单的例子,这个例子来自Quora上的问答。为了方便叙述,一些符号跟这篇帖子的符号保持一致。
假设有如下带L1正则化项的代价函数:
其中是要估计的参数,相当于上文中提到的以及. 注意到L1正则化在某些位置是不可导的,当足够大时可以使得在0时取到最小值。如下图:
图3 L1正则化参数的选择
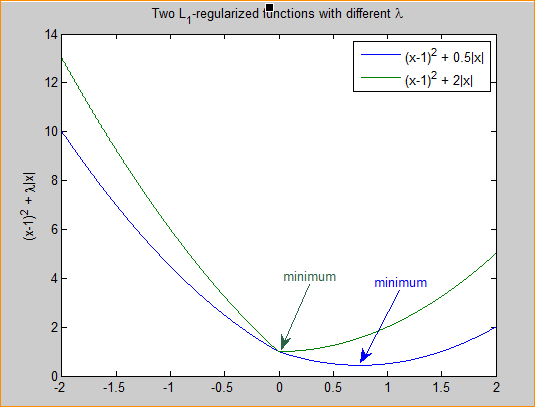
分别取和,可以看到越大的越容易使在0时取到最小值。
L2正则化参数
从公式5可以看到,越大,衰减得越快。另一个理解可以参考图2,越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
Reference
过拟合的解释:
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss2.html
正则化的解释:
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss1.html
正则化的解释:
http://blog.csdn.net/u012162613/article/details/44261657
正则化的数学解释(一些图来源于这里):
http://blog.csdn.net/zouxy09/article/details/24971995
二、损失函数中的 交叉熵、相对熵
在很多二分类问题中,特别是正负样本不均衡的分类问题中,常使用交叉熵作为loss对模型的参数求梯度进行更新,那为何交叉熵能作为损失函数呢,我也是带着这个问题去找解析的。
我们都知道,各种机器学习模型都是模拟输入的分布,使得模型输出的分布尽量与训练数据一致,最直观的就是MSE(均方误差,Mean squared deviation), 直接就是输出与输入的差值平方,尽量保证输入与输出相同。这种loss我们都能理解。
以下按照(1)熵的定义(2)交叉熵的定义 (3) 交叉熵的由来 (4)交叉熵作为loss的优势 作为主线来一步步理清思路。
1、熵
我们现在有了信息量的定义,而熵用来表示所有信息量的期望,即:
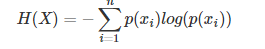
其中n代表所有的n种可能性.
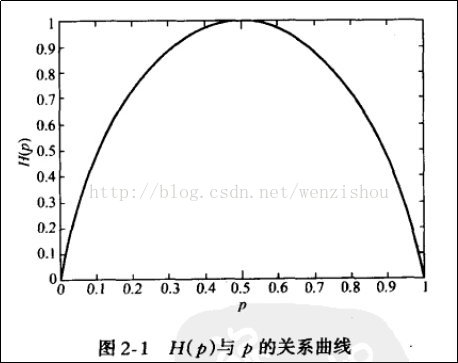
可以看出,一个事件的发生的概率离0.5越近,其熵就越大,概率为0或1就是确定性事件,不能为我们带信息量。也可以看作是一件事我们越难猜测是否会发生,它的信息熵就越大。
2、交叉熵
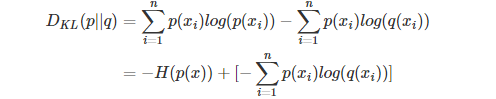
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵:
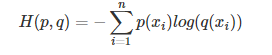
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度。
3、交叉熵的由来 相对熵
将上面的交叉熵的公式减去一个固定的值(H(p), 训练样本的熵,训练样本定,该值即为固定值),即训练样本分布p(x)的熵,可得如下:
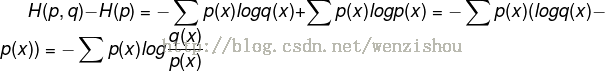
p(x)真实概率分布;q(x)由数据计算到的概率分布。使得q(x)逼近等于p(x)使得相对熵为0.
实际中 p(x)固定 故相对熵后半部分固定, 所以优化q(x)使交叉熵最小时相对熵也就最小。
最后得到的为相对熵或KL散度(Kullback-Leibler divergence), 亦可称为KL距离,是用于评判两个分布的差异程序,看到这里,应该明白为何交叉熵为何能作为loss了。即可以使得模型输出的分布尽量与训练样本的分布致,DKL的值越小,表示q分布和p分布越接近。
4、交叉熵作为loss的优势
模型训练的loss有很多,交叉熵作为loss有很多应用场景,其最大的好处我认为是可以避免梯度消散。