文本处理工具
用于处理文本的工具有很多,今天我们就来一个个说一说
文本查看工具 cat tac rev
命令:cat
格式:cat [OPTION]... [FILE]...
选项: -v 显示非打印字符
-E 显示每一行末尾$符
-T 显示TAB(以^I形式显示)
-n 显示行号
-s 将连续的空行压缩成一行
-A 相当于-vET
-b 显示所有的非空行编号
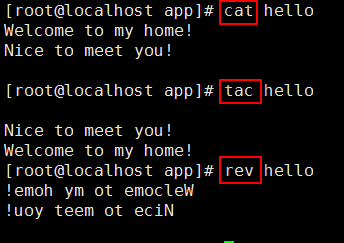
cat是将文本按正常的格式显示出来,我们还有另外两个文本查看语句,是tac和rev,tac是将文本从最后一行开始,显示至第一行;而rev也是反向显示,不过是从每一行的最后一个字符开始显示,然后倒数第二个字符,一直到第一个字符;三者的区别,我们可以从下图看出:
小练习:1、把文件1.txt的内容加上行号后,输入到文件2.txt中。

分页查看文件内容 less more
命令:less
格式:less [OPTION]... [FILE]...
查看文件时常用指令:
space, ctrl+v, ctrl+f, ctrl+F:向文件尾翻屏
ctrl+b:向文件首部翻屏
ctrl+d:向文件尾部翻半屏
ctrl+u:向文件首部翻半屏
ctrl+N, e, ctrl+E, j, ctrl+J: 向文件尾部翻一行
y, ctrl+Y, ctrl+P, k, ctrl+K:向文件首部翻一行
q: 退出
#:跳转至第#行
g: 回到文件首部
G:翻至文件尾部
/KEYWORD:以KEYWORD指定的字符串为关键字,从当前位置向文件尾部搜索(仅首次有效),不区分字符大小写
n:下一个
N:上一个
命令:more
格式:more [OPTION]... [FILE]...
选项: -d 显示翻译及退出提示
显示文本前或后行内容: head tail
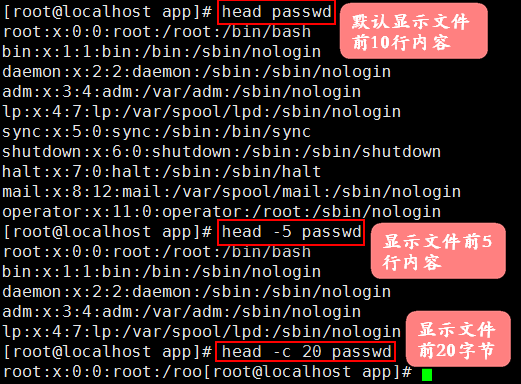
命令:head
格式:head [OPTION]... [FILE]...(默认显示前10行内容)
选项: -n 行号 显示前n行
-行号 显示前n行
-c 字节数 显示前n个字节
命令:tail
格式:tail [OPTION]... [FILE]...(默认显示后10行内容)
选项: -n 行号 显示后n行
-行号 显示后n行
-c 字节数 显示后n个字节
-f 动态显示(跟踪显示文件新追加的内容,常用日志监控)
小练习:1、显示/ect/passwd文件的第11行至第20行

2、利用 cat /dev/urandom 生成10位字符长度的随机密码(包含大小写字母及数字)

按列抽取文本 cut
命令:cut
格式:cut [OPTION]... [FILE]...
选项: -d 指定分隔符
-f 选取第几列
n 第n个字段
n-r 连续的多个字段
n,n-r 混合使用
--output-delimiter 指定输出符
小练习:1、显示当前主机的第一个网卡地址

2、查出/app目录的空间使用量

合并文件paste
命令:paste
格式:paste [OPTION]... [FILE]...
选项: -s f1 将文件内容变成一行显示
也可以用 tr ' ' ' ' 实现
-d "" f1 f2 [f3] 定义合并后的分隔符,默认为TAB
文本数据统计工具 wc (word count)
命令:wc
格式:wc [OPTION]... [FILE]...
选项: -m 显示字符数
-c 显示字节
-l 显示行数
-w 显示单词数
wc 依次显示行数,单词数,字节数
小练习:1、统计当前目录下文件数量

文本排序 sort
命令:sort
格式:sort [OPTION]... [FILE]...
选项: -r 执行反方向(由上至下)整理
-n 执行按数字大小整理
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique)删除输出中的重复行
-t c 选项使用c做为字段界定符
-k X 选项按照使用c字符分隔的X列来整理能够使用多次
小练习:1、找出分区利用率最大的值

去重管理 uniq
命令:uniq
格式:uniq [OPTION]... [FILE]...
选项: -c 显示连续重复的次数
-d 仅显示重复的次数
-u 仅显示不曾重复的行
uniq仅能去除连续的重复行,如果想去除非连续的行,需要先用sort排序。
小练习:1、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面

比较文件diff
命令:diff
格式:diff 文件A 文件B
Eg:比较文件one.txt和文件two.txt的区别
