接下来我们来看下总结点
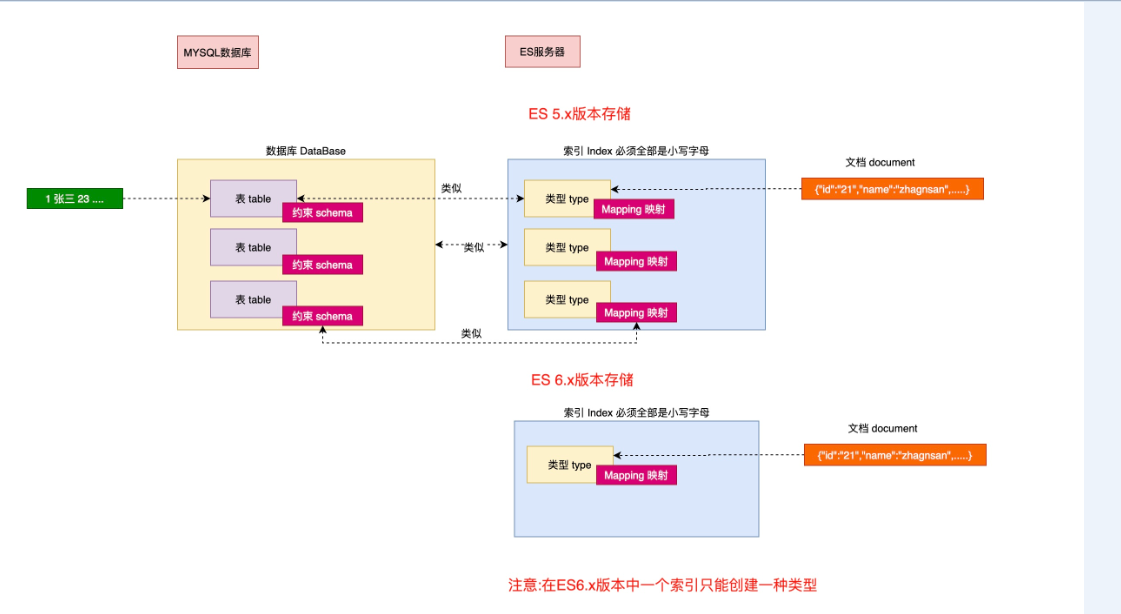
1、数据库中的database 对应es中的索引
2、数据库中的table表,对于es中的type
3、es中的表结构scheme,对于es中的mapping
4、e中的表中某条具体的策略,对应es中的某个文档
如
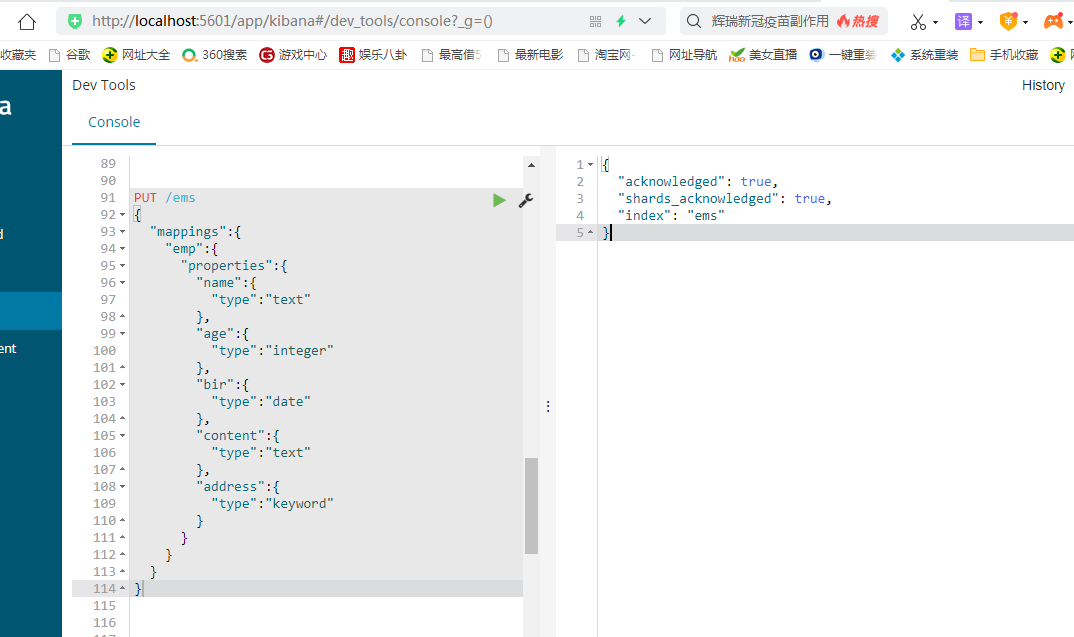
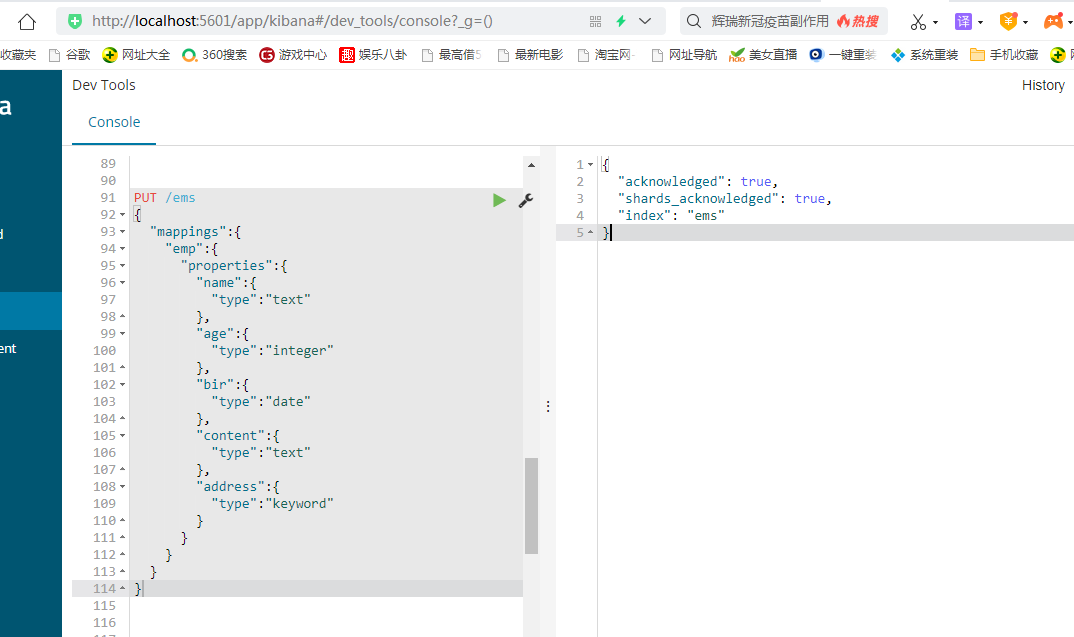
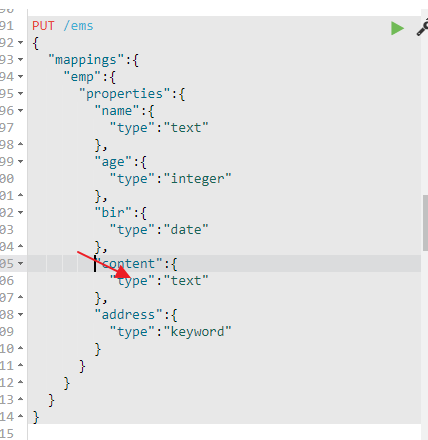
1.删除索引 DELETE /ems 2.创建索引并指定类型 PUT /ems { "mappings":{ "emp":{ "properties":{ "name":{ "type":"text" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } } 3.插入测试数据 PUT /ems/emp/_bulk {"index":{}} {"name":"小黑","age":23,"bir":"2012-12-12","content":"为开发团队选择一款优秀的MVC框架是件难事儿,在众多可行的方案中决择需要很高的经验和水平","address":"北京"} {"index":{}} {"name":"王小黑","age":24,"bir":"2012-12-12","content":"Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring 模块构建在核心容器之上,核心容器定义了创建、配置和管理 bean 的方式","address":"上海"} {"index":{}} {"name":"张小五","age":8,"bir":"2012-12-12","content":"Spring Cloud 作为Java 语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。Spring Cloud 的组件非常多,涉及微服务的方方面面,井在开源社区Spring 和Netflix 、Pivotal 两大公司的推动下越来越完善","address":"无锡"} {"index":{}} {"name":"win7","age":9,"bir":"2012-12-12","content":"Spring的目标是致力于全方位的简化Java开发。 这势必引出更多的解释, Spring是如何简化Java开发的?","address":"南京"} {"index":{}} {"name":"梅超风","age":43,"bir":"2012-12-12","content":"Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API","address":"杭州"} {"index":{}} {"name":"张无忌","age":59,"bir":"2012-12-12","content":"ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口","address":"北京"}
上面这些命令是在kibana中实现的
es测试的时候,在本地的windows环境上面一般需要设置对于的磁盘需要设置阈值
可以在kibana调整es磁盘水平线,即磁盘空间占用情况和分片的情况。
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation.disk.watermark.high": "95%", "allocation.disk.watermark.low": "90%" } } } }
es中的查询分为下面的两种类型
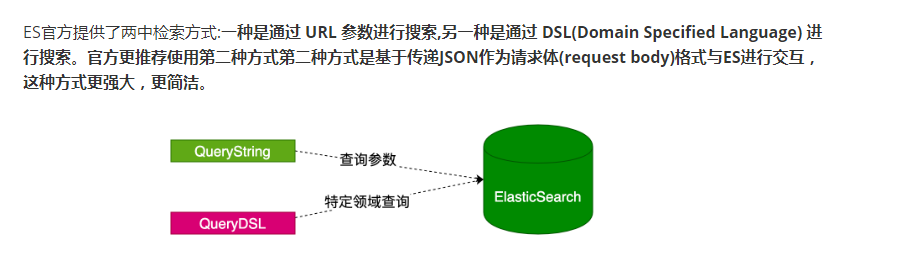
一种是querystring:
如
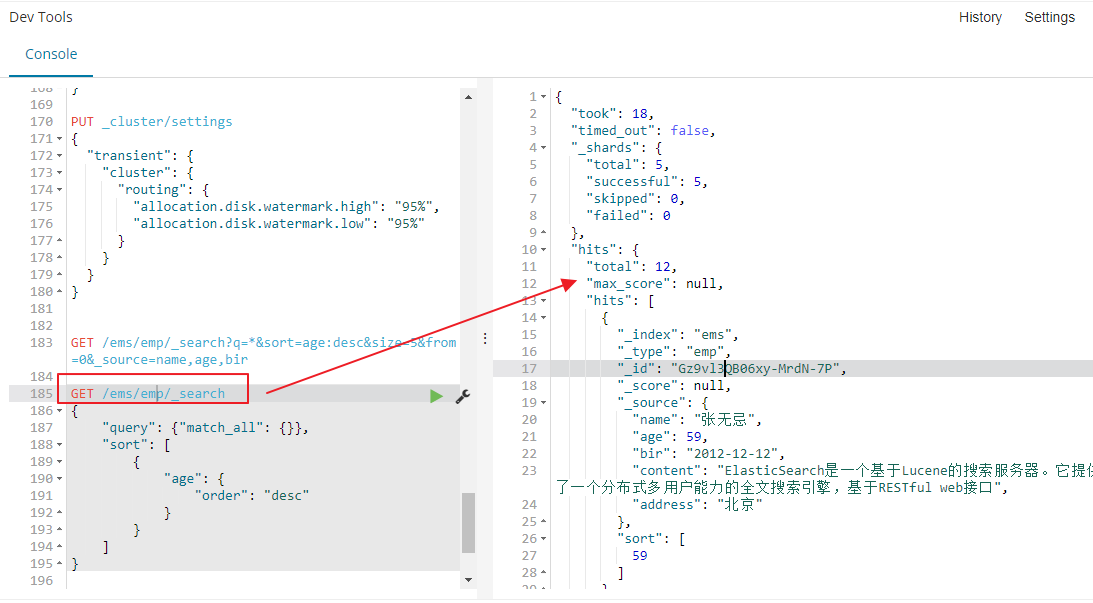
GET /ems/emp/_search?q=*&sort=age:asc**
> _search 搜索的API
> q=* 匹配所有文档
> sort 以结果中的指定字段排序
GET /ems/emp/_search?q=*&sort=age:desc&size=5&from=0&_source=name,age,bir

另外一种是特殊领域的查询另一种是通过 DSL(Domain Specified Language)
GET /ems/emp/_search { "query": {"match_all": {}}, "sort": [ { "age": { "order": "desc" } } ] }
**term 关键字**: 用来使用关键词查询,这里需要重点详细解释下

上面中我们的name是,text类型,
在es中,string类型在es5.*分为text和keyword。 text文件存储的时候是要被分词的,整个字符串根据一定规则分解成一个个小写的term,keyword类似es2.3中not_analyzed的情况。
我们来说明下上面创建的name为text类型: "name": "张小五", 中文张小五会被分词为张、小 、五三个字存储到倒排索引中供大家查询
上面的address为keyword类型,keyword不会被分词存储,例如"address": "无锡",整个无锡不会被分词存储到倒排索引中
NOTE1: 通过使用term查询得知ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词**。
**NOTE2: 通过使用term查询得知,在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词**,**只有text类型分词**。
除了keyword之后,es中的date long double等类型都不会被分词存储
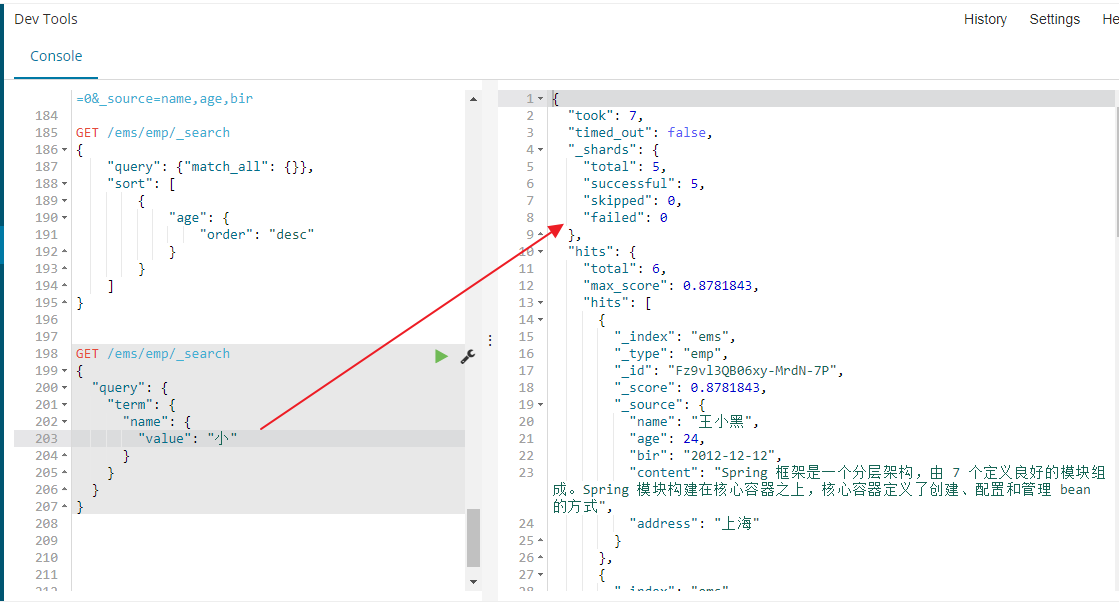
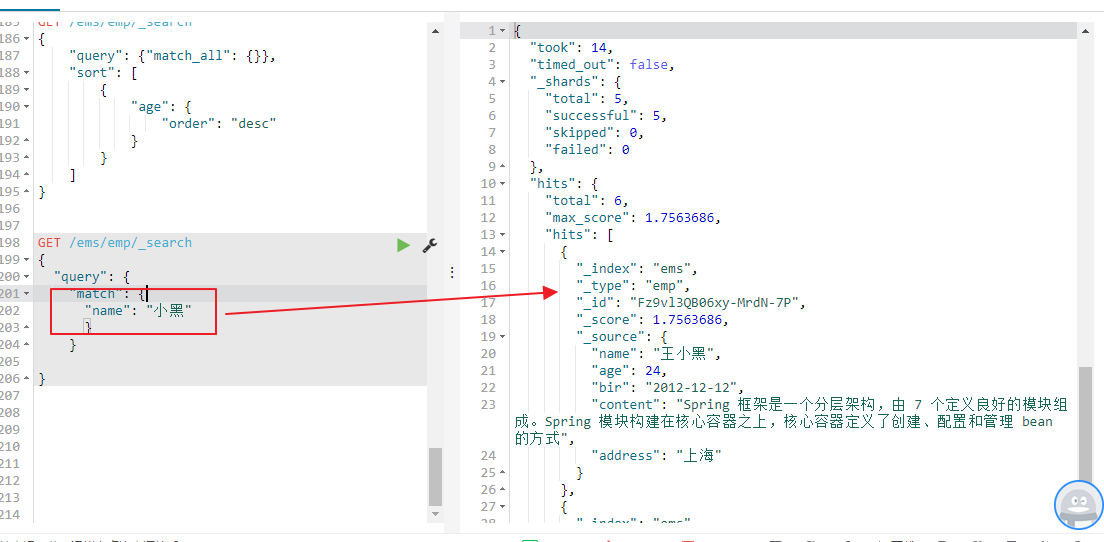
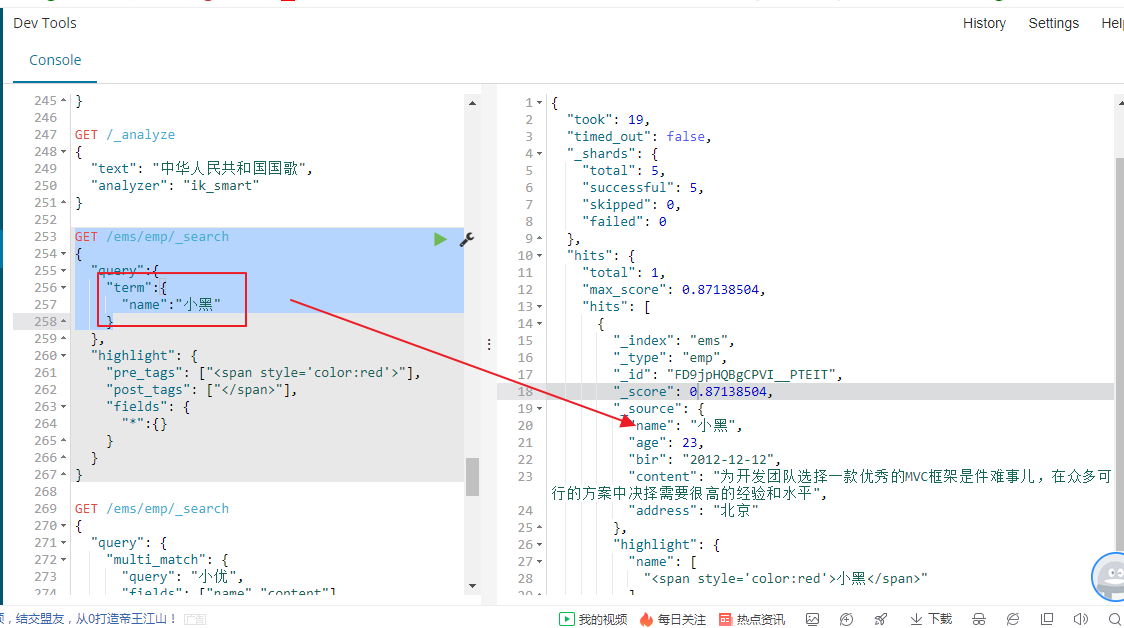
使用term查询的时候,例如我们name里面我们有个名字是小黑,我们去搜索,发现搜索不到任何数据,这里es对于text的因为做了分词处理,在name中中文张小黑,张小黑分词分词了张、小和黑三个词,你使用小黑去匹配当然查询不到,term是确切查询,
必须要匹配到小黑才能查询得到,term不会将搜索的小黑去做分词再去查询,这里term是精确查询。所以返回结果为空使用小这一个字去查询就能够查询得到

接下来看看term对keyword的支持了,上面中address的类型为keyword类型,那么term查询keyword会不会做分词了查询了,我们发现这里是可以查询得到数据的
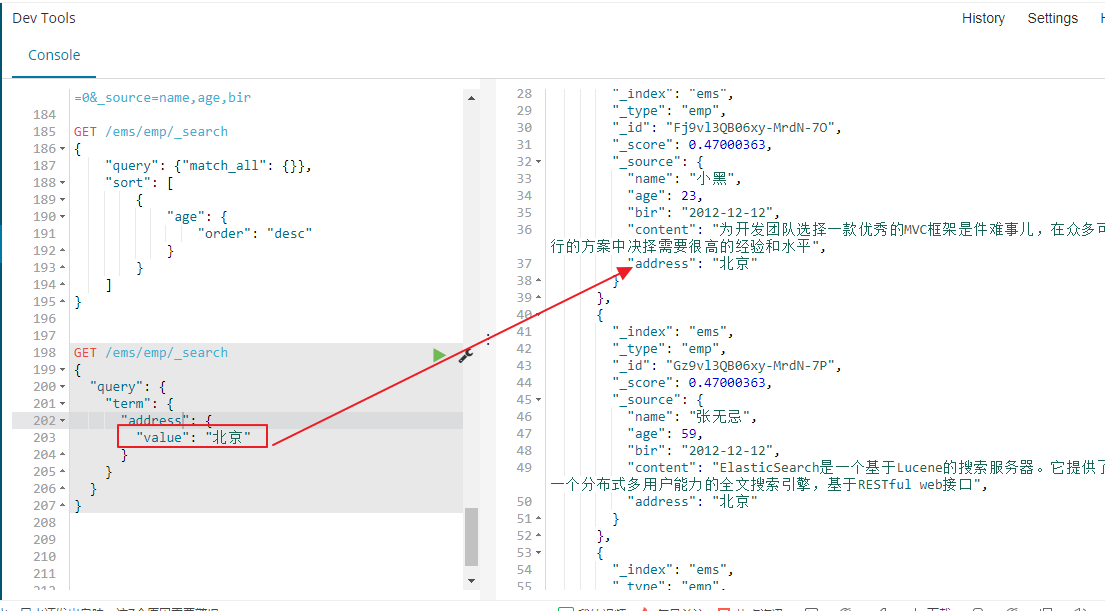
结论:
NOTE1: 通过使用term查询得知ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词**。
**NOTE2: 通过使用term查询得知,在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词**,**只有text类型分词**。
除了term查询之外,es中还提供了match查询,二者的区别在那里了
term是确切查询, 必须要匹配到小黑才能查询得到,term不会将搜索的字段filed小黑去做分词分为小和黑再去查询,这里term是精确查询
但是match的话会将会将搜索的字段filed小黑去做分词分为小和黑再去查询,这里match是模糊查询,所有使用macth去查询name为小黑就能够查询得到返回的数据
这里之前困扰了我很久,现在重要弄清楚了,term与match可以看这篇文章,相当的经典呀
http://www.dczou.com/viemall/684.html
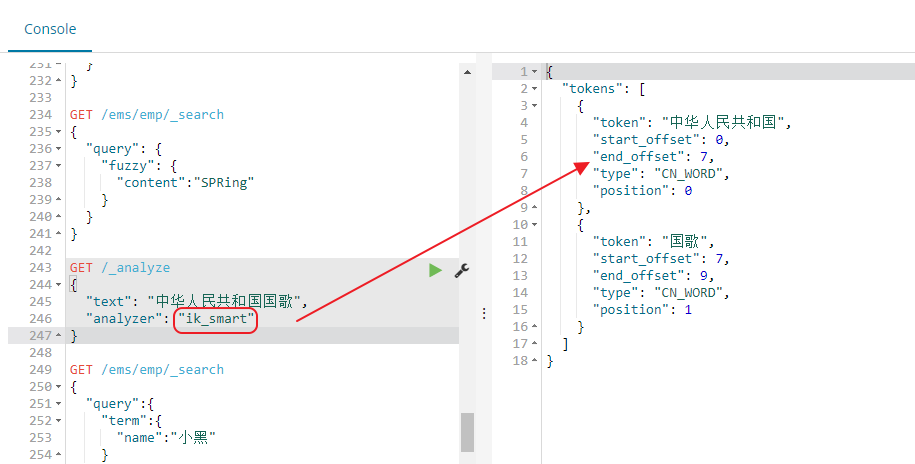
es中的fuzzy搜索
搜索的时候,可能输入的搜索文本会出现误拼写的情况
fuzzy搜索技术 --> 自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据
我们举例来搜下下
conteent为text类型存储的时候会采用分词存储
这里先说一个重要的的点
"content": "Spring Cloud 作为Java 语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。Spring Cloud 的组件非常多,涉及微服务的方方面面,井在开源社区Spring 和Netflix 、Pivotal 两大公司的推动下越来越完善",
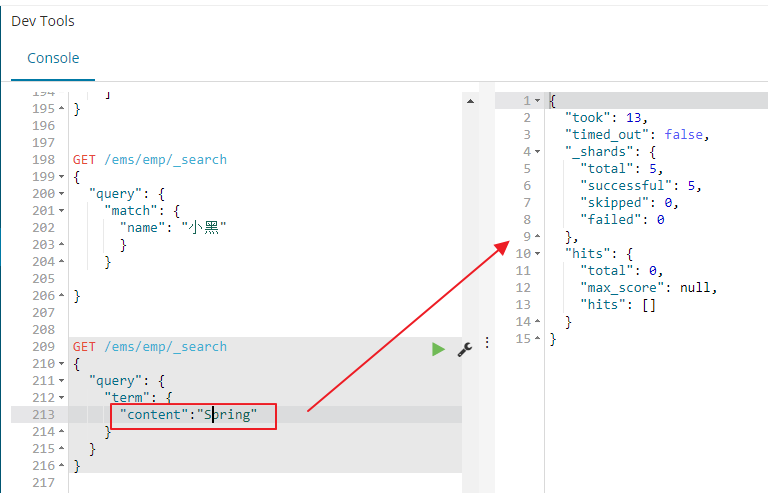
对于分词这里es默认会将大写字母写成小写字母
例如Spring Cloud,分词之后索引变成了spring cloud,索引当你使用term精确查询下使用Spring面案例的时候,是查询不到数据的
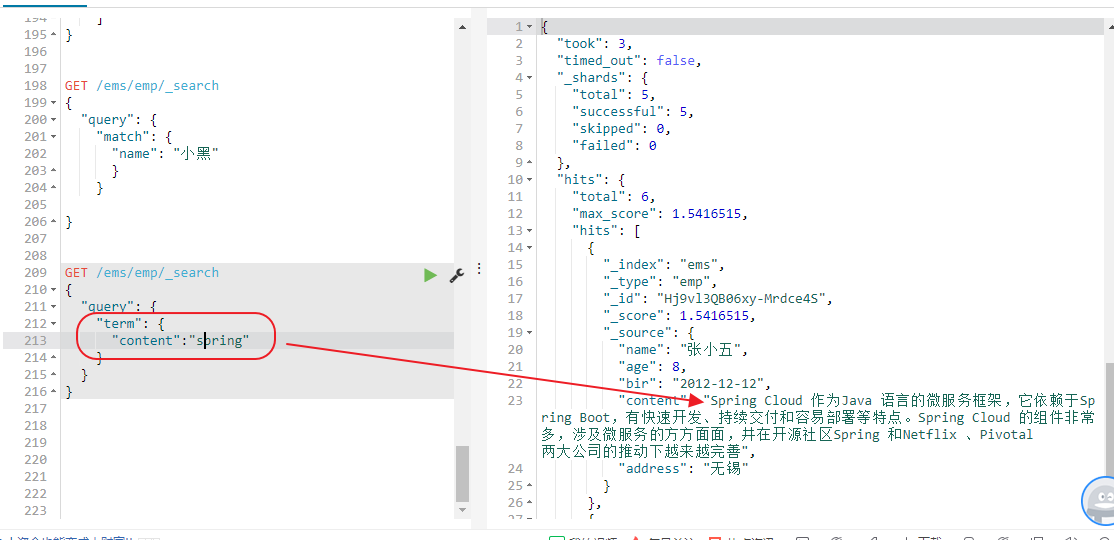
当你使用下面的小写的spring是可以查询到的
这里需要特别的注意下
对于match来说,会对查询的field字段做分词,当查询大写的Spring的时候,会将大写的Spring转化为小写的Spring,所以去查询content的时候,能够查询得到数据
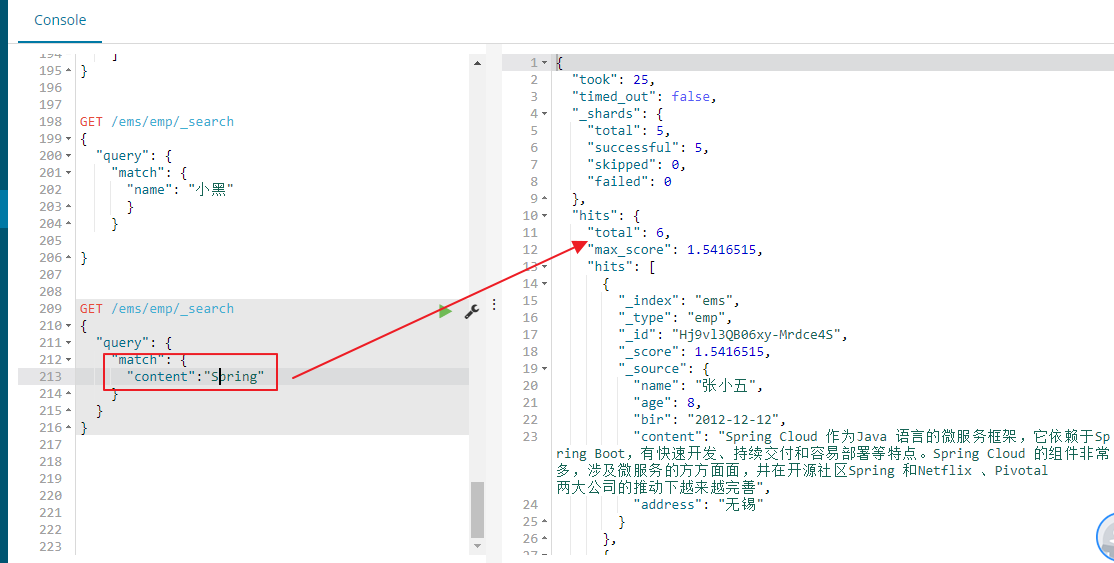
搜索的时候,可能输入的搜索文本会出现误拼写的情况
fuzzy搜索技术 --> 自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据
GET /ems/emp/_search
{
"query": {
"fuzzy": {
"content":"spring"
}
}
}
fuzzy 模糊查询 最大模糊错误 必须在0-2之间
# 搜索关键词长度为 2 不允许存在模糊 0
# 搜索关键词长度为3-5 允许一次模糊 0 1
# 搜索关键词长度大于5 允许最大2模糊
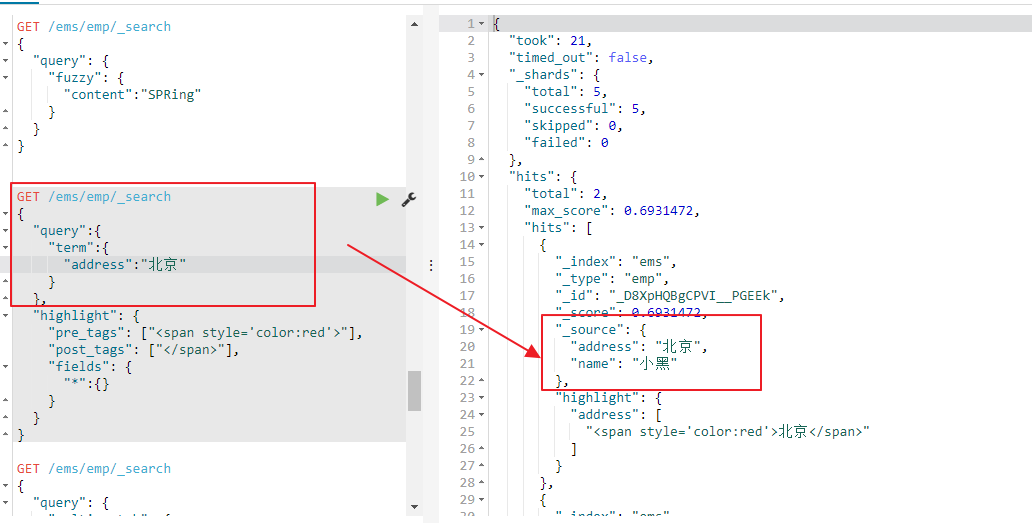
现在搜索的content的内容为Spring Cloud 作为Java 语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。Spring Cloud 的组件非常多,涉及微服务的方方面面,井在开源社区Spring 和Netflix 、Pivotal 两大公司的推动下越来越完善,长度大于5,允许最大2个模糊,啥意思,我们来验证下

现在content存储的时候进行了分词,Spring Cloud被分词为了小写的spring clould ,我们使用fuzzy查询的时候我们将spring写成了xxring,写错了2个字母,这里因为content的内容大于了5,所以可以默认允许2个写错,所以上面我们能够查询到对于的数据
我们来看下面的列子,fuzzy查询的时候是不会将field是不会对查询的字段进行分词的,下面查询的是SPRing,前三个字母都写成大小,在索引中存储的是小写的spring ,相当于错了3个字母,所以这里查询不到任何数据

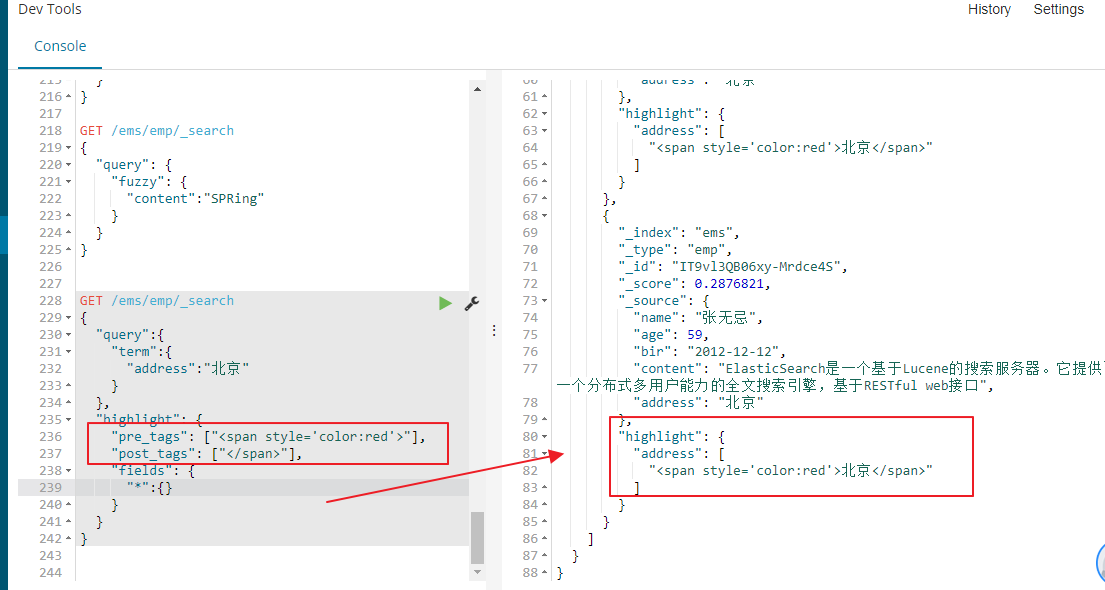
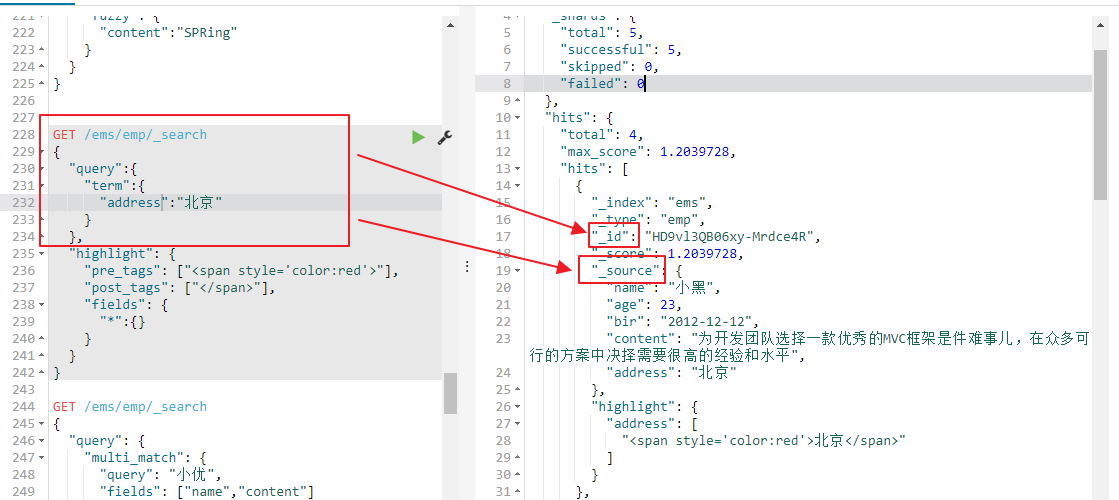
highlight 高亮查询,三要素:高亮字段(fields),前缀(pre_tags),后缀(post_tags)。
GET /ems/emp/_search { "query":{ "term":{ "address":"北京" } }, "highlight": { "pre_tags": ["<span style='color:red'>"], "post_tags": ["</span>"], "fields": { "*":{} } } }
查询显示的效果为
我们希望搜索title字段时,除了title字段中匹配关键字高亮,摘要abstract字段对应的关键字也要高亮,这需要对require_field_match属性进行设置。
By default, only fields that contains a query match are highlighted. Set require_field_match to false to highlight all fields. Defaults to true.
默认情况下,只有包含查询匹配的字段才会突出显示。 因为默认require_field_match值为true,可以设置为false以突出显示所有字段。
【例子】title和abstract字段高亮
GET website/_search { "query" : { "match": { "title": "yum" } }, "highlight" : { "require_field_match":false, "fields" : { "title" : {}, "abstract" : {} } } }
接下来第二个查询
2. 多字段查询(multi_match)
GET /ems/emp/_search { "query": { "multi_match": { "query": "小优", "fields": ["name","content"] } } }
多字段查询的multi_match指定的filed要做分词,标准的中文分词家将小优分成两个单字“小”和“优”分表去到两个字段name和content字段去查询,结构取并集
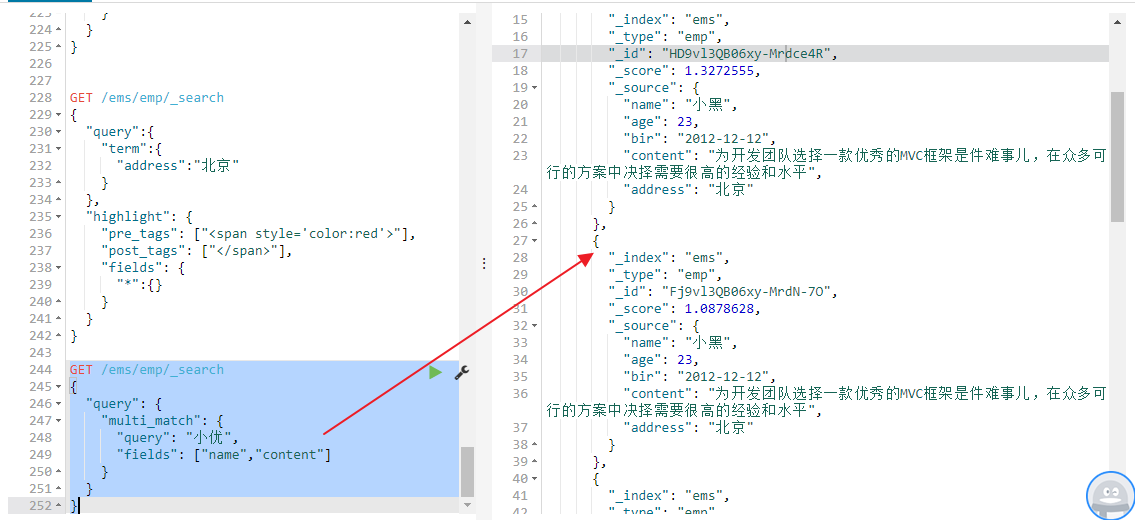
查询结果中name和content两个字段中包含小字和优字的内容都会被查询出来
matchQuery,将分词后的查询条件和词条进行等值匹配,默认取并集(OR)
GET /dangdang/book/_search { "query": { "query_string": { "query": "中国声音", "analyzer": "ik_max_word", "fields": ["name","content"] } } }
功能和multi_match类型,但是这里我们能够指定查询的filed字段按照那种方式进行分词,这里中国声音按照ik_max_word这个分词去分词,分词完成之后再去查询
query_string查询的时候默认是_all,即对所有字段进行查询。这里_all 字段是啥意思了,在6.0版本之前_all字段是存在的,很多博客都进行了分析如
_all是所有字段的大杂烩,默认情况下,每个字段的内容,都会拷贝到_all字段.
这样可以忽略字段信息进行搜索,非常方便.
但是这样带来了额外的存储压力和CPU处理压力.
在默认情况下,开启_all和_source
{ "mappings": { "sod_song_ksc": { "_source": { "enabled": true }, "_all": { "enabled": true, "analyzer": "ik" }, "properties": { "SongID": { "type": "long", "store": "yes", "index": "not_analyzed" }, "Name": { "type": "multi_field", "fields": { "Name": { "type": "string", "store": "yes", "index": "analyzed", "analyzer": "ik" }, "raw": { "type": "string", "store": "yes", "index": "not_analyzed" } } }, "SingerName": { "type": "string", "store": "yes", "index": "analyzed", "analyzer": "stop" } } } } }
这样索引下来,占用空间很大.
根据我们单位的情况,我觉得可以将需要的字段保存在_all中,然后使用IK分词以备查询,其余的字段,则不存储.
并且禁用_source字段.(也可以通过_source includes或者excludes 指定或者排除字段)
{ "mappings": { "sod_song_ksc": { "dynamic_templates": [ { "all_field": { "mapping": { "index": "no", "store": "yes", "type": "{dynamic_type}", "include_in_all": false }, "match": "*" } } ], "_source": { "enabled": false }, "_all": { "enabled": true, "analyzer": "ik" }, "properties": { "SongID": { "type": "long", "store": "yes", "index": "not_analyzed", "include_in_all": true }, "Name": { "type": "multi_field", "fields": { "Name": { "type": "string", "store": "yes", "index": "analyzed", "analyzer": "ik" }, "raw": { "type": "string", "store": "yes", "index": "not_analyzed", "include_in_all": true } } }, "SingerName": { "type": "string", "store": "yes", "index": "analyzed", "analyzer": "stop", "include_in_all": true } } } } }
这里采用了动态映射的功能(dynamic_templates),符合条件的字段,直接采用动态映射中预先的配置.
这里动态映射匹配所有字段,将_all禁用。
然后有需要的字段,再逐个开启.
索引之后,效果非常明显.磁盘占用减少了一半还多.
动态映射 {name}表示文档中原始的字段名称,{dynamic_type}表示原始文档的类型
第二篇文章
https://www.cnblogs.com/gavinYang/p/11199898.html
https://www.cnblogs.com/crystaltu/p/7200120.html
最近在使用ELasitcsearch的时候,需要用到关键字搜索,因为是全字段搜索,就需要使用_all字段的query_string进行搜索。
但是在使用的时候,遇到问题了。我们的业务并不需要分词,我在各个字段也设置了,not_analyzed。但是在使用query_string对_all字段进行查询的时候,
发现结果是分词之后,赶紧找问题。。最后在官网找到这么一段话:
Remember that the _all field is just an analyzed string field. It uses the default analyzer to analyze its values, regardless of which analyzer has been set on the fields where the values originate. And like any string field, you can configure which analyzer the _all field should use:
PUT /my_index/my_type/_mapping
{
"my_type": {
"_all": { "analyzer": "whitespace" }
}
}
就是说,我们在字段中的分词设置并不管用,如果需要分词,只能重新设置。就是为_all指定分词器。这里,我指定了通过空格去进行分词。
终于,通过query_string就可以正常使用了。
记住,_all 字段仅仅是一个 经过分词的 string 字段。它使用默认分词器来分析它的值,不管这个值原本所在字段指定的分词器。就像所有 string 字段,你可以配置 _all 字段使用的分词器:
上面的文章仅仅是针对6.0之前的版本,对于6.0之后的版本,_all字段已经被关闭和默认不适用了
2. _all字段默认关闭 **
在一个新的mapping中,_all元数据字段中默认包含从其他字段复制来的文本功能已经关闭.之前的版本中中,使用
query_string 和 simple_query_string查询会使用 _all字段进行查询,但是现在将会检查 _all是否启用._all字段可能在Elasticsearch 6.0或更高的版本中不再需要在创建索引的时候进行配置.
3. include_in_all现在不允许使用由于默认情况下_all字段现在可能是不启用,因此无法再使用创建mapping的时候使用‘include_in_all`字段
2.默认关闭_all元字段
_all字段可以包含其它字段的内容,作为超级字段做模糊(这里的模糊指不清楚搜索哪个字段的情况)搜索,Elasticsearch 6.0开始 _all字段默认关闭。
3.include_in_all失效
因为_all字段默认关闭,索引的mapping中也不再支持include_in_all。
接下来我们将讲讲es中几个比较重要的概念
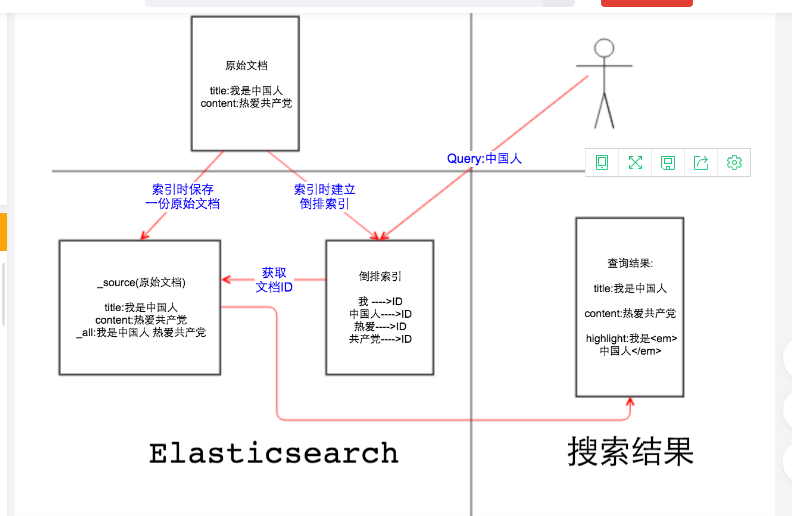
图解elasticsearch的_source、_all、store和index
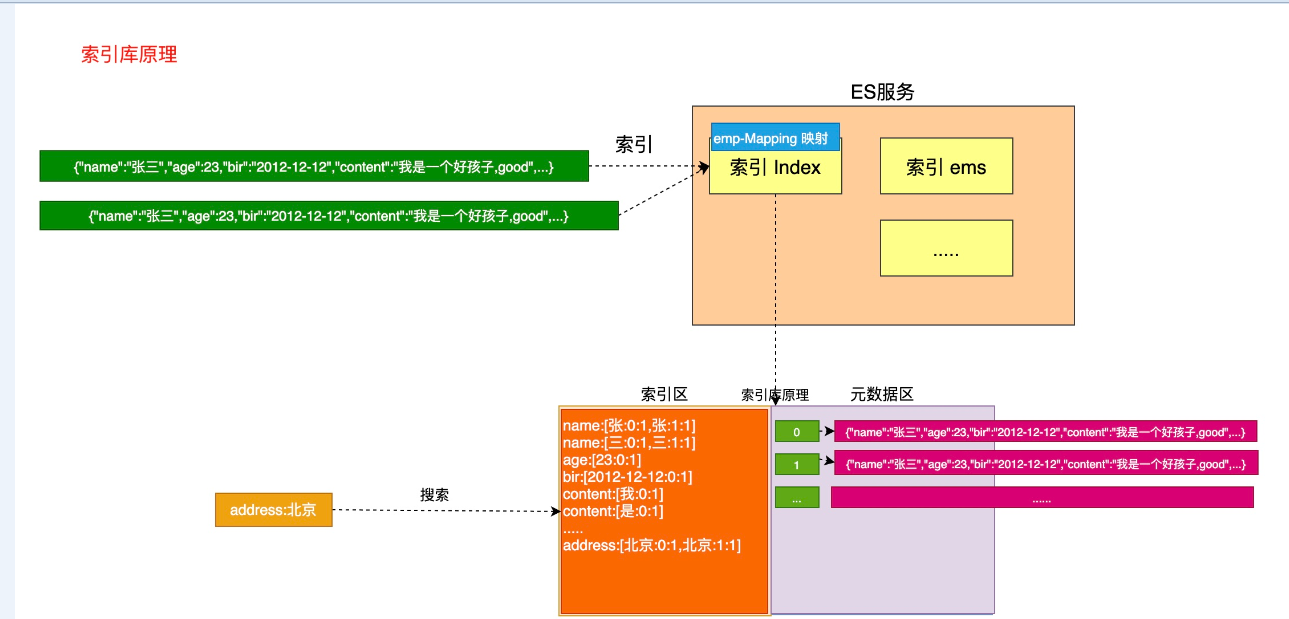
我们来分析下es索引底层的远程,存储两个区一个是元数据区,另外一个是索引区,索引下面的一个文档进行的时候,首先会在元数据区存储一份完整的数据,这样的元数据区的内容就是_source字段
元数据区的数据每一条记录都会对于一个文档的编号。这个编号是唯一的,对应的就是字段_id的值
接下来es会对es的文档中依据当前的字段构建索引,按照索引mapping定义的结构构建索引,对于第一个文档中name字段是text类型,需要进行分词,在索引区建立关系,name中张三被标准索引分为张字和三字
在索引区会形成记录,张字对应元素数据区的文档编号为0,并且还会记录张在0号文档出现的次数
在索引区会形成记录,三字对应元素数据区的文档编号为0,并且还会记录张在0号文档出现的次数
记下来看下address字段,对于的mapping为keyword,keyword不做分词,address为北京最为一个整体在索引区进行记录
北京在0号文档,并且记录北京在0号文档出现的次数是1次
其它字段类似
当用户搜索的时候,搜下搜索的时候是搜索索引区,当用户搜索name为张三的时候,搜索会搜索索引区,列如使用term查询张三的时候,在索引区存储的是张或者三,trem是精确查询不会对查询的filed做分词,张三所以查询不到
当查询address为北京的时候,因为在索引区存在北京,会查询出当前北京对于的是那个文档,在索引区获得当前北京对于的_id,然后用过_id在元数据区查询_id对于的整个文档的数据_source然后给用户
所有是先搜查索引区获得对于的文档_id, 然后通过_id查询元数据区的文档数据,然后返回给用户
这里在查询的时候查询北京的时候,address为北京可能存储多个文档中都存在北京这个字段,我们需要做相关度排序,列如北京在0号文档中出现了6次,在1号文档中出现了2次,那么返回的时候0号文档的_score得分最高放在最前面返回
如果北京在0号文档和1号文档在address字段中出现的次数都一样,那么还要检查北京在文档的其它字段中出现的次数,依据次数优先级来做一个返回,计算出相关度
字段_id就是文档在元数据区对于的文档的唯一编号
_source中存储了整个文档的各个字段的完整的数据信息
_source字段默认是存储的在es中的, 什么情况下不用保留_source字段?如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,最后返回文档id,或者文档的_id之后查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。如果想要关闭_source字段,在mapping中的设置如下:
PUT /ems { "mappings":{ "emp":{ "_source":{ "enabled":false }, "properties":{ "name":{ "type":"text" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } }
这样我们查询的时候就得不到_source字段,只能查询得到你当前文档的_id的值,我们来看下

如果只想存储某几个字段的原始值到Elasticsearch,可以通过incudes参数来设置,在mapping中的设置如下:
PUT /ems { "mappings":{ "emp":{ "_source":{ "includes":["name","address"] }, "properties":{ "name":{ "type":"text" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } }
我们来查询,看看查询之后返回的结果为
同样,可以通过excludes参数排除某些字段:
PUT /ems { "mappings":{ "emp":{ "_source":{ "excludes":["name","address"] }, "properties":{ "name":{ "type":"text" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } }
对于一个字段有几种类型:
在Elasticsearch 5之前,index属性的取值有三个:
analyzed:字段被索引,会做分词,可搜索。反过来,如果需要根据某个字段进搜索,index属性就应该设置为analyzed。
not_analyzed:字段值不分词,会被原样写入索引。反过来,如果某些字段需要完全匹配,比如人名、地名,index属性设置为not_analyzed为佳。
no:字段不写入索引,当然也就不能搜索。反过来,有些业务要求某些字段不能被搜索,那么index属性设置为no即可。
在es6中,如果一个字段我们不想让该字段被搜索,就不能让该字段存储在索引区中,如果我们让name不能被搜索,存储在索引区中,我们可以如下设置
PUT /ems { "mappings":{ "emp":{ "_source":{ "enabled":false }, "properties":{ "name":{ "type": "keyword", "store": "true", "index": "false" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } }
这样当我们查询name字段的时候就会报下面的错误,抛出一个查询的异常

注意2:
字符串 - text:用于全文索引,该类型的字段将通过分词器进行分词,最终用于构建索引
字符串 - keyword:不分词,只能搜索该字段的完整的值,值也会存储到索引区中
接下来我们来看看字段store的字段的值
默认情况下_source字段中包含一个一个文档中全部字段的值,_source的值默认是存储在es中的,这样各个字段的值默认是不会在存储在es中,如果再存储会引起两次数据的存储
这里就要说到store属性,store属性用于指定是否将原始字段写入索引,默认取值为no,在Elasticsearch,因为_source中已经存储了一份原始文档,可以根据_source中的原始文档实现高亮,在索引中再存储原始文档就多余了,所以Elasticsearch默认是把store属性设置为no。如果我们想每个字段的值存储在es中,我们可以如何这样的设置
PUT /ems { "mappings":{ "emp":{ "_source":{ "enabled":false }, "properties":{ "name":{ "type": "keyword", "store": "true", "index": "false" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } }
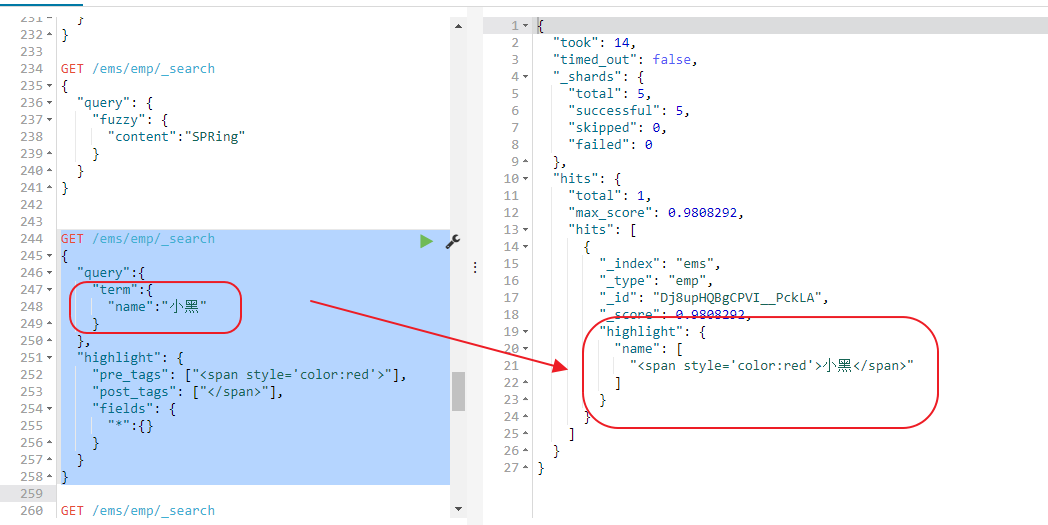
注意:如果想要对某个字段实现高亮功能,_source和store至少保留一个。下面会给出测试代码。现在我们将_source字段设置为false不再存储在es中,我们要将name字段高亮显示,我们就必须将name字段存储到es中必须将熟悉store设置为true
PUT /ems { "mappings":{ "emp":{ "_source":{ "enabled":false }, "properties":{ "name":{ "type": "keyword", "store": "true", "index": "true" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"keyword" } } } } }
我们来看下测试的代码,我们来验证下
GET /ems/emp/_search { "query":{ "term":{ "name":"小黑" } }, "highlight": { "pre_tags": ["<span style='color:red'>"], "post_tags": ["</span>"], "fields": { "*":{} } } }
测试的结果如下
接下来我们来看下ik分词器

## 11. IK分词器
> **NOTE: 默认ES中采用标准分词器进行分词,这种方式并不适用于中文网站,因此需要修改ES对中文友好分词,从而达到更佳的搜索的效果。**
在线安装IK (v5.5.1版本后开始支持在线安装 )
# 0.必须将es服务中原始数据删除
- 进入es安装目录中将data目录数据删除
rm -rf data# 1. 在es安装目录中执行如下命令
[es@linux elasticsearch-6.2.4]$ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.0/elasticsearch-analysis-ik-6.8.0.zip -> Downloading https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip [=================================================] 100% -> Installed analysis-ik [es@linux elasticsearch-6.2.4]$ ls plugins/ analysis-ik [es@linux elasticsearch-6.2.4]$ cd plugins/analysis-ik/ [es@linux analysis-ik]$ ls commons-codec-1.9.jar elasticsearch-analysis-ik-6.2.4.jar httpcore-4.4.4.jar commons-logging-1.2.jar httpclient-4.5.2.jar plugin-descriptor.properties# 2. 重启es生效
# 3.测试ik安装成功
11.2 本地安装IK
可以将对应的IK分词器下载到本地,然后再安装 **NOTE: 本课程使用本地安装**
# 1. 下载对应版本 - [es@linux ~]$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip# 2. 解压 - [es@linux ~]$ unzip elasticsearch-analysis-ik-6.2.4.zip #先使用yum install -y unzip# 3. 移动到es安装目录的plugins目录中 - [es@linux ~]$ ls elasticsearch-6.2.4/plugins/ [es@linux ~]$ mv elasticsearch elasticsearch-6.2.4/plugins/ [es@linux ~]$ ls elasticsearch-6.2.4/plugins/ elasticsearch [es@linux ~]$ ls elasticsearch-6.2.4/plugins/elasticsearch/ commons-codec-1.9.jar config httpclient-4.5.2.jar plugin-descriptor.properties commons-logging-1.2.jar elasticsearch-analysis-ik-6.2.4.jar httpcore-4.4.4.jar # 4. 重启es生效接下来我们来看下ik分词器的设置的问题
DELETE /ems PUT /ems { "mappings":{ "emp":{ "properties":{ "name":{ "type":"text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "age":{ "type":"integer" }, "bir":{ "type":"date" }, "content":{ "type":"text" }, "address":{ "type":"text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } } }name和address我们都设置为text类型,改类型支持分词,我们使用analyzer的值表示改字段的值分词按照ik_max_word分词存储到索引区中,
search_analyzer字段指定我们搜索的query查询的filed字段在分词的时候使用的分词器,在使用的时候一定要保证search_analyzer的类型要和analyzer类型一致。默认情况下,我们可以不设置search_analyzer的值,默认查询的时候查询filed字段的分词默认就是采用analyzer的分词器
现在我们来测试下,term查询的时候查询的查询的字段不做分词,我们查询小黑,原理小黑会被分成两个字小和黑存储在索引区中,现在会被分为小、黑和小黑三个词存储在索引区中,所以使用term查询小黑能够在索引区查询得到对于的记录,我们来测试下
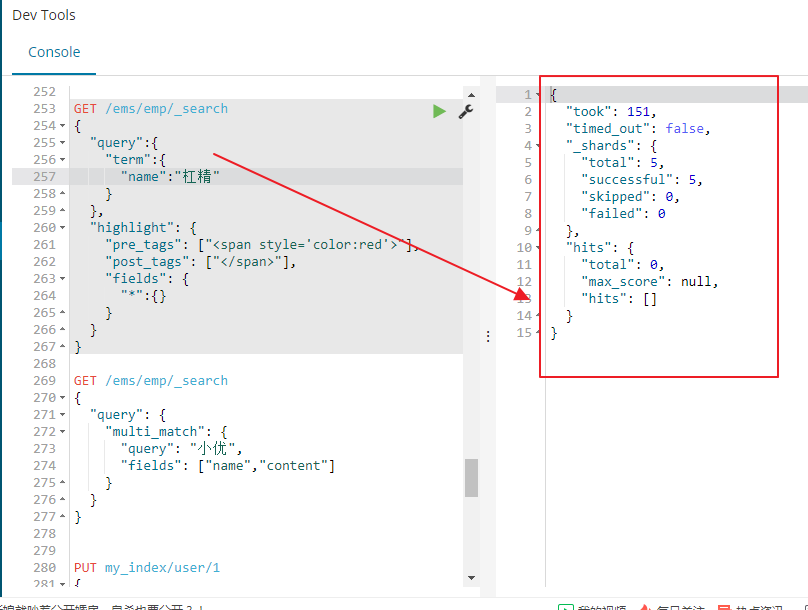
使用IK分词器还存在一个问题就是一些网络的词语,列如杠精、现在我们在es中加入了一条文档,文档中的name的值就是杠精
我们来进行搜索的时候,我们发现我们是无法搜查出杠精这两个字的
杠精即使使用了ik_max_word分词,也无法作为一个完整的词进行分词,**`扩展词典`**就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典
如何定义扩展词典和停用词典可以修改IK分词器中config目录中IKAnalyzer.cfg.xml这个文件。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">weiyuan-ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">weiyuan-stop.dic</entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>

2. 在ik分词器目录下config目录中创建ext_dict.dic文件 编码一定要为UTF-8才能生效 vim ext_dict.dic 加入扩展词即可
3. 在ik分词器目录下config目录中创建ext_stopword.dic文件
vim ext_stopword.dic 加入停用词即可
4.记住这里最好删除es中data目录下的全部内容,然后重启es生效

现在上面的这种方案有一个很大的问题,就是我们必须人为的去添加,这样肯定是不太友好的
我们可以这样做,在应用程序中,我们可以统计用户查询的高频的关键字,我们把这些关键字存储在一个文件中,我们的es监控这个文件的变化,当文件有变化的时候,es能够自动重新加载分词
实际上es已经给我们提供了这个功能
我们创建一个springboot项目,我们在webapp下面建立一个文件remote.dic文件,我们手动修改文件的值,来模拟下es能不能自动更新分词
前我在学习springBoot集成springMVC的时候发现webapp目录,
1. 直接右键运行,访问不到页面,原来并不是不支持啊,只是默认没有把它放在编译路径里面。
我们可以在项目的package exlorer视图下,右键build path—>configure build path—>source下
—>add folder按钮,添加编译路径

apply应用配置后,就会发现我们的maven,target目录下的classes中有WEB-INF啦,你在webapp目录下写的页面目录也会在里面哦

整个web工程启动之后,我们访问下路径

接下来在es的我们修改IKAnalyzer.cfg.xml配置文件,在文件中增加下面的内容
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">weiyuan-ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">weiyuan-stop.dic</entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">http://127.0.0.1:8001/remote.dic</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
配置之后,我们重启es
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">weiyuan-ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">weiyuan-stop.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
其实准确来说,ES中的查询操作分为2种: `查询(query)`和`过滤(filter)`。`查询即是之前提到的query查询,它 (查询)默认会计算每个返回文档的得分,然后根据得分排序`。`而过滤(filter)只会筛选出符合的文档,并不计算 得分,且它可以缓存文档 。所以,单从性能考虑,过滤比查询更快`。

filter和query一起使用时, 会先执行filter.
Elasticsearch会自动缓存经常使用的过滤器,以加快性能。
我们来看下面的一个列子
GET /ems/emp/_search { "query":{ "bool": { "must": [ { "term": { "name": { "value": "小" } } } ], "filter": { "range": { "age": { "gte": 20, "lte": 30 } } } } }, "highlight": { "pre_tags": ["<span style='color:red'>"], "post_tags": ["</span>"], "fields": { "*":{} } } }
这里查询must和filter两个组合条件一起使用,所有要使用bool进行组合两个查询条件
1、执行的时候,先执行filter,过滤全部的文档得到年龄满足条件的文档
2、然后在从满足条件的文档中执行查询操作,然后计算每个文档对于搜索条件的相关度分数, 再根据评分倒序排序.
在数据量文档很大的情况下,使用filter能够大大的提高查询效率,并且es能够对多次filter做缓存
然后计算每个文档对于搜索条件的相关度分数, 再根据评分倒序排序.
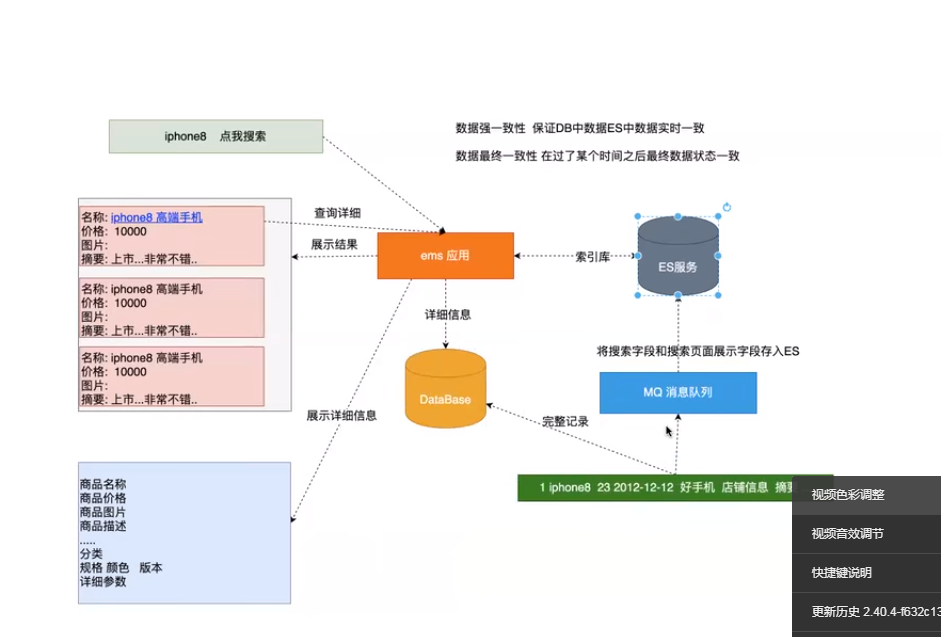
es和标准原理数据库之间的关系
1、搜索的时候搜索的基本介绍数据是存储在es中,存储在es中便于搜索
2、点击详细详情的时候,商品的详细信息是存储在mysql数据库中的
3、当用户修改商品的时候,首先要更新mysql中商品的详细信息,然后把更新的信息通过mq发送给es服务,es服务做数据的同步
Java操作ES
引入maven依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.2.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.2.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
<version>6.2.4</version>
</dependency>
这路的maven依赖的版本一定要和elasticsearch安装的版本一致,这里ems是索引名称,es提供了两个端口9200是web页面查询es的。9300是java代码通过 tcp端口api操作es的
创建索引
package com.itmayiedu.api.controller; import java.net.InetAddress; import java.net.UnknownHostException; import java.util.concurrent.ExecutionException; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.TransportAddress; import org.elasticsearch.transport.client.PreBuiltTransportClient; import org.junit.Test; public class ElasticsearchTest { //创建索引 @Test public void createIndex() throws UnknownHostException, ExecutionException, InterruptedException { PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY); preBuiltTransportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //定义索引请求 CreateIndexRequest ems = new CreateIndexRequest("ems"); //执行索引创建 CreateIndexResponse createIndexResponse = preBuiltTransportClient.admin().indices().create(ems).get(); System.out.println(createIndexResponse.isAcknowledged()); } }
删除索引
//删除索引 @Test public void deleteIndex() throws UnknownHostException, ExecutionException, InterruptedException { PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY); preBuiltTransportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //定义索引请求 DeleteIndexRequest ems = new DeleteIndexRequest("ems"); //执行索引删除 AcknowledgedResponse acknowledgedResponse = preBuiltTransportClient.admin().indices().delete(ems).get(); System.out.println(acknowledgedResponse.isAcknowledged()); }
创建索引并且指定索引的mapping映射类型
//创建索引类型和映射 @Test public void init() throws UnknownHostException, ExecutionException, InterruptedException { PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY); preBuiltTransportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //创建索引 CreateIndexRequest ems = new CreateIndexRequest("ems"); //定义json格式映射 String json = "{"properties":{"name":{"type":"text","analyzer":"ik_max_word"},"age":{"type":"integer"},"sex":{"type":"keyword"},"content":{"type":"text","analyzer":"ik_max_word"}}}"; //设置类型和mapping ems.mapping("emp",json, XContentType.JSON); //执行创建 CreateIndexResponse createIndexResponse = preBuiltTransportClient.admin().indices().create(ems).get(); System.out.println(createIndexResponse.isAcknowledged()); }
//索引一条文档 指定id
//索引一条文档 指定id @Test public void createIndexOptionId() throws UnknownHostException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); Emp emp = new Emp("小陈", 23, "男", "这是一个单纯的少年,单纯的我!"); String s = JSONObject.toJSONString(emp); String aa ="{"age":23,"content":"这是一个单纯的少年,单纯的我!","name":"小陈","sex":"男"}"; String aa2 ="{"name":"小陈", "age":23,"sex":"男","content":"这是一个单纯的少年,单纯的我!"}"; IndexResponse indexResponse = transportClient.prepareIndex("ems2", "emp", "1").setSource(aa2, XContentType.JSON).get(); System.out.println(indexResponse.status()); }
这里在插入数据的时候会报下面的错误
{ "error": { "root_cause": [ { "type": "translog_exception", "reason": "Failed to write operation [NoOp{seqNo=0, primaryTerm=4, reason='null'}]", "index_uuid": "iH5U4UVsRuetHq2wDragng", "shard": "1", "index": "stu" } ], "type": "translog_exception", "reason": "Failed to write operation [NoOp{seqNo=0, primaryTerm=4, reason='null'}]", "index_uuid": "iH5U4UVsRuetHq2wDragng", "shard": "1", "index": "stu", "caused_by": { "type": "null_pointer_exception", "reason": null } }, "status": 500 }
后面定为了很久,估计是java代码和ik分词器不兼容引起的,把ik分词器删除了后面就不会报错了,String json = "{"properties":{"name":{"type":"text","analyzer":"ik_max_word"},"age":{"type":"integer"},"sex":{"type":"keyword"},"content":{"type":"text","analyzer":"ik_max_word"}}}";
在对于的"analyzer":"ik_max_word"去掉就不报错了
//自定生成id索引记录 @Test public void createIndexOptionId() throws JsonProcessingException { Emp emp = new Emp("小白", 23, "男", "这是一个单纯的小白,单纯的我!"); String s = JSONObject.toJSONString(emp); IndexResponse indexResponse = transportClient.prepareIndex("ems", "emp") .setSource(s, XContentType.JSON).get(); System.out.println(indexResponse.status()); }
//更新一条记录 @Test public void testUpdate() throws IOException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); Emp emp = new Emp(null, 0, null, null); emp.setName("明天你好"); String s = JSONObject.toJSONString(emp); UpdateResponse updateResponse = transportClient.prepareUpdate("ems", "emp", "1") .setDoc(s,XContentType.JSON).get(); System.out.println(updateResponse.status()); }
13.4 删除一条文档
//删除一条记录 @Test public void testDelete() throws UnknownHostException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); DeleteResponse deleteResponse = transportClient.prepareDelete("ems", "emp", "1").get(); System.out.println(deleteResponse.status()); }
13.5 批量更新
//批量更新 @Test public void testBulk() throws IOException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //添加第一条记录 IndexRequest request1 = new IndexRequest("ems","emp","1"); Emp emp = new Emp("中国科技", 23, "男", "这是好人"); request1.source(JSONObject.toJSONString(emp),XContentType.JSON); //添加第二条记录 IndexRequest request2 = new IndexRequest("ems","emp","2"); Emp emp2 = new Emp("中国科技", 23, "男", "这是好人"); request2.source(JSONObject.toJSONString(emp2),XContentType.JSON); //更新记录 UpdateRequest updateRequest = new UpdateRequest("ems","emp","1"); Emp empUpdate = new Emp(null, 0, null, null); empUpdate.setName("中国力量"); updateRequest.doc(JSONObject.toJSONString(empUpdate),XContentType.JSON); //删除一条记录 DeleteRequest deleteRequest = new DeleteRequest("ems","emp","2"); BulkResponse bulkItemResponses = transportClient.prepareBulk() .add(request1) .add(request2) .add(updateRequest) .add(deleteRequest) .get(); BulkItemResponse[] items = bulkItemResponses.getItems(); for (BulkItemResponse item : items) { System.out.println(item.status()); } }
/** * 查询所有并排序 * ASC 升序 DESC 降序 * addSort("age", SortOrder.ASC) 指定排序字段以及使用哪种方式排序 * addSort("age", SortOrder.DESC) 指定排序字段以及使用哪种方式排序 */ @Test public void testMatchAllQuery() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(QueryBuilders.matchAllQuery()).addSort("age", SortOrder.DESC).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } }
分页查询
/** * 分页查询 * From 从那条记录开始 默认从0 开始 form = (pageNow-1)*size * Size 每次返回多少条符合条件的结果 默认10 */ @Test public void testMatchAllQueryFormAndSize() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(QueryBuilders.matchAllQuery()).setFrom(0).setSize(2).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } }
/** * 查询返回指定字段(source) 默认返回所有 * setFetchSource 参数1:包含哪些字段 参数2:排除哪些字段 * setFetchSource("*","age") 返回所有字段中排除age字段 * setFetchSource("name","") 只返回name字段 * setFetchSource(new String[]{},new String[]{}) */ @Test public void testMatchAllQuerySource() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(QueryBuilders.matchAllQuery()). setFetchSource("*","age").get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } }
term查询
/** * term查询 */ @Test public void testTerm() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); TermQueryBuilder queryBuilder = QueryBuilders.termQuery("name","中国"); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(queryBuilder).get(); }
/** * rang查询 * lt 小于 * lte 小于等于 * gt 大于 * gte 大于等于 */ @Test public void testRange() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age").lt(45).gte(8); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(rangeQueryBuilder).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } }
/** * bool 查询 */ @Test public void testBool() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.should(QueryBuilders.matchAllQuery()); boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("age").lte(8)); boolQueryBuilder.must(QueryBuilders.termQuery("name","中国")); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(boolQueryBuilder).get(); }
高亮查询
/** * 高亮查询 * .highlighter(highlightBuilder) 用来指定高亮设置 * requireFieldMatch(false) 开启多个字段高亮 * field 用来定义高亮字段 * preTags("<span style='color:red'>") 用来指定高亮前缀 * postTags("</span>") 用来指定高亮后缀 */ @Test public void testHighlight() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "小黑"); HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.requireFieldMatch(false).field("name").field("content").preTags("<span style='color:red'>").postTags("</span>"); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").highlighter(highlightBuilder).highlighter(highlightBuilder).setQuery(termQueryBuilder).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { Map<String, Object> sourceAsMap = hit.getSourceAsMap(); Map<String, HighlightField> highlightFields = hit.getHighlightFields(); System.out.println("================高亮之前=========="); for(Map.Entry<String,Object> entry:sourceAsMap.entrySet()){ System.out.println("key: "+entry.getKey() +" value: "+entry.getValue()); } System.out.println("================高亮之后=========="); for (Map.Entry<String,Object> entry:sourceAsMap.entrySet()){ HighlightField highlightField = highlightFields.get(entry.getKey()); if (highlightField!=null){ System.out.println("key: "+entry.getKey() +" value: "+ highlightField.fragments()[0]); }else{ System.out.println("key: "+entry.getKey() +" value: "+entry.getValue()); } } } }
整个java代码如下
package com.itmayiedu.api.controller; import java.io.IOException; import java.net.InetAddress; import java.net.UnknownHostException; import java.util.Map; import java.util.concurrent.ExecutionException; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest; import org.elasticsearch.action.bulk.BulkItemResponse; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteRequest; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.support.master.AcknowledgedResponse; import org.elasticsearch.action.update.UpdateRequest; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.TransportAddress; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.index.query.BoolQueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.RangeQueryBuilder; import org.elasticsearch.index.query.TermQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightField; import org.elasticsearch.search.sort.SortOrder; import org.elasticsearch.transport.client.PreBuiltTransportClient; import org.junit.Test; import com.alibaba.fastjson.JSONObject; public class ElasticsearchTest { //创建索引 @Test public void createIndex() throws UnknownHostException, ExecutionException, InterruptedException { PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY); preBuiltTransportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //定义索引请求 CreateIndexRequest ems = new CreateIndexRequest("ems"); //执行索引创建 CreateIndexResponse createIndexResponse = preBuiltTransportClient.admin().indices().create(ems).get(); System.out.println(createIndexResponse.isAcknowledged()); } //删除索引 @Test public void deleteIndex() throws UnknownHostException, ExecutionException, InterruptedException { PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY); preBuiltTransportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //定义索引请求 DeleteIndexRequest ems = new DeleteIndexRequest("ems"); //执行索引删除 AcknowledgedResponse acknowledgedResponse = preBuiltTransportClient.admin().indices().delete(ems).get(); System.out.println(acknowledgedResponse.isAcknowledged()); } //创建索引类型和映射 @Test public void init() throws UnknownHostException, ExecutionException, InterruptedException { PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(Settings.EMPTY); preBuiltTransportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //创建索引 CreateIndexRequest ems = new CreateIndexRequest("ems2"); //定义json格式映射 String json = "{"properties":{"name":{"type":"text"},"age":{"type":"integer"},"sex":{"type":"keyword"},"content":{"type":"text"}}}"; //设置类型和mapping ems.mapping("emp",json, XContentType.JSON); //执行创建 CreateIndexResponse createIndexResponse = preBuiltTransportClient.admin().indices().create(ems).get(); System.out.println(createIndexResponse.isAcknowledged()); } //索引一条文档 指定id @Test public void createIndexOptionId() throws UnknownHostException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); Emp emp = new Emp("小陈", 23, "男", "这是一个单纯的少年,单纯的我!"); String s = JSONObject.toJSONString(emp); String aa ="{"age":23,"content":"这是一个单纯的少年,单纯的我!","name":"小陈","sex":"男"}"; String aa2 ="{"name":"小陈", "age":23,"sex":"男","content":"这是一个单纯的少年,单纯的我!"}"; IndexResponse indexResponse = transportClient.prepareIndex("ems2", "emp", "1").setSource(aa2, XContentType.JSON).get(); System.out.println(indexResponse.status()); } //索引一条文档 指定id @Test public void createIndexOptionId2() throws UnknownHostException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); Emp emp = new Emp("小白", 23, "男", "这是一个单纯的小白,单纯的我!"); String s = JSONObject.toJSONString(emp); IndexResponse indexResponse = transportClient.prepareIndex("ems", "emp") .setSource(s, XContentType.JSON).get(); System.out.println(indexResponse.status()); } //更新一条记录 @Test public void testUpdate() throws IOException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); Emp emp = new Emp(null, 0, null, null); emp.setName("明天你好"); String s = JSONObject.toJSONString(emp); UpdateResponse updateResponse = transportClient.prepareUpdate("ems", "emp", "1") .setDoc(s,XContentType.JSON).get(); System.out.println(updateResponse.status()); } //删除一条记录 @Test public void testDelete() throws UnknownHostException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); DeleteResponse deleteResponse = transportClient.prepareDelete("ems", "emp", "1").get(); System.out.println(deleteResponse.status()); } //批量更新 @Test public void testBulk() throws IOException { PreBuiltTransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY); transportClient.addTransportAddress(new TransportAddress( InetAddress.getByName("127.0.0.1"),9300)); //添加第一条记录 IndexRequest request1 = new IndexRequest("ems","emp","1"); Emp emp = new Emp("中国科技", 23, "男", "这是好人"); request1.source(JSONObject.toJSONString(emp),XContentType.JSON); //添加第二条记录 IndexRequest request2 = new IndexRequest("ems","emp","2"); Emp emp2 = new Emp("中国科技", 23, "男", "这是好人"); request2.source(JSONObject.toJSONString(emp2),XContentType.JSON); //更新记录 UpdateRequest updateRequest = new UpdateRequest("ems","emp","1"); Emp empUpdate = new Emp(null, 0, null, null); empUpdate.setName("中国力量"); updateRequest.doc(JSONObject.toJSONString(empUpdate),XContentType.JSON); //删除一条记录 DeleteRequest deleteRequest = new DeleteRequest("ems","emp","2"); BulkResponse bulkItemResponses = transportClient.prepareBulk() .add(request1) .add(request2) .add(updateRequest) .add(deleteRequest) .get(); BulkItemResponse[] items = bulkItemResponses.getItems(); for (BulkItemResponse item : items) { System.out.println(item.status()); } } /** * 查询所有并排序 * ASC 升序 DESC 降序 * addSort("age", SortOrder.ASC) 指定排序字段以及使用哪种方式排序 * addSort("age", SortOrder.DESC) 指定排序字段以及使用哪种方式排序 */ @Test public void testMatchAllQuery() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(QueryBuilders.matchAllQuery()).addSort("age", SortOrder.DESC).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } } /** * 分页查询 * From 从那条记录开始 默认从0 开始 form = (pageNow-1)*size * Size 每次返回多少条符合条件的结果 默认10 */ @Test public void testMatchAllQueryFormAndSize() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(QueryBuilders.matchAllQuery()).setFrom(0).setSize(2).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } } /** * 查询返回指定字段(source) 默认返回所有 * setFetchSource 参数1:包含哪些字段 参数2:排除哪些字段 * setFetchSource("*","age") 返回所有字段中排除age字段 * setFetchSource("name","") 只返回name字段 * setFetchSource(new String[]{},new String[]{}) */ @Test public void testMatchAllQuerySource() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(QueryBuilders.matchAllQuery()). setFetchSource("*","age").get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } } /** * term查询 */ @Test public void testTerm() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); TermQueryBuilder queryBuilder = QueryBuilders.termQuery("name","中国"); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(queryBuilder).get(); } /** * rang查询 * lt 小于 * lte 小于等于 * gt 大于 * gte 大于等于 */ @Test public void testRange() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age").lt(45).gte(8); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(rangeQueryBuilder).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { System.out.print("当前索引的分数: "+hit.getScore()); System.out.print(", 对应结果:=====>"+hit.getSourceAsString()); System.out.println(", 指定字段结果:"+hit.getSourceAsMap().get("name")); System.out.println("================================================="); } } /** * bool 查询 */ @Test public void testBool() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.should(QueryBuilders.matchAllQuery()); boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("age").lte(8)); boolQueryBuilder.must(QueryBuilders.termQuery("name","中国")); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").setQuery(boolQueryBuilder).get(); } /** * 高亮查询 * .highlighter(highlightBuilder) 用来指定高亮设置 * requireFieldMatch(false) 开启多个字段高亮 * field 用来定义高亮字段 * preTags("<span style='color:red'>") 用来指定高亮前缀 * postTags("</span>") 用来指定高亮后缀 */ @Test public void testHighlight() throws UnknownHostException { TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "小黑"); HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.requireFieldMatch(false).field("name").field("content").preTags("<span style='color:red'>").postTags("</span>"); SearchResponse searchResponse = transportClient.prepareSearch("ems").setTypes("emp").highlighter(highlightBuilder).highlighter(highlightBuilder).setQuery(termQueryBuilder).get(); SearchHits hits = searchResponse.getHits(); System.out.println("符合条件的记录数: "+hits.totalHits); for (SearchHit hit : hits) { Map<String, Object> sourceAsMap = hit.getSourceAsMap(); Map<String, HighlightField> highlightFields = hit.getHighlightFields(); System.out.println("================高亮之前=========="); for(Map.Entry<String,Object> entry:sourceAsMap.entrySet()){ System.out.println("key: "+entry.getKey() +" value: "+entry.getValue()); } System.out.println("================高亮之后=========="); for (Map.Entry<String,Object> entry:sourceAsMap.entrySet()){ HighlightField highlightField = highlightFields.get(entry.getKey()); if (highlightField!=null){ System.out.println("key: "+entry.getKey() +" value: "+ highlightField.fragments()[0]); }else{ System.out.println("key: "+entry.getKey() +" value: "+entry.getValue()); } } } } }
package com.itmayiedu.api.controller; public class Emp { String name; int age; String sex; String content; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } public Emp(String name, int age, String sex, String content) { super(); this.name = name; this.age = age; this.sex = sex; this.content = content; } }
接下来我们重点介绍下springboot整合es
PUT /dangdang { "mappings":{ "book":{ "properties":{ "name":{ "type": "text", "analyzer": "ik_max_word" }, "createDate":{ "type":"date" }, "author":{ "type":"keyword" }, "content":{ "type":"text", "analyzer": "ik_max_word" } } } } }
第二个视频2020年 最新版 Elasticsearch教学视频也是相当的经典呀

这里我来补充下一些数据
https://www.cnblogs.com/clarehjh/archive/2004/01/13/13614434.html
视频笔记在下面的目录











https://www.elastic.co/guide/en/elasticsearch/reference/7.2/index.html

3.5创建索引并指定数据结构

PUT /book { "settings":{ "number_of_shards":5, "number_of_replicas":1 }, "mappings":{ "novel":{ "properties":{ "name":{ "type":"text", "analyzer":"ik_max_word", "index":true, "store":false }, "author":{ "type":"keyword" }, "count":{ "type":"long" }, "on-sale":{ "type":"date", "format":"yyyy-MM-dd HH:mm:ss ||yyyy-MM-dd||epoch_millis" }, "descr":{ "type":"text", "analyzer":"ik_max_word" } } } } }

这里有filed有两个关键熟悉:index如果设置为false。表示改字段不能被外部在分词库中进行检索,查询的时候就会抛出异常
store字段默认是false,不会把改字段的值在es中进行存储,因为_source字段中已经存储了当前文档的所有字段的值,所有store如果设置为true,那么当前的字段就会被存储两份





所谓的覆盖式修改是将原来的文档删除了,然后重新建立一个新的文档,新的文档编号和删除的文档的编号是一致的,但是效率很慢,不推荐
我们推荐使用下面的doc方式

DELETE /book PUT /book { "settings":{ "number_of_shards":5, "number_of_replicas":1 }, "mappings":{ "novel":{ "properties":{ "name":{ "type":"text", "index":true, "store":false }, "author":{ "type":"keyword" }, "count":{ "type":"long" }, "on-sale":{ "type":"date", "format":"yyyy-MM-dd HH:mm:ss ||yyyy-MM-dd||epoch_millis" }, "descr":{ "type":"text" } } } } } POST /book/novel { "name": "盘龙", "author": "天下第一", "count": 1000, "on-sale": "2020-09-25", "descr": "sjdkjdfskjkjfsdkjkjfskjsfdkjfdkjs" } PUT /book/novel/2 { "name": "盘龙", "author": "天下第一", "count": 1000, "on-sale": "2020-09-25", "descr": "sjdkjdfskjkjfsdkjkjfskjsfdkjfdkjs" } POST /book/novel/2/_update { "doc":{ "name":"kebi" } }
这里java操作es

这里我们之前使用的api是preBuiltTransportClient连接的是TCP的9300端口,现在es官方推荐使用高级api,这里连接的端口是9200
Elasticsearch 会在7.0之后的版本废弃TransportClient,在8.0之后的版本移除TransportClient (文档)。因此,使用RestClient来进行相关的操作。
这里使用高级api需要引入下面的maven依赖
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>6.2.4</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.16.22</version> </dependency>
这里依赖的版本6.2.4一定要和当前安装的es版本一致
package com.qf.utils; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestHighLevelClient; public class ESClient { public static RestHighLevelClient getClient(){ HttpHost httpHost=new HttpHost("127.0.0.1",9200); RestClientBuilder clientBuilder= RestClient.builder(httpHost); RestHighLevelClient client=new RestHighLevelClient(clientBuilder); return client; } }
创建Demo1来测试连接
package com.qf.test; import com.qf.utils.ESClient; import org.elasticsearch.client.RestHighLevelClient; import org.junit.Test; public class Demo1 { @Test public void testConnect() { try { RestHighLevelClient client = ESClient.getClient(); System.out.println("ok!"); } catch (Exception e) { System.out.println(e); } } }
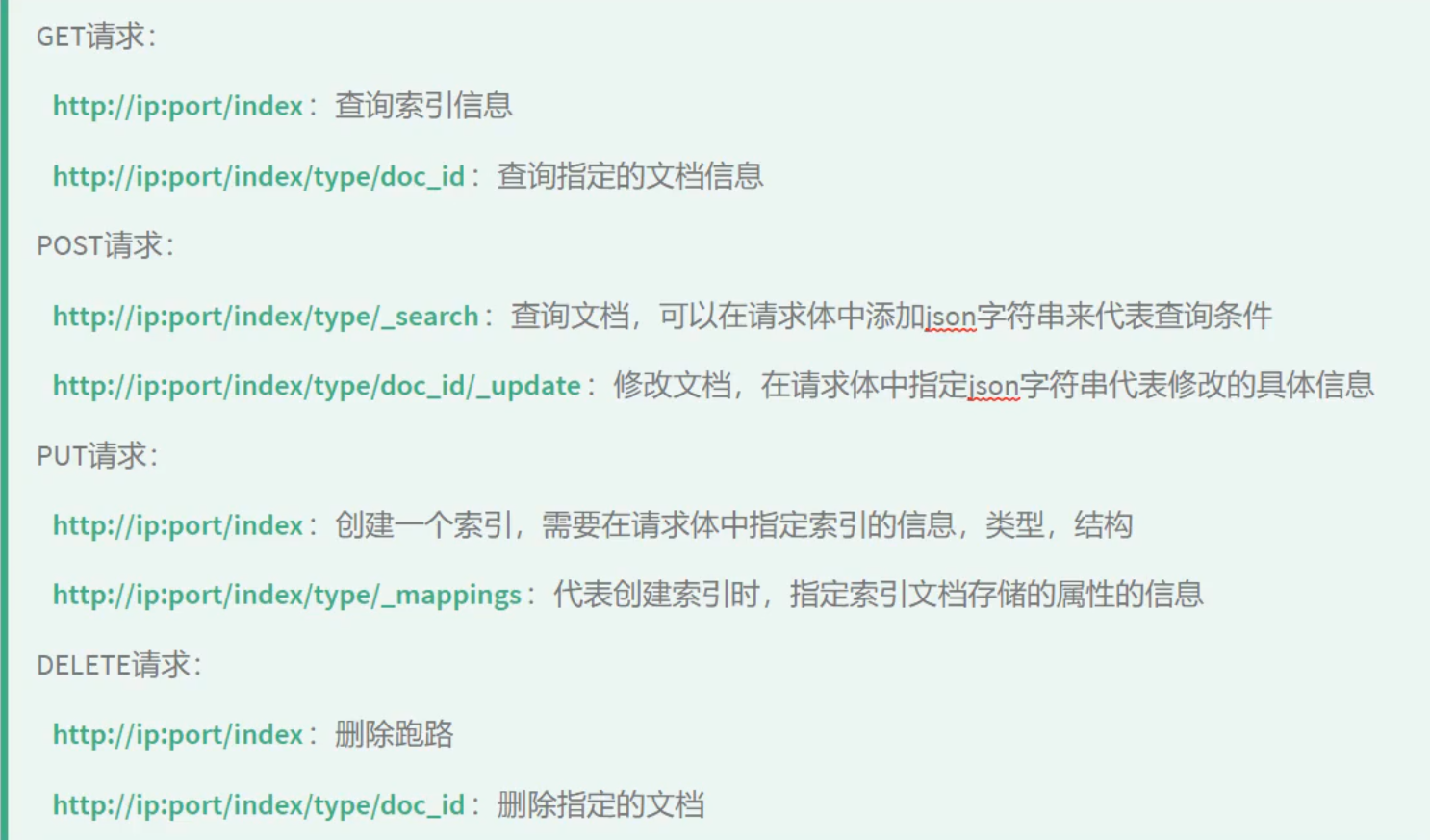
method url desc PUT localhost:9200/索引名称/类型名称/文档id 创建文档(指定文档id) POST localhost:9200/索引名称/类型名称 创建文档(随机id) POST localhost:9200/索引名称/_update/文档id 修改文档 DELETE localhost:9200/索引名称/类型名称/文档id 删除文档 by id GET localhost:9200/索引名称/类型名称/文档id 查询文档 by id POST localhost:9200/索引名称/_search 查询所有文档
2.Java创建索引
注意:由于之前使用的Liunx版本问题,在运行版本的时候提示java.net.ConnectException: Timeout connecting to xxxx.9200在网上找了很多办法无法解决,最后实在没办法就下载了Windows版本就可以了。
这里创建索引的时候报错,这里将es的版本升级到6.5.4就解决问题了
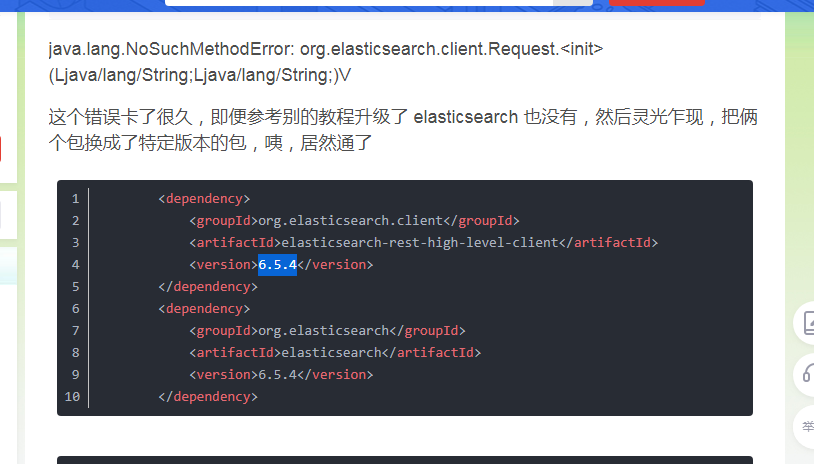
错误的日志如下
java.lang.NoSuchMethodError: org.elasticsearch.client.Request.<init>(Ljava/lang/String;Ljava/lang/String;)V at org.elasticsearch.client.RestClient.performRequest(RestClient.java:323) at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:488) at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:474) at org.elasticsearch.client.IndicesClient.create(IndicesClient.java:77) at com.qf.test.Demo2.createIndex2(Demo2.java:94) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source) at java.lang.reflect.Method.invoke(Unknown Source) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17) at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.eclipse.jdt.internal.junit4.runner.JUnit4TestReference.run(JUnit4TestReference.java:86) at org.eclipse.jdt.internal.junit.runner.TestExecution.run(TestExecution.java:38) at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:459) at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:675) at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.run(RemoteTestRunner.java:382) at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:192)
我们来看下创建索引的代码
package com.qf.test; import com.qf.utils.ESClient; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest; import org.elasticsearch.action.admin.indices.get.GetIndexRequest; import org.elasticsearch.action.support.master.AcknowledgedResponse; import org.elasticsearch.client.Client; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; //import org.elasticsearch.client.indices.CreateIndexRequest; //import org.elasticsearch.client.indices.CreateIndexResponse; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.json.JsonXContent; import org.junit.Test; import java.io.IOException; import java.util.HashMap; import java.util.Map; public class Demo2 { String index="person1"; String type="man"; @Test public void createIndex() throws IOException { //1.索引的settings Settings.Builder settings = Settings.builder() .put("number_of_shards", 3) .put("number_of_replicas", 1); //2.索引的mappings XContentBuilder mappings = JsonXContent.contentBuilder(); mappings .startObject() .startObject("properties") .startObject("name") .field("type", "text") .endObject() .startObject("age") .field("type", "integer") .endObject() .startObject("birthday") .field("type", "date") .field("format", "yyyy-MM-dd") .endObject() .endObject() .endObject(); //将settings和Mappings 封装到一个Request对象 CreateIndexRequest request = new CreateIndexRequest(index) .settings(settings) .mapping(type, mappings); //通过Client对象连接ES并执行创建索引 RestHighLevelClient client = ESClient.getClient(); //create(request,RequestOptions.DEFAULT) // CreateIndexResponse createIndexResponse =client.indices().create(request, RequestOptions.DEFAULT); CreateIndexResponse createIndexResponse =client.indices().create(request, RequestOptions.DEFAULT); System.out.println("resp:" + createIndexResponse.toString()); } }
2.1Java查询删除索引
@Test public void delete() throws IOException { //1.准备request对象 DeleteIndexRequest request=new DeleteIndexRequest(); request.indices(index); //2.通过Cilent操作 RestHighLevelClient client = ESClient.getClient(); AcknowledgedResponse delete=client.indices().delete(request,RequestOptions.DEFAULT); /* 3.输出 */ System.out.println(delete); }
判断索引是否存在的代码
@Test public void exists() throws IOException { //1.准备request对象 GetIndexRequest request=new GetIndexRequest(); request.indices(index); //2.通过Cilent操作 RestHighLevelClient client = ESClient.getClient(); boolean exists= client.indices().exists(request,RequestOptions.DEFAULT); //3.输出 System.out.println(exists); }
2.2Java操作文档
2.2.1添加文档
2.2.1添加文档
1.创建Person类
package com.qf.entity; import com.fasterxml.jackson.annotation.JsonFormat; import com.fasterxml.jackson.annotation.JsonIgnore; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import java.util.Date; public class Person { @JsonIgnore private Integer id; private String name; private Integer age; @JsonFormat(pattern = "yyyy-MM-dd") private Date birthday; public Person(Integer id, String name, Integer age, Date birthday) { this.id = id; this.name = name; this.age = age; this.birthday = birthday; } public Integer getId() { return id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Date getBirthday() { return birthday; } public void setBirthday(Date birthday) { this.birthday = birthday; } public void setId(Integer id) { this.id = id; } }
我们需要将person对象转化成json对象
2.创建测试类Demo3 注:添加json依赖包 <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.10.2</version> </dependency>
我们来看程序的代码
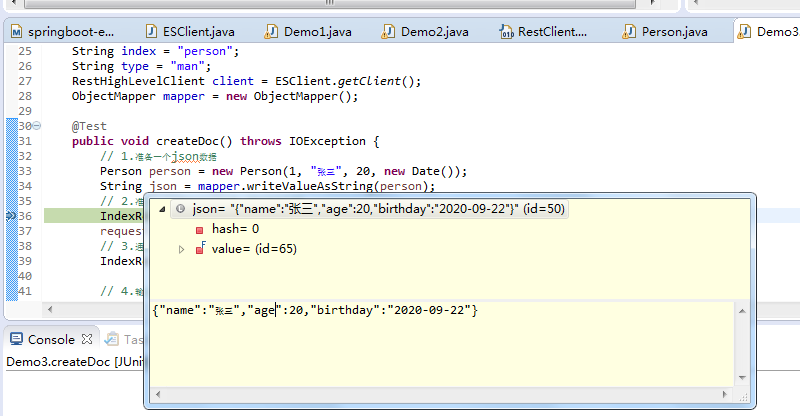
package com.qf.test; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import com.qf.entity.Person; import com.qf.utils.ESClient; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.junit.Test; import java.io.IOException; import java.util.Date; public class Demo3 { String index="person"; String type="man"; RestHighLevelClient client = ESClient.getClient(); ObjectMapper mapper=new ObjectMapper(); @Test public void createDoc() throws IOException { //1.准备一个json数据 Person person=new Person(1,"张三",20,new Date()); String json= mapper.writeValueAsString(person); //2.准备一个request对象(手动指定id) IndexRequest request=new IndexRequest(index,type,person.getId().toString()); request.source(json, XContentType.JSON); //3.通过client对象执行添加 IndexResponse resp =client.index(request, RequestOptions.DEFAULT); //4.输出返回结果 System.out.println(resp.getResult().toString()); } }
这里jsondata有几个关键点
将new Date()转化为es中中对应的yyyy-dd-MM类型,需要使用下面的注解
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthday;
其次, @JsonIgnore注解表示将person对象转行为json字符串的时候,json字符串中不包含id字段
我们添加文档记录的时候,手动指定_id的值
//2.准备一个request对象(手动指定id)
IndexRequest request=new IndexRequest(index,type,person.getId().toString());

2.2.2修改文档
@Test public void update() throws IOException { // 创建Map修改指定内容 Map<String, Object> doc = new HashMap<String, Object>(); doc.put("name", "张大三"); String docID = "1"; UpdateRequest request = new UpdateRequest(index, type, docID); request.doc(doc); UpdateResponse update = client.update(request, RequestOptions.DEFAULT); System.out.println(update.getResult().toString()); }
2.2.3删除文档
@Test public void delete() throws IOException { DeleteRequest request = new DeleteRequest(index, type, "1"); DeleteResponse resp = client.delete(request, RequestOptions.DEFAULT); System.out.println(resp.getResult().toString()); }
2.2.4批量添加文档
@Test public void BulkDoc() throws IOException { Person p1= new Person(1,"HJH",20,new Date()); Person p2= new Person(2,"YQG",30,new Date()); Person p3= new Person(3,"LWD",22,new Date()); String json1= mapper.writeValueAsString(p1); String json2= mapper.writeValueAsString(p2); String json3= mapper.writeValueAsString(p3); //创建Request,将准备好的数据封装进去 BulkRequest request=new BulkRequest(); request.add(new IndexRequest(index,type,p1.getId().toString()).source(json1,XContentType.JSON)); request.add(new IndexRequest(index,type,p2.getId().toString()).source(json1,XContentType.JSON)); request.add(new IndexRequest(index,type,p3.getId().toString()).source(json1,XContentType.JSON)); BulkResponse resp=client.bulk(request,RequestOptions.DEFAULT); System.out.println(resp.toString()); }
2.2.4批量删除文档
@Test public void bulkDeleteDoc() throws IOException { BulkRequest request=new BulkRequest(); request.add(new DeleteRequest(index,type,"1")); request.add(new DeleteRequest(index,type,"2")); request.add(new DeleteRequest(index,type,"3")); BulkResponse resp=client.bulk(request,RequestOptions.DEFAULT); System.out.println(resp); }
整个索引如下
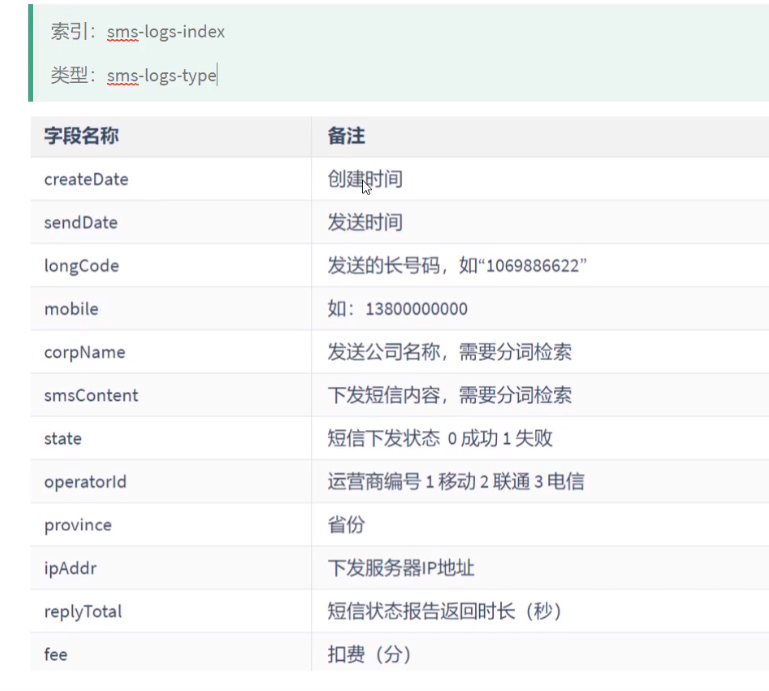
PUT /sms-logs-index { "settings":{ "number_of_shards":3, "number_of_replicas":1 }, "mappings":{ "sms-logs-type":{ "properties":{ "corpName":{ "type":"keyword" }, "createDate":{ "type":"date" }, "fee":{ "type":"long" }, "ipAddr":{ "type":"ip" }, "longCode":{ "type":"keyword" }, "mobile":{ "type":"keyword" }, "operatorId":{ "type":"integer" }, "province":{ "type":"keyword" }, "replyTotal":{ "type":"integer" }, "sendDate":{ "type":"date" }, "smsContent":{ "type":"text" }, "state":{ "type":"integer" } } } } }
二、ES的各种查询
2.1term&terms查询
2.1.1term查询(我试了下province没有办法查询,需到后面加个.keyword)

第二个:
POST /sms-logs-index/sms-logs-type/_search { "from": 0, "size": 5, "query":{ "terms":{ "province":[ "江苏", "北京", "南通" ] } } }

terms查询和term一样对查询的filed字段是不会做分页查询的
@Test public void termsQuerry() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.termsQuery("province.keyword","南通","江苏")); request.source(builder);; SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); //输出结果 for (SearchHit hit:rsp.getHits().getHits()) { Map<String,Object> result=hit.getSourceAsMap(); System.out.println(result); } }
2.2match_all&match查询
2.2.1match_all
POST /sms-logs-index/sms-logs-type/_search { "query": { "match_all": {} } }
match_all查询的时候是查询索引的全部文档数据,默认只显示10条数据注:ES默认查询10条数据
@Test public void matchAllQuery() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.matchAllQuery()); builder.size(20);//ES默认查询10条数据 request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.2.2match查询

POST /sms-logs-index/sms-logs-type/_search { "query": { "match": { "smsContent": "恭喜" } } }
@Test public void matchQuery() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.matchQuery("smsContent","恭喜")); builder.size(20);//ES默认查询10条数据 request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.2.3布尔match查询


public void booleanMatchQuery() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.matchQuery("smsContent","恭喜 高级").operator(Operator.AND)); builder.size(20);//ES默认查询10条数据 request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.2.4mulitMatch查询
多个match的组合也是要做分词查询的

@Test public void mulitMatchQuery() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.multiMatchQuery("北京","province","smsContent")); builder.size(20);//ES默认查询10条数据 request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.3id&ids查询
2.3.1id查询

@Test public void findByid() throws IOException { GetRequest request=new GetRequest(index,type,"1"); GetResponse rsp=client.get(request, RequestOptions.DEFAULT); System.out.println(rsp.getSourceAsMap()); }
2.3.2ids查询
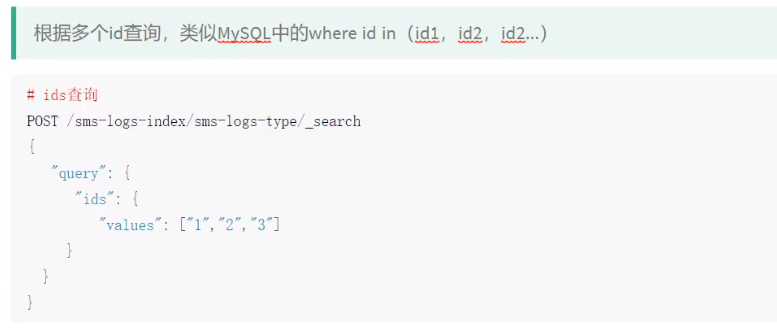
@Test public void findByids() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.idsQuery().addIds("1","2","3")); request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.4prefix查询

上面corpName设置为keyword类型,在内容中存在一个公司的名字为途虎旅游,现在不管使用term或者match查询,因为keyword存储不做分词,所以要查询途虎旅游
必须是全部的途虎旅游
但是使用前缀,只要按照上面就可以把以途虎开头的给查询出来
Test public void findByPrefix() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.prefixQuery("corpName","恭喜")); request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.5fuzzy查询
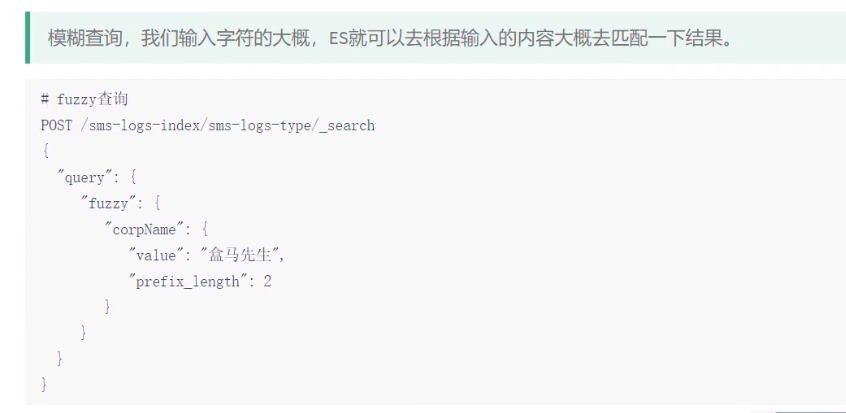
corPname为盒马鲜生,但是查询的时候不小心把字写成了盒马先生,使用fuzzy也是能够查询出来的,prefix_length设置为2表示查询的时候前两个字符不能存在错误
不能写错
@Test public void findByfuzzy() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.fuzzyQuery("corpName","恭喜您").prefixLength(2)); request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.6wildcard查询
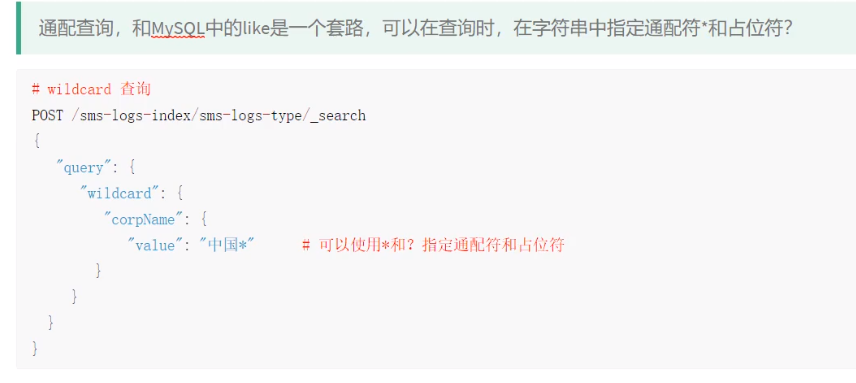
@Test public void findByWildcard() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.wildcardQuery("corpName","恭喜*")); request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.7range查询

@Test public void findByrange() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.rangeQuery("fee").gte(5).lte(10)); builder.size(20);//ES默认查询10条数据 request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.7regexp查询
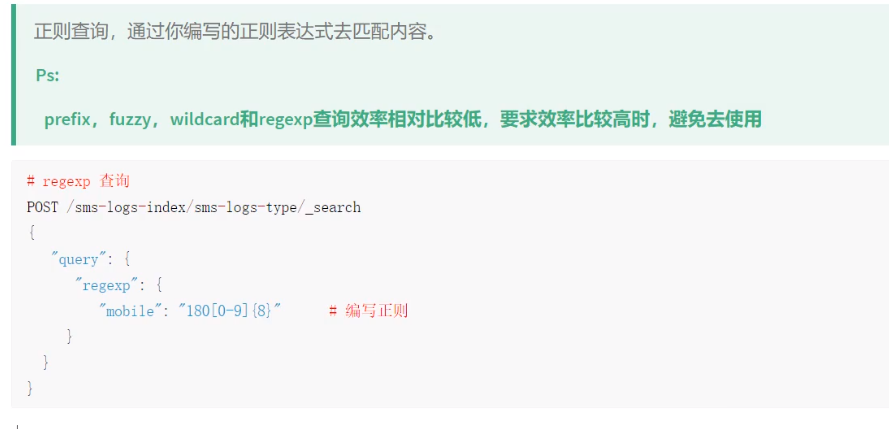
注意:正则查询、前缀查询、模糊查询查询的效率都很低,避免要去使用
@Test public void findByRegexp() throws IOException { SearchRequest request=new SearchRequest(index); request.types(type); SearchSourceBuilder builder=new SearchSourceBuilder(); builder.query(QueryBuilders.regexpQuery("mobile","123[0-9]{8}")); builder.size(20);//ES默认查询10条数据 request.source(builder); SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); for (SearchHit hit: rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }
2.8深分页Scroll
一、深度分页方式from + size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询
GET /student/student/_search 2 { 3 "query":{ 4 "match_all": {} 5 }, 6 "from":5000, 7 "size":10 8 }
from+size查询的原理为
1.client发送分页查询请求到node1(coordinating node)上,node1建立一个大小为from+size的优先级队列来存放查询结果;
2.node1将请求广播到涉及到的shards上;
3.每个shards在内部执行查询,把from+size条记录存到内部的优先级队列(top N表)中;
4.每个shards把缓存的from+size条记录返回给node1;
5.node1获取到各个shards数据后,进行合并并排序,选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。
列如现在有3个es的节点

生产上面一定要配置master节点、data节点和client节点
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点 通过node.name指定节点的名称。 在Elasticsearch中,节点的类型主要有4种: master节点 配置文件中node.master属性为true(默认为true),就有资格被选为master节点。 master节点用于控制整个集群的操作。比如创建或删除索引,管理其它非master节点等。 data节点 配置文件中node.data属性为true(默认为true),就有资格被设置成data节点。 data节点主要用于执行数据相关的操作。比如文档的CRUD。 客户端节点 配置文件中node.master属性和node.data属性均为false。 北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090该节点不能作为master节点,也不能作为data节点。 可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点 部落节点集群节点用于跨集群查询 当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行 搜索和其他操作。
在生产环境下,如果不修改elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。
客户端节点的作用:
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个 client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
ElasticSearch: master,data,client三类节点区别及节点分配简单例举
默认情况下,ES集群节点都是混合节点,即在elasticsearch.yml中默认node.master: true和node.data: true。
当ES集群规模达到一定程度以后,就需要注意对集群节点进行角色划分。
ES集群节点可以划分为三种:主节点、数据节点和客户端节点。
这是一种分而治之的思想,也是一种术业专攻的体现。
三类节点说明
master - 主节点:
elasticsearch.yml-
node.master: true node.data: false
- 主要功能:维护元数据,管理集群节点状态;不负责数据写入和查询。
- 配置要点:内存可以相对小一些,但是机器一定要稳定,最好是独占的机器。
data - 数据节点:elasticsearch.yml:-
node.master: false node.data: true
-
- 主要功能:负责数据的写入与查询,压力大。
- 配置要点:大内存,最好是独占的机器。
client - 客户端节点:elasticsearch.yml-
node.master: false node.data: false
- 主要功能:负责任务分发和结果汇聚,分担数据节点压力。
- 配置要点:大内存,最好是独占的机器
mixed- 混合节点(不建议):elasticsearch.yml:-
node.master: true node.data: true
-
主要功能:综合上述三个节点的功能。 配置要点:大内存,最好是独占的机器。 特别说明:不建议这种配置,节点容易挂掉。
-
其他说明
- 虽然上面章节中,未对单个服务器的磁盘大小进行要求,但是整体ES集群的总磁盘大小要保证足够。
-
简单举例 假定共计20台机器,则可以按照如下配置: 节点类型 机器数量 内存大小 其他 master 3 16GB 机器必须稳定 data 12 31GB 无 client 5 31GB 无 以上,只是简单的举例,可根据实际情况调节。
总结
默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求。在一个生产集群中我们可以对这些节点的职责进行划分。
建议集群中设置 3台 以上的节点作为 master 节点【node.master: true node.data: false】,这些节点只负责成为主节点,维护整个集群的状态。
再根据数据量设置一批 data节点【node.master: false node.data: true】,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大
所以在集群中建议再设置一批 client节点【node.master: false node.data: true】,这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。master节点:普通服务器即可(CPU 内存 消耗一般)
data 节点:主要消耗磁盘,内存
client 节点:普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点) - 列如client节点,在做from+size深度分页查询的时候,对各个子节点的数据需要做聚合,聚合的数据都是放在内存上面的,所以一定要将client节点的内存设置大一点
- 博客这两篇文章要重点看下:
- https://blog.csdn.net/hanchao5272/article/details/102790741
- http://www.bubuko.com/infodetail-2243432.html
接下来,我们继续es的深度分页的问题
其次:es为了性能,限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;也就是说我们不能分页到10000条数据以上。
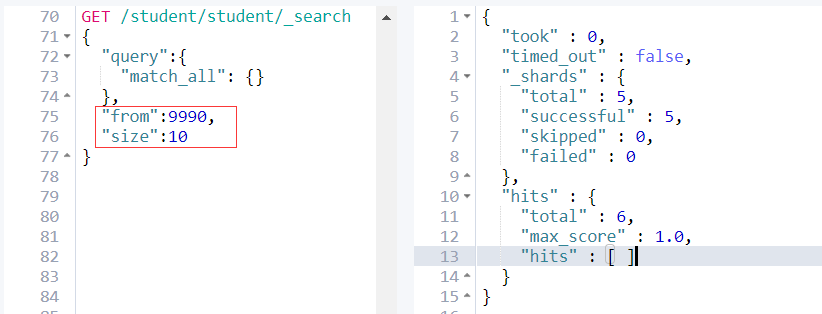
from + size <= 10000所以这个分页深度依然能够执行。
继续看上图,当size + from > 10000;es查询失败,并且提示

在后面的请求中我们都要带着这个 scroll_id 去请求。
POST /sms-logs-index/sms-logs-type/_search?scroll=1m { "query": { "match_all": {} }, "size":2, "sort": [ { "fee": { "order": "desc" } } ] }
现在这个索引中共有6条数据,id分别为 1, 2, 3, 4, 5, 6。当我们使用 scroll 查询第4次的时候,返回结果应该为空。这时我们就知道已经结果集已经匹配完了。
我们来看看执行的情况
第一次执行的代码为
POST /sms-logs-index/sms-logs-type/_search?scroll=1m { "query": { "match_all": {} }, "size":2, "sort": [ { "fee": { "order": "desc" } } ] }
查询的结果会返回2条记录,并且对应一个scoll_id的字段
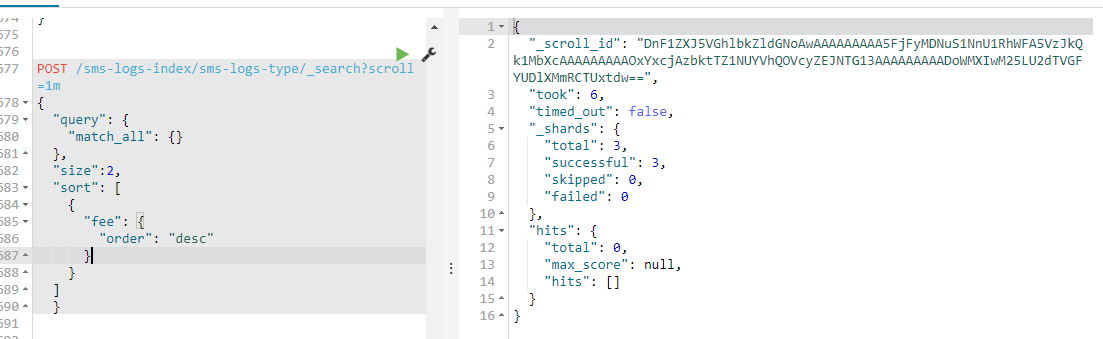
第2次查询的时候,我们需要将第一次的生产的scoll_id带上,查询出id 为 3 4 的两条记录
GET _search/scroll { "scroll_id": "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAAA2FjFyMDNuS1NnU1RhWFA5VzJkQk1MbXcAAAAAAAAANxYxcjAzbktTZ1NUYVhQOVcyZEJNTG13AAAAAAAAADgWMXIwM25LU2dTVGFYUDlXMmRCTUxtdw==", "scroll": "1m" }
注意点2:
使用scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是有问题的。每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
scoll是基于历史数据快照进行搜索的,如果存储的数据不断的发送变化,那么就要不断的更新快照信息
一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors(游标)。
执行如下curl,每次请求两条。可以定制 scroll = 5m意味着该窗口过期时间为5分钟。
scroll能够解决深度分页的问题,但是其无法实现实时查询,即当scroll_id生成后无法查询到之后数据的变更,因为其底层原理是生成数据的快照
这时 search_after应运而生。其是在es-5.X之后才提供的。
search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
为了演示,我们需要给上文中的student索引增加一个uid字段表示其唯一性。
执行如下查询:
GET /student/student/_search { "query":{ "match_all": {} }, "size":2, "sort":[ { "uid": "desc" } ] }
结果集:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 6, "max_score" : null, "hits" : [ { "_index" : "student", "_type" : "student", "_id" : "6", "_score" : null, "_source" : { "uid" : 1006, "name" : "dehua", "age" : 27, "class" : "3-1" }, "sort" : [ 1006 ] }, { "_index" : "student", "_type" : "student", "_id" : "5", "_score" : null, "_source" : { "uid" : 1005, "name" : "fucheng", "age" : 23, "class" : "2-3" }, "sort" : [ 1005 ] } ] } }
最后一条记录的uid为1005
GET /student/student/_search { "query":{ "match_all": {} }, "size":2, "search_after":[1005], "sort":[ { "uid": "desc" } ] }
这样我们就使用search_after方式实现了分页查询。



接下来我们使用java代码来操作scorrl的代码
package com.qf.test; import com.fasterxml.jackson.databind.ObjectMapper; import com.qf.utils.ESClient; import org.elasticsearch.action.search.*; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.Scroll; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.sort.SortOrder; import org.junit.Test; import java.io.IOException; public class Demo7 { ObjectMapper mapper=new ObjectMapper(); RestHighLevelClient client = ESClient.getClient(); String index="sms-logs-index"; String type="sms-logs-type"; @Test public void scrollQuery() throws IOException { //1.创建SearchRrequest对象 SearchRequest request = new SearchRequest(index); request.types(type); //2.指定scroll信息 request.scroll(TimeValue.timeValueMinutes(1L)); //3.指定查询条件 SearchSourceBuilder builder=new SearchSourceBuilder(); builder.size(4); builder.sort("fee", SortOrder.DESC); builder.query(QueryBuilders.matchAllQuery()); request.source(builder); //4.获取返回结果scrollId,source SearchResponse rsp= client.search(request, RequestOptions.DEFAULT); String scrollId=rsp.getScrollId(); System.out.println("---------首页--------"); for (SearchHit hit:rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } //5.循环/创建SearchScrollRequest while(true) { SearchScrollRequest searchScrollRequest=new SearchScrollRequest(scrollId); //6.指定scrollId生存时间 searchScrollRequest.scroll(TimeValue.timeValueMinutes(1L)); //7.执行查询返回的结果 SearchResponse scrollRsp=client.scroll(searchScrollRequest,RequestOptions.DEFAULT); //8.判断是否查询到了数据,输出 SearchHit[] hits =scrollRsp.getHits().getHits(); if (hits!=null&& hits.length >0){ System.out.println("----------下一页------------"); for (SearchHit hit:rsp.getHits().getHits()) { System.out.println(hit.getSourceAsMap()); } }else{ //9.判断没有查询到的数据-退出循环 System.out.println("-------------结束-------------"); break; } } //10.创建ClearScrollRequest ClearScrollRequest clearScrollRequest=new ClearScrollRequest(); //11.指定scrollId clearScrollRequest.addScrollId(scrollId); //12.删除scrollId ClearScrollResponse clearScrollResponse= client.clearScroll(clearScrollRequest,RequestOptions.DEFAULT); //13输出结果 System.out.println("删除scrollId:" +clearScrollResponse.isSucceeded()); } }
代码相当的经典呀
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点
通过node.name指定节点的名称。
在Elasticsearch中,节点的类型主要有4种:
master节点
配置文件中node.master属性为true(默认为true),就有资格被选为master节点。
master节点用于控制整个集群的操作。比如创建或删除索引,管理其它非master节点等。
data节点
配置文件中node.data属性为true(默认为true),就有资格被设置成data节点。
data节点主要用于执行数据相关的操作。比如文档的CRUD。
客户端节点
配置文件中node.master属性和node.data属性均为false。
北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
该节点不能作为master节点,也不能作为data节点。
可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点
部落节点
当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行
搜索和其他操作。
接下来我们继续下面看看下面的研究
内容可以参考下面的字段:
https://www.cnblogs.com/clarehjh/archive/2004/01/13/13689906.html
2.9delete-by-query
注意点:官方不建议
因为效率比较低,官方建议如果有10条文档,你要删除8条,保留2条记录,不如直接新建立一个索引,把保留的2条索引保存到新建的索引中
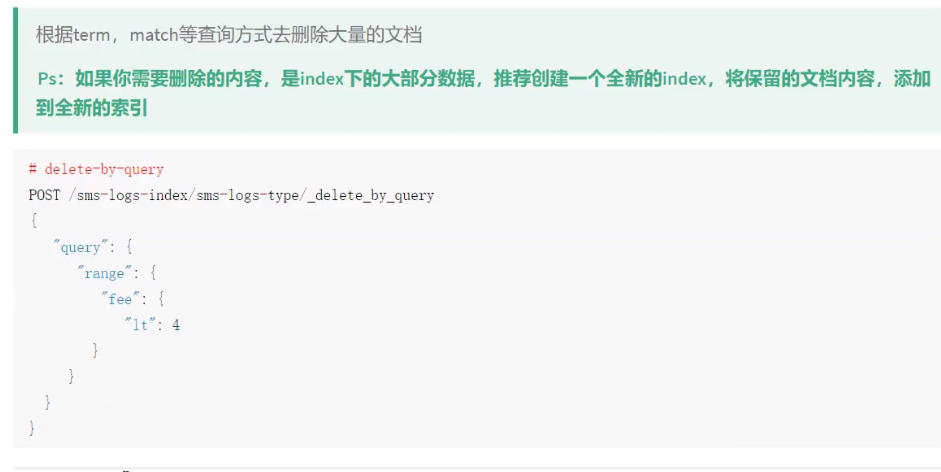
我们插入点数据
PUT sms-logs-index/sms-logs-type/1 { "corpName":"途虎养车", "createDate":"2020-01-22", "fee":3, "ipAddr":"10.123.98.1", "longCode":106900000009, "mobile":18780278756, "operatorId":1, "province":"四川", "replyTotal":10, "sendDate":"2020-01-22", "smsContent":"【途虎养车】亲爱的旧居茫水东降级就", "state":0 }
@Test public void deleteByQuery() throws IOException { //1.创建deleteByQueryRequest DeleteByQueryRequest request=new DeleteByQueryRequest(index); request.types(type); //2.指定索引的条件(和SearchRequest指定query方式不一样) request.setQuery(QueryBuilders.rangeQuery("fee").lt(6)); //3.执行删除 BulkByScrollResponse resp =client.deleteByQuery(request, RequestOptions.DEFAULT); //4.返回结果 System.out.println(resp.toString()); }

我们来做下面的一个查询
我们来看下具体的代码
POST /sms-logs-index/sms-logs-type/_search { "query":{ "bool":{ "should": [ { "term": { "province": { "value": "北京" } } }, { "term": { "province": { "value": "南通" } } } ], "must_not": [ { "term": { "operatorId": { "value": "2" } } } ], "must": [ { "match": { "smsContent": "恭喜" } }, { "match": { "smsContent": "黑卡" } } ] } } }
我们来看下具体的代码
@Test public void boolQuery() throws IOException { //1.创建SearchRequest SearchRequest request=new SearchRequest(index); request.types(type); //2.查询条件 SearchSourceBuilder builder=new SearchSourceBuilder(); BoolQueryBuilder boolQuery=QueryBuilders.boolQuery(); boolQuery.should(QueryBuilders.termQuery("province","北京")); boolQuery.should(QueryBuilders.termQuery("province","南京")); boolQuery.mustNot(QueryBuilders.termQuery("OperatorId","2")); boolQuery.must(QueryBuilders.matchQuery("smsContent","高级")); boolQuery.must(QueryBuilders.matchQuery("smsContent","黑卡")); builder.query(boolQuery); request.source(builder); //3.查询 SearchResponse rsp=client.search(request, RequestOptions.DEFAULT); //4.输出结果 for (SearchHit hit:rsp.getHits().getHits() ) { System.out.println(hit.getSourceAsMap()); } }
它接受一个positive查询和一个negative查询。只有匹配了positive查询的文档才会被包含到结果集中,但是同时匹配了negative查询的文档会被降低其相关度,通过将文档原本的_score和negative_boost参数进行相乘来得到新的_score。
因此,negative_boost参数必须小于1.0。在上面的例子中,任何包含了指定负面词条的文档的_score都会是其原本_score的一半。

POST /sms-logs-index/sms-logs-type/_search { "query": { "boosting": { "positive": { "match": { "corpName": "天下" } }, "negative": { "match": { "smsContent": "途牛" } }, "negative_boost": 0.5 } } }
上面这个案例就是搜索的结果中必须包含公司的名称是天下,并且如果发现smsContent中内容如果包含途牛两个字,将降低文档的分数值,新的分数值为原来的分数值乘以0.2
@Test public void BoostingQuery() throws IOException { //1.创建SearchRequest SearchRequest request = new SearchRequest(index); request.types(type); //2.查询条件 SearchSourceBuilder builder = new SearchSourceBuilder(); BoostingQueryBuilder boostingQueryBuilder = QueryBuilders.boostingQuery( QueryBuilders.matchQuery("smsContent", "高级"), QueryBuilders.matchQuery("smsContent", "黑卡") ).negativeBoost(0.5f); builder.query(boostingQueryBuilder); request.source(builder); SearchResponse rsp = client.search(request, RequestOptions.DEFAULT); //4.输出结果 for (SearchHit hit : rsp.getHits().getHits() ) { System.out.println(hit.getSourceAsMap()); } }
3.1filter查询


2、filter与query对比大解密
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响。
query,会计算每个document相对于搜索条件的相关度,并按照相关度进行排序。
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query;如果你只是要根据一些条件筛选出一部分数据,不关注排序,那么使用filter。
3、filter和query性能对比
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的机制,自动cache最常使用filter的数据。
query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果。
首先先介绍bool支持下面的几种类型:Bool查询现在包括四种子句,must,filter,should,must_not。
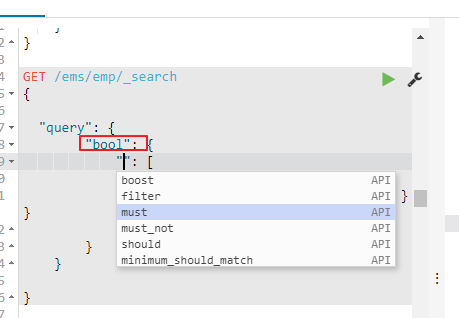
第一种:bool中只使用must
GET /ems/emp/_search { "query": { "bool": { "must": [ { "match": { "name": "黑" } }, { "range": { "age": { "gte": 4, "lte": 50 } } } ] } } }
首先弄下层次结构:
bool下面查询要使用query
bool下面可以有must、filter等组合,现在上面单独只使用了must
must必须是里面的条件是and的关系,现在must里面有两个条件,多个条件之间必须使用[]
第一个条件是name必须包含黑,第二个是年龄在3到50岁
我们来看下查询的效果
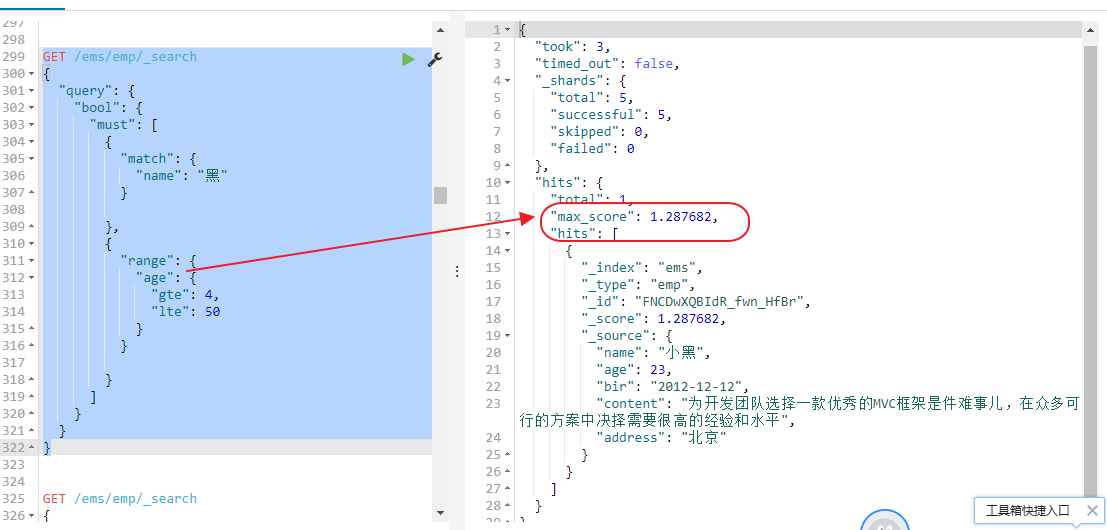
我们看到查询出来是存在score的,我们也可以使用filter,直接将must换成filter就可以了
GET /ems/emp/_search { "query": { "bool": { "filter": [ { "match": { "name": "黑" } }, { "range": { "age": { "gte": 4, "lte": 50 } } } ] } } }
我们来看下效果
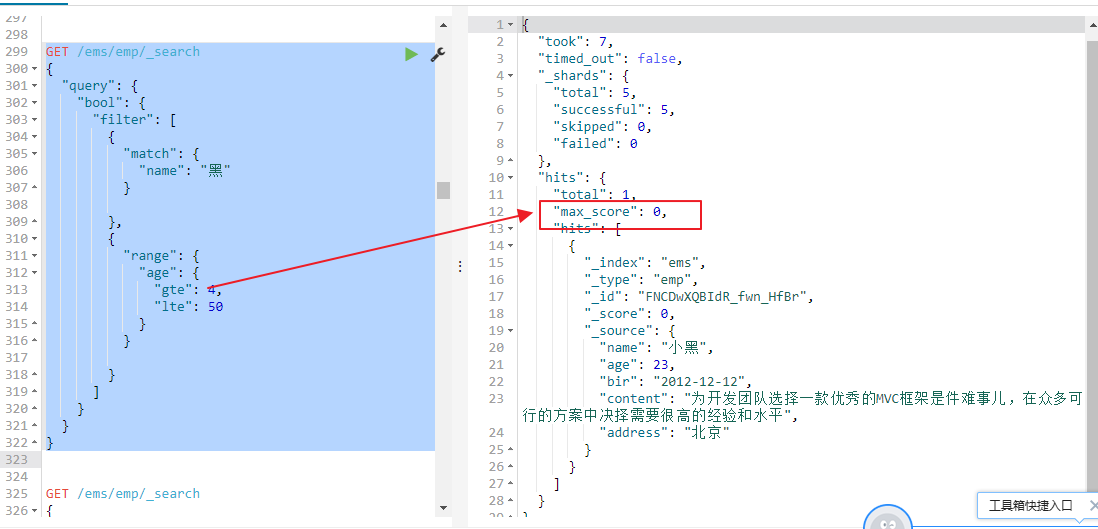
我们可以看到filte可以查询出数据,但是对于的score的分数是0
第三种方案,我们可以将range范围查询放在filter中进行过滤
。让must和filter进行组合查询
GET /ems/emp/_search { "query": { "bool": { "must": [ { "term": { "name": { "value": "黑" } } }, { "term": { "name": { "value": "小" } } } ], "filter": [ { "term": { "name": { "value": "小" } } }, { "term": { "name": { "value": "小" } } } ] } } }
语法结构如下所示:
{ "query": { "bool": { "must": [{},...], "filter": [{},...],... } } }
filter在集合查询的时候可以用来范围的过滤,列如要查询名字包含黑字,年龄在10岁到500岁之间的,对于范围查询我们可以使用filter对范围进行过滤,这样效率高,并且查询中也存在must,查询处理的结果也存在分数排序,我们来看下效果
GET /ems/emp/_search { "query": { "bool": { "must": [ { "term": { "name": { "value": "黑" } } } ], "filter": [ { "range": { "age": { "gte": 10, "lte": 200 } } } ] } } }
查询的结果为
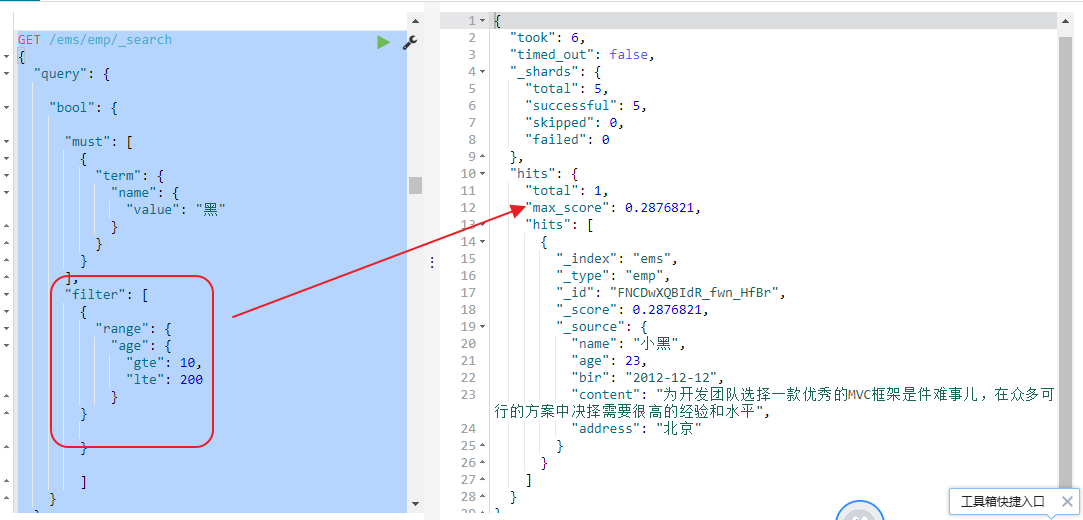
使用filter进行过滤能够提高查询效率,上面的查询方式在数据量大的情况下,比下面的这种查询效率高
GET /ems/emp/_search { "query": { "bool": { "must": [ { "term": { "name": { "value": "黑" } } }, { "range": { "age": { "gte": 10, "lte": 200 } } } ] } } }
2 filter与query的区别
filter和query一起使用时, 会先执行filter.
2.1 相关度处理上的不同
filter —— 只根据搜索条件过滤出符合的文档, 将这些文档的评分固定为1, 忽略TF/IDF信息, 不计算相关度分数;
query —— 先查询符合搜索条件的文档, 然后计算每个文档对于搜索条件的相关度分数, 再根据评分倒序排序.
建议:
如果对搜索结果有排序的要求, 要将最匹配的文档排在最前面, 就用query;
如果只是根据一定的条件筛选出部分数据, 不关注结果的排序, 就用filter.
2.2 性能上的对比
filter 性能更好, 无排序 —— 不计算相关度分数, 不用根据相关度分数进行排序, 同时ES内部还会缓存(cache)比较常用的filter的数据 (使用bitset <0或1> 来记录包含与否).
query 性能较差, 有排序 —— 要计算相关度分数, 要根据相关度分数进行排序, 并且没有cache功能.
2.3 对比结论
业务关心的、需要根据匹配的相关度进行排序的搜索条件 放在 query 中;
业务不关心、不需要根据匹配的相关度进行排序的搜索条件 放在 filter 中.