实验方式:尝试以不同方式创建超大号二维数组
测试代码:
#include <iostream>
using namespace std;
const int maxn=1000000;
class C{
int arr[maxn];
};
//int a[maxn]; 全局大数组
//C a; 含大数组的全局对象
int main(){
//int a[maxn]; 局部大数组
//C a; 含大数组的局部对象
//C a=*new C; 通过new创建的含大数组的对象
//C* a=new C; 通过new创建的指向含大数组的对象的指针
cout<<"hello";
return 0;
}
结果:
全局大数组:正常
含大数组的全局对象:正常
局部大数组:段错误
含大数组的局部对象:段错误
通过new创建的含大数组的对象 :段错误
通过new创建的指向含大数组的对象的指针 :正常
分析:C++中可能存在像java一样的堆栈内存机制,对于不同作用域的变量有不同内存管理策略
知识导入:
这篇文章讲的真是太好了:
关于堆栈的讲解(我见过的最经典的)
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区—常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
在WINDOWS下,栈的大小是2M或4M
变量类型+变量名出来的变量都在栈里,new出来的内存都在堆里,全局变量有自己的地儿。栈内存有限,少在栈上开大数组。
达成成就:
Stack Overflow
原写于2019年05月31日 21:38:43
2020.7.13更新
过去这一年我学了汇编语言、操作系统,又读完了《CSAPP》,对内存布局又有了新的理解。对于一个程序来说,它的内存布局可以概括为一张图:
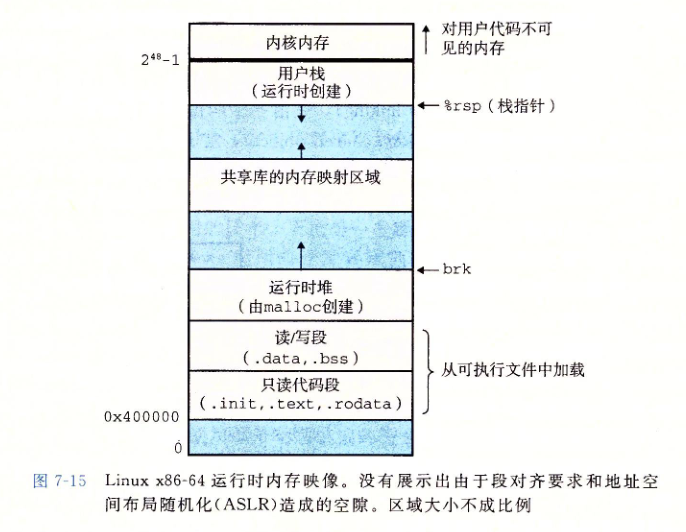
逐个解释一下:
- 内核内存:操作系统内核的代码和数据,无法直接访问这块内存。注意使用各种操作系统提供的函数直接不是访问操作系统的代码,而是通过“中断机制”将控制权暂时交给了操作系统,再由操作系统执行对应的例程,执行完毕后再将控制权交还给用户程序。
- 用户栈:存放了函数内定义的临时变量,传给函数的参数,以及函数的调用栈。所谓的函数的调用栈,上个图就是:
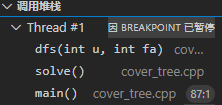
在这幅图里main调用了solve调用了dfs,这一层层嵌套的信息就储存在用户栈中。我们常讲的栈溢出、爆栈、stack over flow指的就是临时变量占内存太多或函数嵌套调用过多,同时用户栈的内存空间又太小,导致了内存溢出。
- 共享库的内存映射区域:我们以快速排序函数qsort()为例,如果每个要用qsort的用户程序都在自己的代码里嵌入qsort的代码就造成了重复,是一种浪费行为。为了节省空间操作系统只在内存中存放一份qsort的代码,对于每个需要调用qsort的程序,都在他们的内存布局里添加一个对应的“映射”,类似于只添加了一个快捷方式,并不占用实际空间。
- 运行时堆:所有通过malloc()函数、new关键字等等方式动态分配的内存都在这一区域。
- 读写段:包括了可读可写的全局变量和用static定义的变量,其中.data指初始化完成的,.bss指初始化未完成的
- 只读代码段:.init指操作系统初始化程序时用到的一段小函数,.text指程序的代码,只能读不能修改,.rodata指程序中定义的各种常量,典型的如提前定义好的字符串常量。
引申阅读:内存中的堆和栈到底是什么 - 简书
参考内容:《深入理解计算机系统 第三版》链接器相关章节