Chapter 4 - Clustering Models
Segment 2 - Hierarchical methods
Hierarchical Clustering
Hierarchical clustering methods predict subgroups within data by finding the distance between each data point and its nearest neighbors, and then linking the most nearby neighbors.
The algorithm uses the distance metric it calculates to predict subgroups.
To guess the number of subgroups in a dataset, first look at a dendrogram visualization of the clustering results.
Hierarchical Clustering Dendrogram
Dendrogram: a tree graph that's useful for visually displaying taxonomies, lineages, and relatedness
Hierarchical Clustering Use Cases
- Hospital Resource Management
- Customer Segmentation
- Business Process Management
- Social Network Analysis
Hierarchical Clustering Parameters
Distance Metrics
- Euclidean
- Manhattan
- Cosine
Linkage Parameters
- Ward
- Complete
- Average
Parameter selection method: use trial and error
Setting up for clustering analysis
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import rcParams
import seaborn as sb
import sklearn
import sklearn.metrics as sm
from sklearn.cluster import AgglomerativeClustering
import scipy
from scipy.cluster.hierarchy import dendrogram, linkage
from scipy.cluster.hierarchy import fcluster
from scipy.cluster.hierarchy import cophenet
from scipy.spatial.distance import pdist
np.set_printoptions(precision=4, suppress=True)
plt.figure(figsize=(10, 3))
%matplotlib inline
plt.style.use('seaborn-whitegrid')
address = '~/Data/mtcars.csv'
cars = pd.read_csv(address)
cars.columns = ['car_names','mpg','cyl','disp', 'hp', 'drat', 'wt', 'qsec', 'vs', 'am', 'gear', 'carb']
X = cars[['mpg','disp','hp','wt']].values
y = cars.iloc[:,(9)].values
Using scipy to generate dendrograms
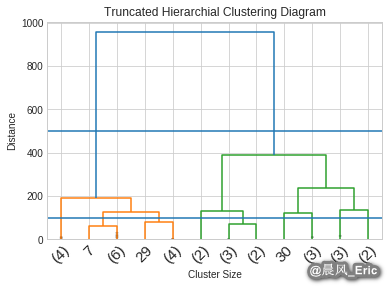
Z = linkage(X, 'ward')
dendrogram(Z, truncate_mode='lastp', p=12, leaf_rotation=45., leaf_font_size=15, show_contracted=True)
plt.title('Truncated Hierarchial Clustering Diagram')
plt.xlabel('Cluster Size')
plt.ylabel('Distance')
plt.axhline(y=500)
plt.axhline(y=100)
plt.show()
Generating hierarchical clusters
k = 2
Hclustering = AgglomerativeClustering(n_clusters=k, affinity='euclidean', linkage='ward')
Hclustering.fit(X)
sm.accuracy_score(y, Hclustering.labels_)
0.78125
Hclustering = AgglomerativeClustering(n_clusters=k, affinity='euclidean', linkage='average')
Hclustering.fit(X)
sm.accuracy_score(y, Hclustering.labels_)
0.78125
Hclustering = AgglomerativeClustering(n_clusters=k, affinity='manhattan', linkage='average')
Hclustering.fit(X)
sm.accuracy_score(y, Hclustering.labels_)
0.71875