
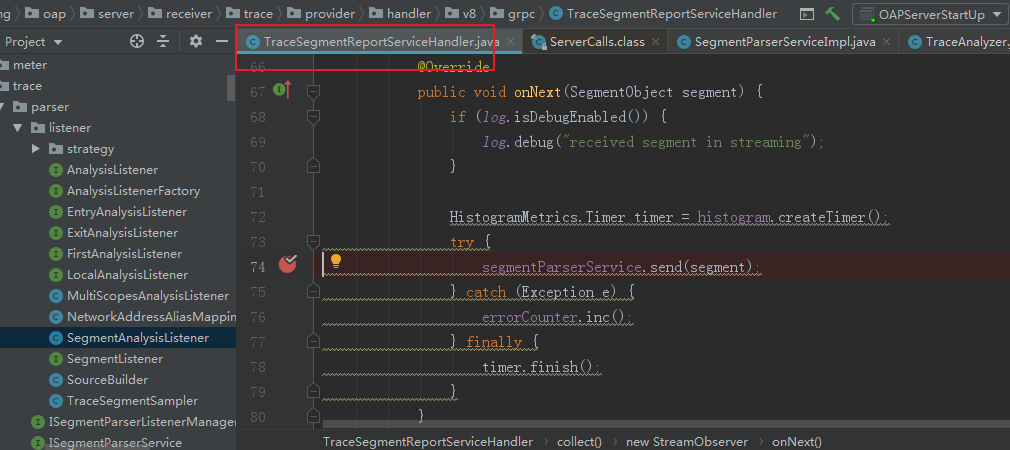
接下来会进入下面的代理处理TraceSegment
接下来会调用到TraceAnalyzer的doAnalysis方法,代码如下
public void doAnalysis(SegmentObject segmentObject) { if (segmentObject.getSpansList().size() == 0) { return; } createSpanListeners(); try { notifySegmentListener(segmentObject); segmentObject.getSpansList().forEach(spanObject -> { if (spanObject.getSpanId() == 0) { notifyFirstListener(spanObject, segmentObject); } if (SpanType.Exit.equals(spanObject.getSpanType())) { notifyExitListener(spanObject, segmentObject); } else if (SpanType.Entry.equals(spanObject.getSpanType())) { notifyEntryListener(spanObject, segmentObject); } else if (SpanType.Local.equals(spanObject.getSpanType())) { notifyLocalListener(spanObject, segmentObject); } else { log.error("span type value was unexpected, span type name: {}", spanObject.getSpanType() .name()); } }); notifyListenerToBuild(); } catch (Throwable e) { log.error(e.getMessage(), e); } }
我们首先来看方法的第一个业务逻辑createSpanListeners(),改方法主要产生处于TraceSegment。以及各类span的listener,默认情况下产生的listener情况如下
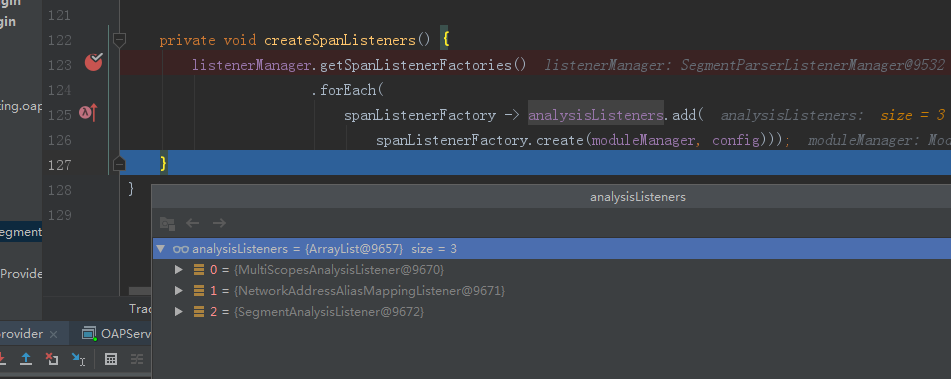
默认情况下产生上面三个listener
1、SegmentAnalysisListener主要是处理TraceSegment,将整个TraceSegment转行成segement对象存储到数据库中
2、MultiScopesAnalysisListener主要用来处理TraceSegment中的span,依据span的不同类型进行单独处理,然后依据不同的span类型产生不同的指标信息
这是收到的skywalking的出
skywalking后端oap集群收到TraceSegment的处理信息之后,会进行处理,这里处理会对TraceSegment中保存的span进行分类,span分为下面的几种类型
enum Point { Entry, Exit, Local, First, Segment }
每一种类型会对应一个listen处理器与之对应,经过处理器处理之后,在延伸到后续的流程和操作
五个listen的类型如下面所示
代码中创建了三个listener情况如下
接下来我们分析完成了createSpanListeners();接下来是执行
notifySegmentListener(segmentObject);我们来看下改方法是如何进行处理的
private void notifySegmentListener(SegmentObject segmentObject) { analysisListeners.forEach(listener -> { if (listener.containsPoint(AnalysisListener.Point.Segment)) { ((SegmentListener) listener).parseSegment(segmentObject); }能够 }); }
在上面创建的三个listener中只有SegmentAnalysisListener能够处理TraceSegment,我们来看下后面的代码

@Override public void parseSegment(SegmentObject segmentObject) { segment.setTraceId(segmentObject.getTraceId()); segmentObject.getSpansList().forEach(span -> { if (startTimestamp == 0 || startTimestamp > span.getStartTime()) { startTimestamp = span.getStartTime(); } if (span.getEndTime() > endTimestamp) { endTimestamp = span.getEndTime(); } isError = isError || segmentStatusAnalyzer.isError(span); appendSearchableTags(span); }); final long accurateDuration = endTimestamp - startTimestamp; duration = accurateDuration > Integer.MAX_VALUE ? Integer.MAX_VALUE : (int) accurateDuration; if (sampleStatus.equals(SAMPLE_STATUS.UNKNOWN) || sampleStatus.equals(SAMPLE_STATUS.IGNORE)) { if (sampler.shouldSample(segmentObject.getTraceId())) { sampleStatus = SAMPLE_STATUS.SAMPLED; } else if (isError && forceSampleErrorSegment) { sampleStatus = SAMPLE_STATUS.SAMPLED; } else if (traceLatencyThresholdsAndWatcher.shouldSample(duration)) { sampleStatus = SAMPLE_STATUS.SAMPLED; } else { sampleStatus = SAMPLE_STATUS.IGNORE; } } }
我们来重点看下SegmentAnalysisListener下的parseSegment的方法的流程,方法传入的参数segmentObject的结构体如下
traceId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380005" traceSegmentId: "ec5de79a4a8848e88146ebf696d157dc.73.16092665874590000" spans { parentSpanId: -1 startTime: 1609266587459 endTime: 1609266589471 refs { traceId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380005" parentTraceSegmentId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380004" parentSpanId: 1 parentService: "DEMO-webapp" parentServiceInstance: "e171fdf7a1b4436b8289159e6d3f90b1@192.168.43.80" parentEndpoint: "{GET}/hello/{words}" networkAddressUsedAtPeer: "169.254.122.166:20880" } operationName: "com.xxx.HelloService.say(String)" spanLayer: RPCFramework componentId: 3 tags { key: "url" value: "dubbo://169.254.122.166:20880/com.xxx.HelloService.say(String)" } } service: "DEMO-provider" serviceInstance: "c5ec906d3dd24d0b8907fa8549c8306b@192.168.43.80"
这里首先处理的是dubbo-provider上传的TraceSegment,产生的是一个EntrySpan,改EntrySpan中管理了dubbo-webapp的TraceSegment

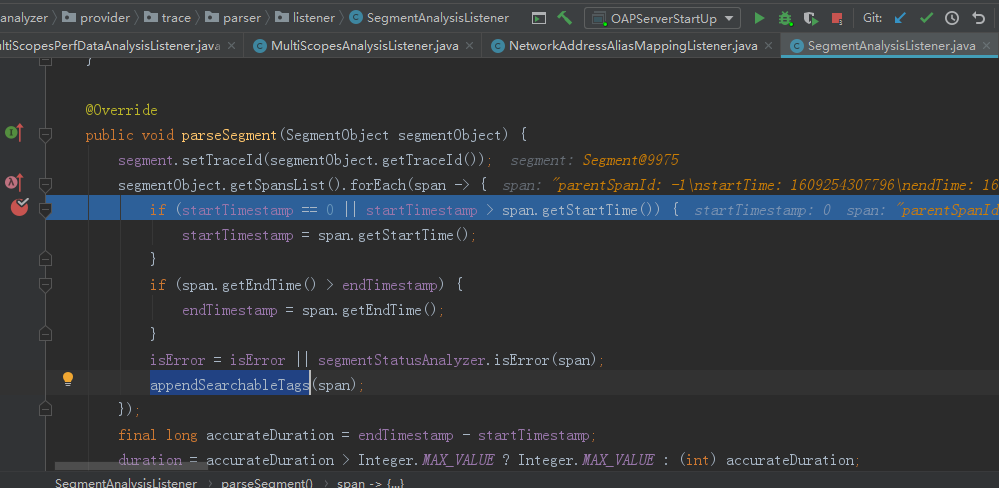
这里在处理的时候如果当前的TraceSegment中存在5个span,那么当前TraceSegment的开始时间等于5个span中最小的starttime时间,最大时间为5个span中最大的endTime的时间,如果当前的TraceSegment中只要存在一个span的熟悉中为iserror,则改TraceSegment就为false
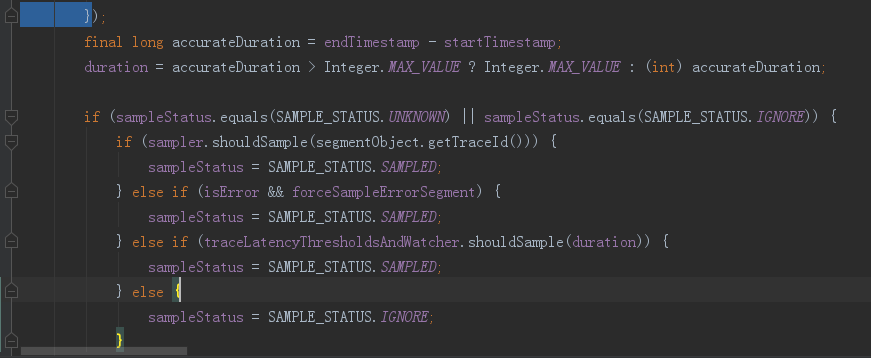
这个代码是判断当前的TraceSegment是否被采用处理了,如果被采样了就可以存储到数据库中,如果没有采用改TraceSegment就丢弃不用做任何处理
notifySegmentListener(segmentObject);本质上就是将后端上传的TraceSegment转化成一个segment对象
接下来继续执行
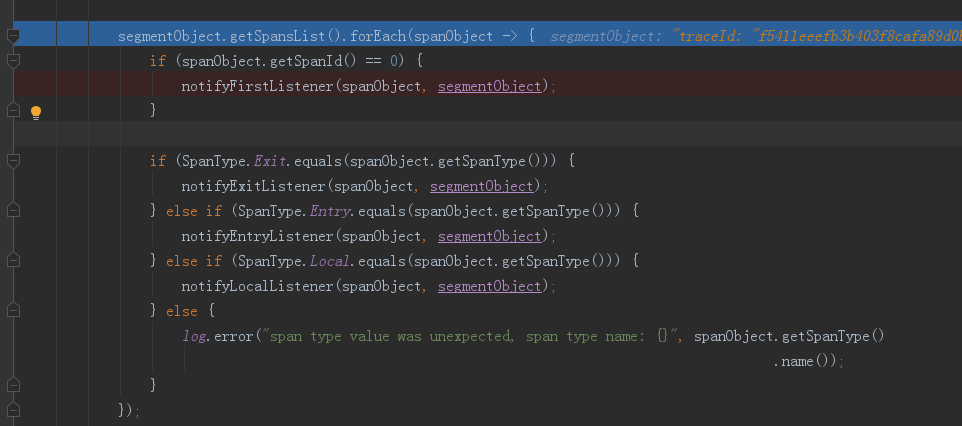
取出当前TraceSegment中的span列表,然后对没有span进行判断,判断当前的span是EntrySpan、localspan、exitspan,依据不同的span传递给不同的listener进行处理
这里当前的TraceSegment中只有一个span
span的对象为
parentSpanId: -1 startTime: 1609266587459 endTime: 1609266589471 refs { traceId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380005" parentTraceSegmentId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380004" parentSpanId: 1 parentService: "DEMO-webapp" parentServiceInstance: "e171fdf7a1b4436b8289159e6d3f90b1@192.168.43.80" parentEndpoint: "{GET}/hello/{words}" networkAddressUsedAtPeer: "169.254.122.166:20880" } operationName: "com.xxx.HelloService.say(String)" spanLayer: RPCFramework componentId: 3 tags { key: "url" value: "dubbo://169.254.122.166:20880/com.xxx.HelloService.say(String)" }
因为当前的span为EntrySpan,对应的spanID值就是0,会被下面的listener进行处理

notifyFirstListener(spanObject, segmentObject);底层会调用SegmentAnalysisListener的parseFirst方法,我们来看下改方法的业务逻辑
@Override public void parseFirst(SpanObject span, SegmentObject segmentObject) { if (sampleStatus.equals(SAMPLE_STATUS.IGNORE)) { return; } if (StringUtil.isEmpty(serviceId)) { serviceName = namingControl.formatServiceName(segmentObject.getService()); serviceId = IDManager.ServiceID.buildId( serviceName, NodeType.Normal ); } long timeBucket = TimeBucket.getRecordTimeBucket(startTimestamp); segment.setSegmentId(segmentObject.getTraceSegmentId()); segment.setServiceId(serviceId); segment.setServiceInstanceId(IDManager.ServiceInstanceID.buildId( serviceId, namingControl.formatInstanceName(segmentObject.getServiceInstance()) )); segment.setLatency(duration); segment.setStartTime(startTimestamp); segment.setTimeBucket(timeBucket); segment.setEndTime(endTimestamp); segment.setIsError(BooleanUtils.booleanToValue(isError)); segment.setDataBinary(segmentObject.toByteArray()); segment.setVersion(3); endpointName = namingControl.formatEndpointName(serviceName, span.getOperationName()); endpointId = IDManager.EndpointID.buildId( serviceId, endpointName ); }
1、当前service: "DEMO-provider"我们需要将"DEMO-provider"转行成对应应用id,存储到segment对象中
2、同理应用实例serviceInstance: "c5ec906d3dd24d0b8907fa8549c8306b@192.168.43.80"我们也要转化成对应的应用实例id存储到segement对象中


segement中的timeBucket字段就是当前TraceSegment中span集合中,比较各个span的开始时间,取出最小的时间,最小的时间作为segement的timeBucket
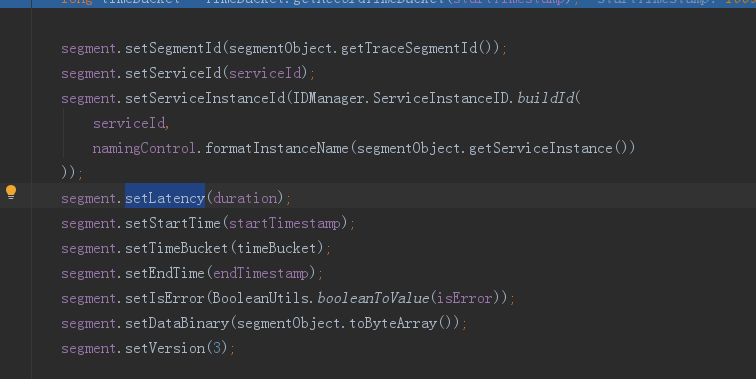
接下来设置segemnt的开始时间,开始时间就是比较各个span的开始时间,取出最小的开始时间作为segemnt的开始时间
segemnt的结束时间结束始时间就是比较各个span的结束时间,取出最大的结束时间作为segemnt的结束时间
整个segemnt的持续时间就是开始时间减去结束时间,此外还将整个segemeOBj对象转化成二进制文件存储在字段setDataBinary中
经过整个parseFirst方法之后,整个segemnt对象的结构为
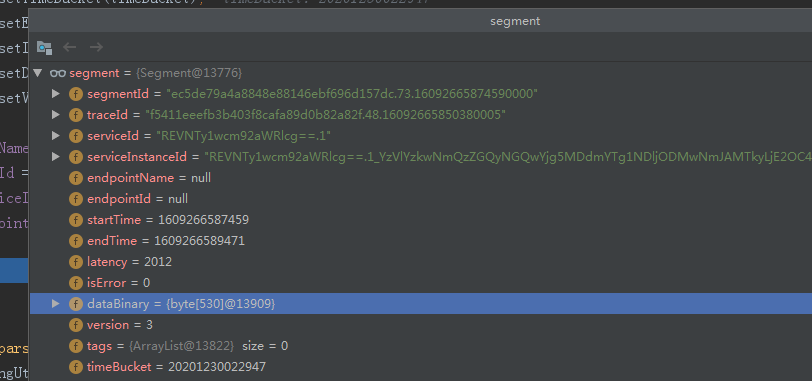
接下来我们继续执行下面的方法
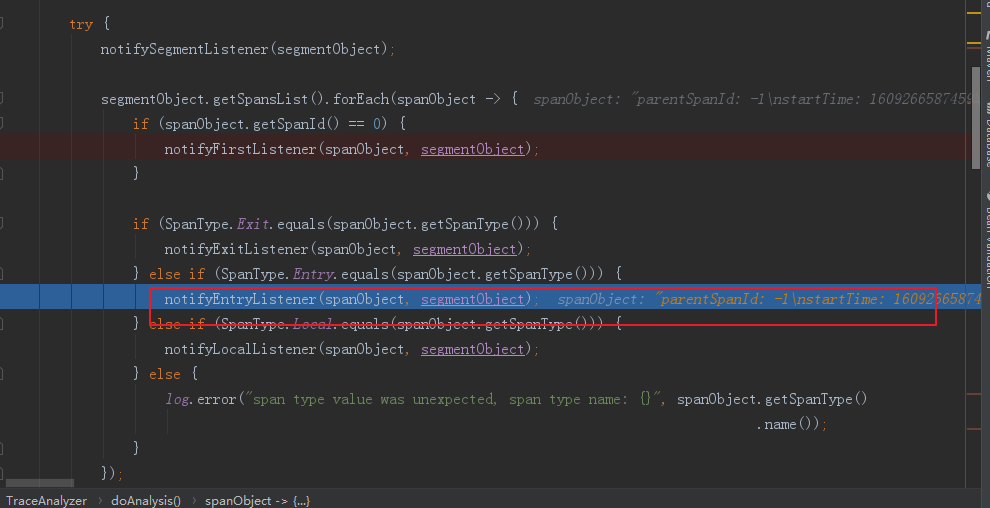
当前的span为EntrySpan,接下来会执行 notifyEntryListener(spanObject, segmentObject);方法



这里MultiScopesAnalysisListener和SegmentAnalysisListener都会对整个EntrySpan进行处理,我们来分析下下面的代码
首先来看下MultiScopesAnalysisListener对parseEntry的方法对EntrySpan的处理
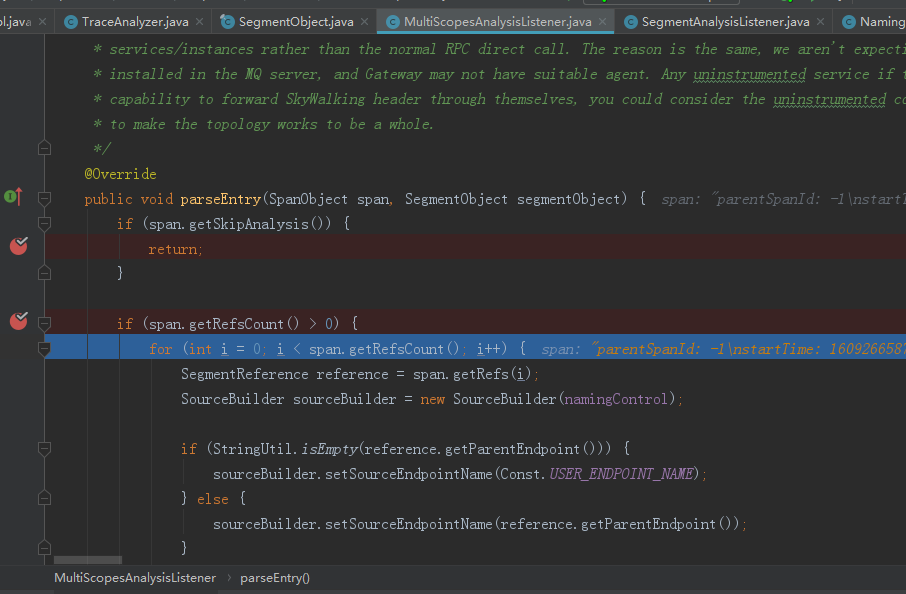
改方法的主要作用是获得当前EntrySpan关联的上游的TraceSegmentRef对象,然后将TraceSegmentRef对象封装到SourceBuilder对象中
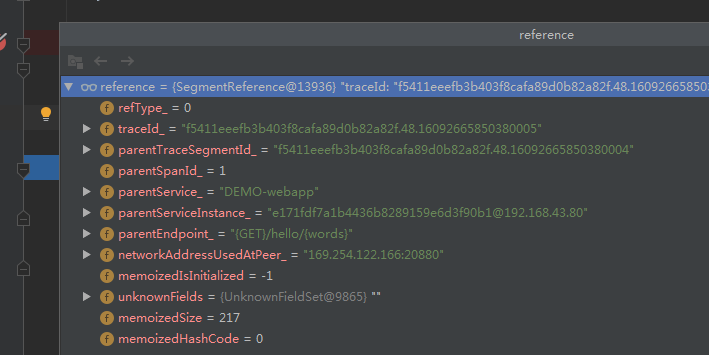
我们先来看下当前EntrySpan中获得的TraceSegmentRef对象的信息如下
traceId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380005" parentTraceSegmentId: "f5411eeefb3b403f8cafa89d0b82a82f.48.16092665850380004" parentSpanId: 1 parentService: "DEMO-webapp" parentServiceInstance: "e171fdf7a1b4436b8289159e6d3f90b1@192.168.43.80" parentEndpoint: "{GET}/hello/{words}" networkAddressUsedAtPeer: "169.254.122.166:20880"
在 SourceBuilder 中记录了上下游两个系统的基础信息,核心字段如下所示:
// 上游系统的 service 信息、serviceInstance 信息以及 Endpoint 信息 @Getter @Setter private int sourceServiceId; @Getter @Setter private String sourceServiceName; @Getter @Setter private int sourceServiceInstanceId; @Getter @Setter private String sourceServiceInstanceName; @Getter @Setter private int sourceEndpointId; @Getter @Setter private String sourceEndpointName; // 下游系统的 service 信息、serviceInstance 信息以及 Endpoint 信息 @Getter @Setter private int destServiceId; @Getter @Setter private String destServiceName; @Getter @Setter private int destServiceInstanceId; @Getter @Setter private String destServiceInstanceName; @Getter @Setter private int destEndpointId; @Getter @Setter private String destEndpointName; // 当前系统的组件类型 @Getter @Setter private int componentId; // 在当前系统中的耗时 @Getter @Setter private int latency; // 当前系统是否发生Error @Getter @Setter private boolean status; @Getter @Setter private int responseCode; // 默认为0 @Getter @Setter private RequestType type; // 请求类型 // 调用关系中的角色,是调用方(Client)、被调用方(Server)还是代理(Proxy) @Getter @Setter private DetectPoint detectPoint; // TraceSegment 起始时间所在分钟级时间窗口 @Getter @Setter private long timeBucket;
这里有一个关键点
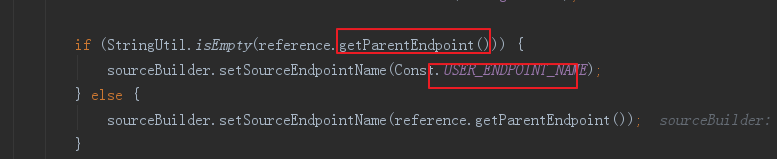
就是如果当前的EntrySpan中没有TraceSegmentRef没有父亲入口,比如dubbo-webapp入口的EntrySpan,在http请求头信息是没有任何信息的,获得的TraceSegmentRef就是为null,这里代码中设置当前的span的sourceBuilder中的 sourceBuilder.setSourceEndpointName(Const.USER_ENDPOINT_NAME);,public static final String USER_ENDPOINT_NAME = "User";的函数表示就是浏览器或者postman等入口调用了dubbo-webapp,作为dubbo-webapp调用的入口
这里dubbo-provider的执行的是else条件,入口的方法就是dubbo-webapp的方法
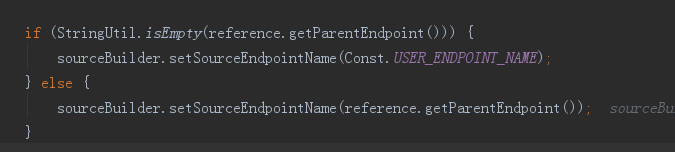
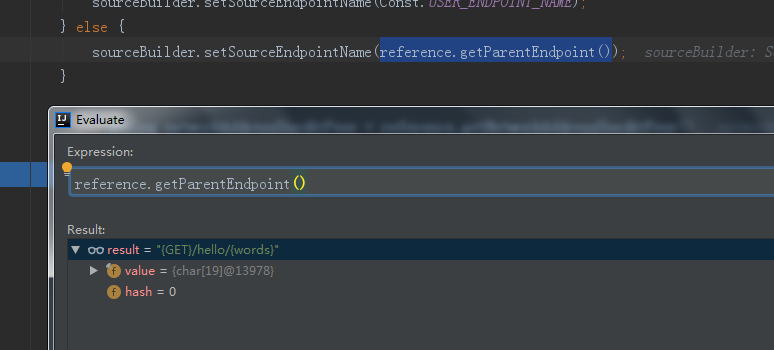
这里设置sourceBuilder的上游节点内容的时候,需要判断上面有MQ类型还是一般应用,这里是一般应用执行下面的else的方法

上游节点的信息设置完成之后,接下来是设置下游的节点信息
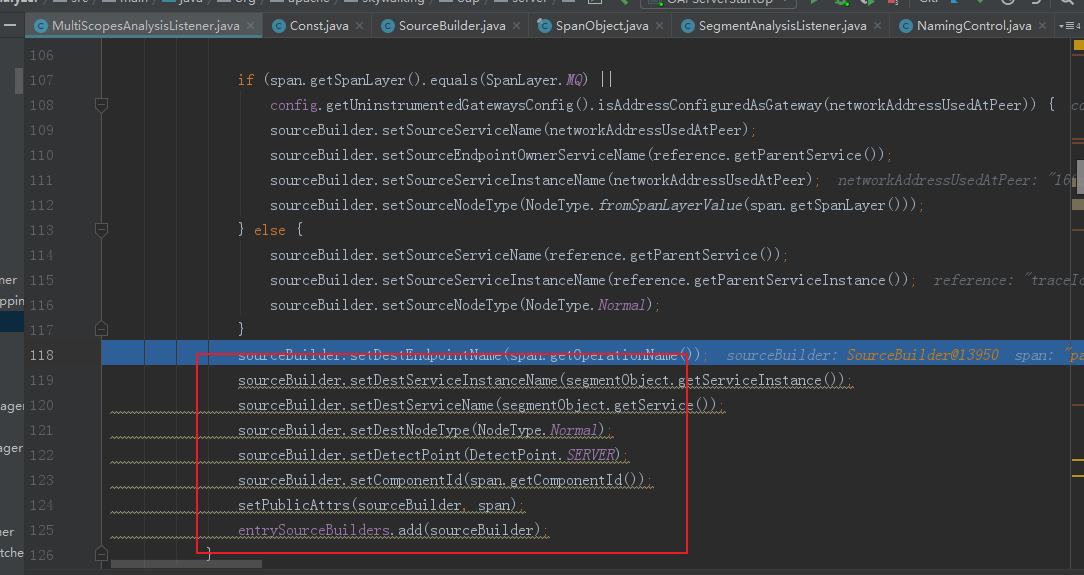
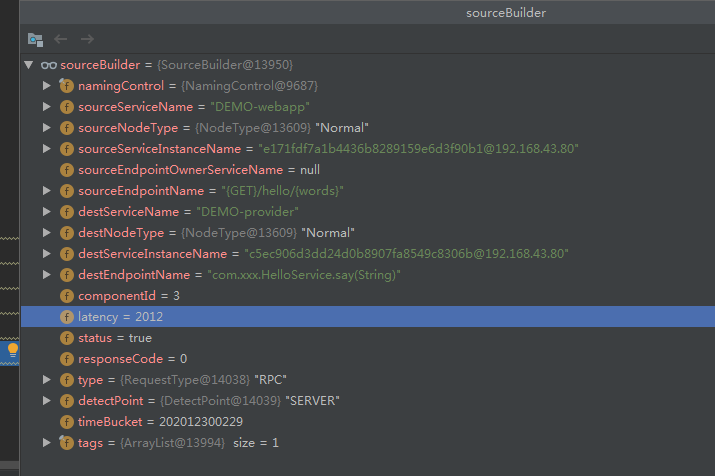
通过这个sourcebuild对象就将当前的EntrySpan和dubb-webapp中产线的exitspan关联起来了,
接下来将创建好的sourceBuilder添加到集合entrySourceBuilders中,后续会进行处理
这里TraceSegment中的span集合中如果存在5个EntrySpan,就会产生5个sourceBuilder对象
接下来继续执行 parseLogicEndpoints(span, segmentObject);

我们来看看 parseLogicEndpoints(span, segmentObject);具体的业务代码,改方法的具体业务逻辑后面再进行分析
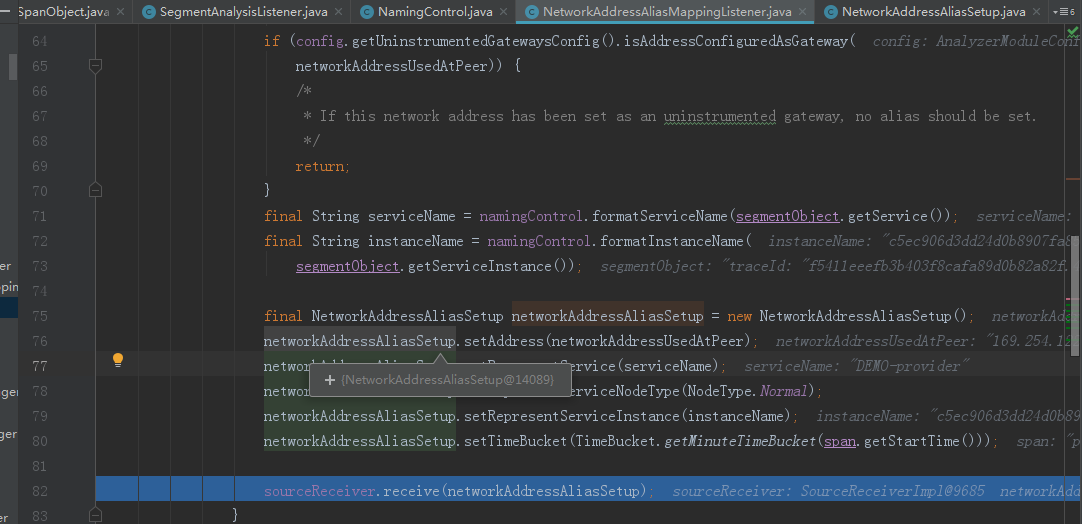
MultiScopesAnalysisListener的parseEntry执行完成之后,接下来执行NetworkAddressAliasMappingListener类的parseEntry方法
我们来看下改方法的具体业务逻辑,就是将当前EntrySpan所在的网络、应用名称、应用实例封装成一个networkAddressAliasSetup对象,然后将这个对象
传递给sourceReceiver进行处理
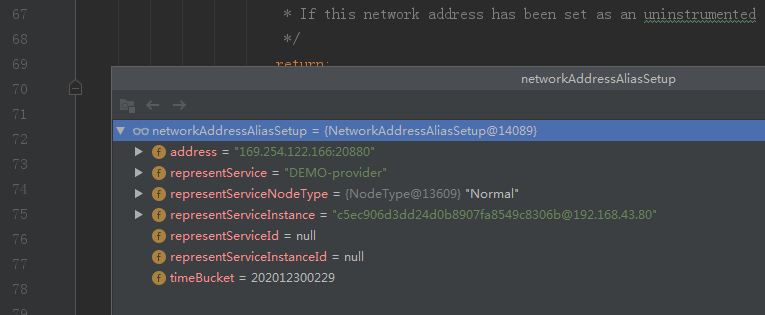
整个networkAddressAliasSetup的结构如下
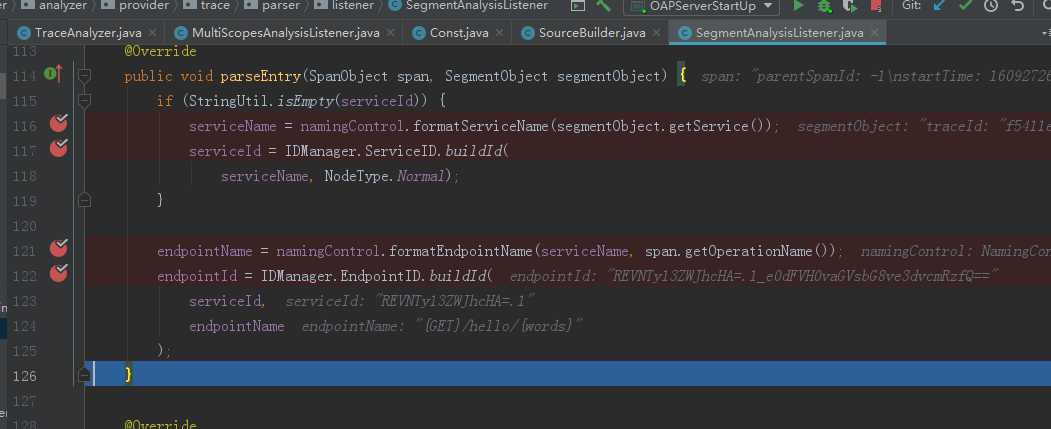
SegmentAnalysisListener的parseEntry方法就是将应用名称应用实例名称转化成对于的id

经过上面的转化之后执行notifyListenerToBuild()方法
private void notifyListenerToBuild() {
analysisListeners.forEach(AnalysisListener::build);
}执行各个listener的build方法,主要是执行SegmentAnalysisListener的build方法和MultiScopesAnalysisListener的build方法
我们先介绍SegmentAnalysisListener的build方法,然后在介绍MultiScopesAnalysisListener的build方法
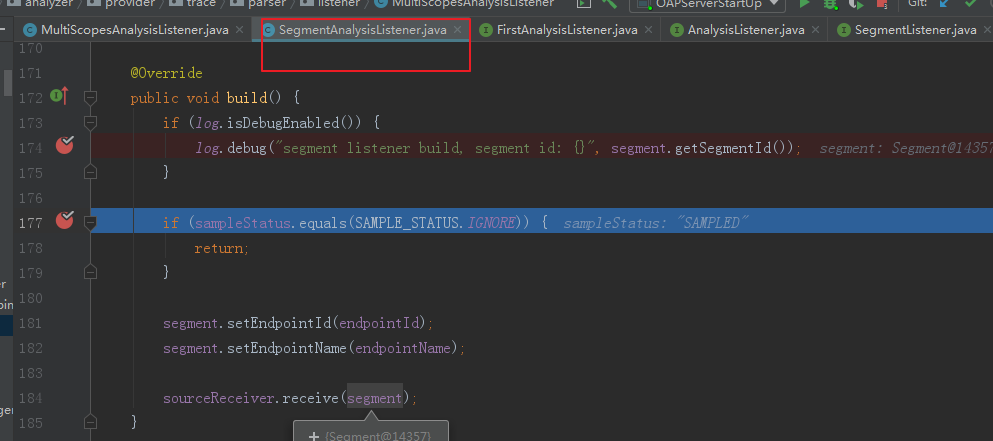
收到判断当前的segment是否是被采样忽略的,如果是被采样忽略的
skywalking后端采样率要设置为一样的原因
一个全局的请求,在dubbo-webapp产生了一个TraceSegmentA,在dubbo-dubbo产生了一个TraceSegmentB,需要有这两个TraceSegment才能还原这一次Trace
TraceSegmentA传递给后端的oap集群的A节点处理,TraceSegmentB传递给后端的oap集群的B节点处理,
如果A节点和B节点在后端的采样率设置不一致,就可能导致TraceSegmentA被处理了存储在es中,TraceSegmentB被忽略直接丢弃,导致无法还原当前请求的trace情况
所以oap集群后端每个节点的采样率必须设置为一致
收到判断当前的segment是否是被采样忽略的,如果是被采样忽略的就直接忽略,如果不是继续执行后续的代码
设置segemnt中endpointId的值,这里endpointID是这样计算出来的
endpointId = IDManager.EndpointID.buildId(
serviceId,
endpointName
)
当前的应用为dubbo-provider对于的service_id的值为REVNTy13ZWJhcHA=.1
endpointName为当前span对应的 operationName: "com.xxx.HelloService.say(String)"
然后通过上面的这两个参数获得对应的值
*/
public static String buildId(String serviceId, String endpointName) {
return serviceId
+ Const.ID_CONNECTOR
+ encode(endpointName);
}

算出来了之后
经过处理之后整个TraceSegment的结构如下
2、预构建 :替换url peer端口、servicenam等信息
1、接下来将TraceSegment中各个span的类型分配给不同的spanlistener进行处理
接下来对每一个span进行解析
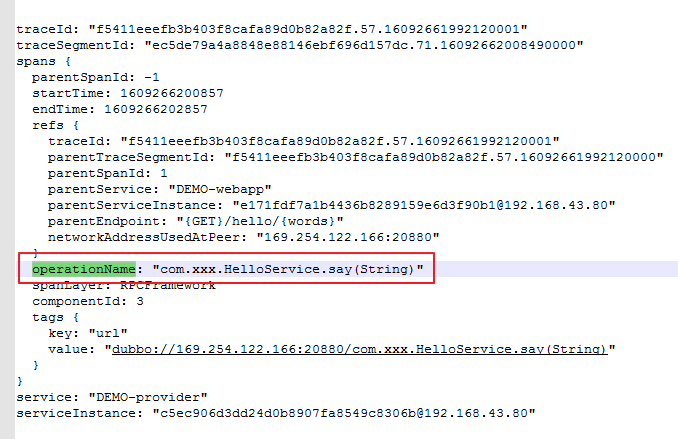
parentSpanId: -1
startTime: 1609266200857
endTime: 1609266202857
refs {
traceId: "f5411eeefb3b403f8cafa89d0b82a82f.57.16092661992120001"
parentTraceSegmentId: "f5411eeefb3b403f8cafa89d0b82a82f.57.16092661992120000"
parentSpanId: 1
parentService: "DEMO-webapp"
parentServiceInstance: "e171fdf7a1b4436b8289159e6d3f90b1@192.168.43.80"
parentEndpoint: "{GET}/hello/{words}"
networkAddressUsedAtPeer: "169.254.122.166:20880"
}
operationName: "com.xxx.HelloService.say(String)"
spanLayer: RPCFramework
componentId: 3
tags {
key: "url"
value: "dubbo://169.254.122.166:20880/com.xxx.HelloService.say(String)"
}
依据不同的span类型进行解析,传递给不同的listen对象,然后产生不同的数据指标