备注:本图片截图自“炼数成金”
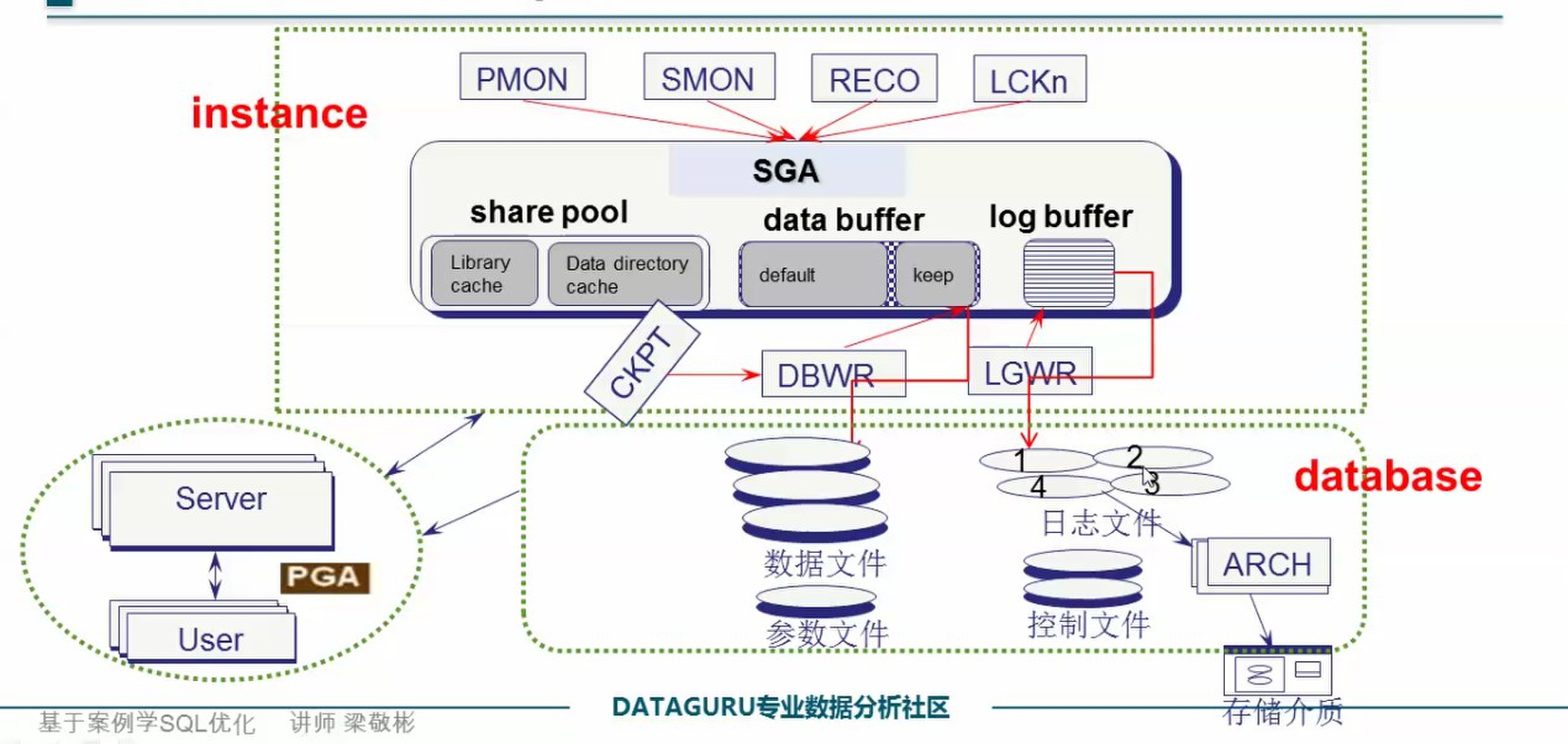
Oracle的体系结构分为内存结构、进程,磁盘文件。
内存结构分为SGA, PGA。SGA是系统全局区,是所有的用户共享区,PGA是某个用户的私有区。
SGA分为share pool, data buffer, log buffer.
share pool又分为library cache和Data Directory cache, 主要为优化器使用。当以sql语句提交后,会进行语法分析,语法分析通过,进行语义分析,在语义分析中,会进行sql语句的删除和整理, 比如select count(*) from A order by $1, 在语义分析中会将后面order by $1去除。 在语义分析中,优化器会根据share pool的信息基于开销选择一种执行计划,进行执行,同时把执行计划的hash值放入share pool中,第二次执行的时候, 会查询share pool中是否有该执行计划,有该执行计划,就不用重新生成执行计划(硬解析, 大概在一次小数据的查询中,80%的耗时会在硬解析中),而用存放的执行计划。
data buffer是数据的缓冲区,分为default和keep, 其中DBWR进程负责data buffer的填充数据,删除数据,以及由CKPT触发时向磁盘写入数据。当执行一个sql语句后,会留在回滚段中,还可以rollback, 如果再执行commit操作,则将操作确定,但是这时不一定会立即将数据写入磁盘中,而是在log buffer中写入操作日志,将log buffer中的数据写入log文件中,来达到安全保障. 顺便说一句,写日志文件是append操作,而写data文件很多是随机读写,所以写log文件的速度比写data文件快. 当读数据的时候, 首先查看data buffer中是否有目标数据,如果没有,则从磁盘中读入目标数据块.
log buffer是日志的缓冲区,当log buffer达到一定阀值时或者commit时,会像日志文件中写入日志数据。当日志文件1写满,就写2,依次下去,如果4写满,会重新写1,这时,如果归档模式打开,就会先向存储介质中归档1中的数据,如果归档模式没有打开,直接覆盖1. 值得注意的是,在几个日志文件进行切换或者归档的的时候,因为操作是按照先写入日志再进行读写操作的方式进行操作,log buffer不能向日志文件中写入数据,所以,操作不能继续进行,系统处于暂停状态。因此,为了避免log文件的频繁切换,我们适度增大文件的大小和个数,一般每个文件的大小设置为2G,log文件的个数为8.
PGA, 用户的排序等操作是在PGA中进行的。 可以根据物理服务器的大小, 通过设置SGA, PGA的参数来进行调优。