1. 编码的发展
# 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。 # 由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 # 但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312(GBK)编码,用来把中文编进去。 # 因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
2. 关于Unicode
2.1 用unicode表示各种编码
# Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。 # ASCII编码是1个字节,而Unicode编码通常是2个字节。 # 字母A用ASCII编码是十进制的65,二进制的01000001; # 字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的; # 汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。 # 你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001
2.2 unicode传输问题 # 如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本 基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。 # 所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间: # 在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。 # 比如: # (1)用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
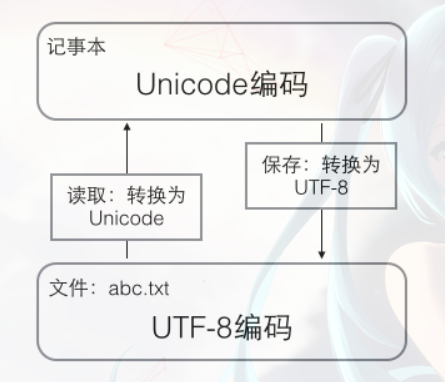
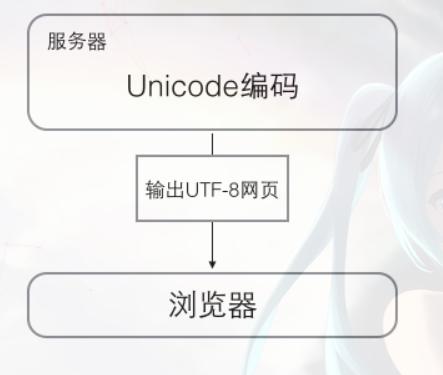
# (2)浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
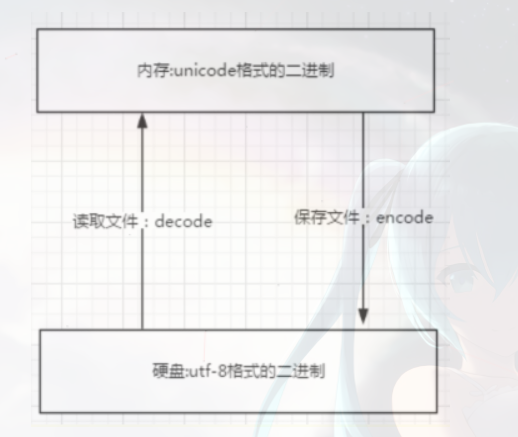
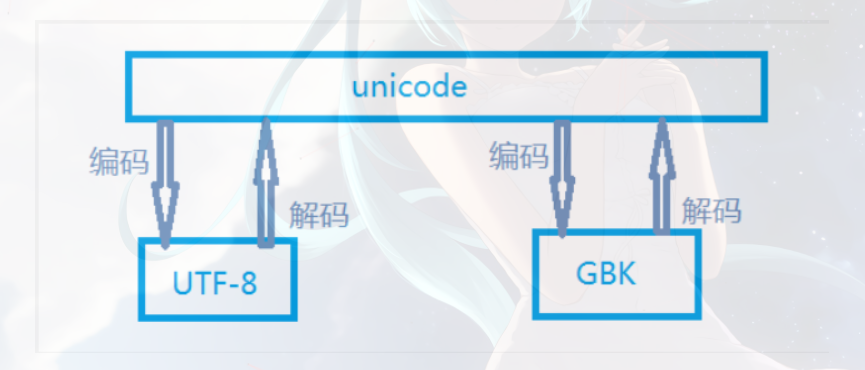
2.3 python3的编码细节 # python3默认的编码为unicode,utf-8可以看做是unicode的一个扩展集 # encode:指明要使用的编码,decode:指明当前编码的编码格式
如图:
2.4 编码总结 # (1) ASCII: # 不支持 中文 # 支持 英文 数字 符号 # 8位 一个字节 # (2) GBK 国标:(兼容ASCII) # 支持 中文,英文,数字,符号 # 英文 16位 一个字节 # 中文 16位 两个字节 # (3) unicode:(兼容ASCII) # 支持 中文,英文,数字,符号 # 英文 16位 二个字节 # 中文 16位 二个字节 # (4) UTF-8: 长度可变的unicode. 最少用8位 # 英文 8位 一个字节 # 中文 24位 三个字节
总结: python2 只能用ASCII python3中 程序运行阶段 使用的是unicode 显示所有的内容 bytes类型 传输和存储都是使用bytes pycharm 存储的时候默认是是使用utf-8
3. py2和py3的不同
3.1 编码&z字符串 # 字符串: # py2: # unicode v = u"root" 本质上用unicode存储(万国码) # (str / bytes) v = "root" 本质用字节存储 # py3: # str v = "root" 本质上用unicode存储(万国码) # bytes v = b"root" 本质上用字节存储 # 编码: # py2: # - ascii(默认编码) # 文件头可以修改: # -*- encoding:utf-8 -*- # py3: # - utf-8(默认编码) # 文件头可以修改: # -*- encoding:utf-8 -*-
3.2 继承 py2: 经典类/新式类 py3: 新式类 经典类和新式类的查找成员的顺序不一样. 经典类, 一条道走到黑(深度优先). 新式类, C3算法实现(python2.3更新时c3算法) 简答, 经典类, 一条道走到黑(深度优先) 新式类, 留个根.(科学c3算法) c3算法:(算出来之后可以用 类.__mro__验证一下) Foo + (C,D,F,G) + (G,D,G,W) + (I,G,D,G,W) FOO, 获取第一个表头 和 其他表位进行比较 不存在则拿走 如果存在, 则放弃,然后获取第二个表的表头再次和其他表的表尾进行比较 注意事项: super是遵循__mro__执行顺序
3.3 其他
- 编码
python2中默认使用ascii,python3中默认使用utf-8 - 范围 py2:range(一下子全部生成一个列表)/xrange(生成器:要一个拿一个) py3: range(生成器,要一个那一个个,等同于py2的xrange) - 输入 py2: v1 = raw_input('请输入用户名:') py3: v2 = input('请输入用户名:') - 打印 py2: print 'xx' py3: print(123)
4. windows终端显示的字符编码
# pycharm进入File --> Settings --> Editor --> Files Encodings --> 有Global ncoding和Project Encoding # Global ncoding: 指的是代码的默认编码格式, 如果在代码开头指定了,那么就用指定的编码 # Project Encoding: 我测试出来的是,它指的是字符显示的编码格式 import os os.system('dir') ������ D �еľ��� software ������к��� D657-2442 D:pythonprojectday28 ��Ŀ¼ 2019/10/11 21:46 <DIR> . 2019/10/11 21:46 <DIR> .. 2019/10/04 09:16 89 01�γ̴�� 2019/10/11 17:34 <DIR> 02�ϴ���ҵ 2019/10/11 21:46 51 02������ϸ.py 2019/10/11 21:36 668 ͨ��os.system������������.py 3 ���ļ� 808 �ֽ� 3 ��Ŀ¼ 319,833,575,424 �����ֽ� # 比如os.system('dir')为什么在pycharm中显示乱码呢? # 个人理解: 从终端出来的结果,windows默认的是gbk编码,所以解码也要用gbk
注意: 在windows终端编码为gbk,linux是UTF-8.