直接上干的步聚如下:
为了方便 tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 qiny 字体名MyFont
那么我们把tif文件重命名 qiny.MyFont.exp0.tif
1.准备jTessBoxEditor-1.6
2.下载tesseract 4.0
3. 制作需要认别的汉字TIF图片,直接用PS生成TIF即可 qiny.MyFont.exp0.tif
使用下面的方式纠正文字
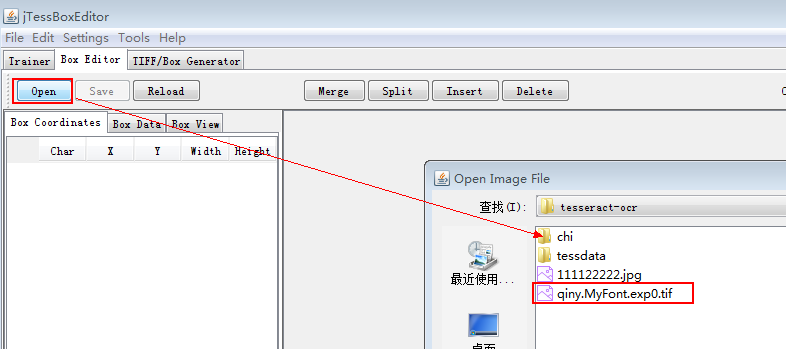
如下为训练的字:
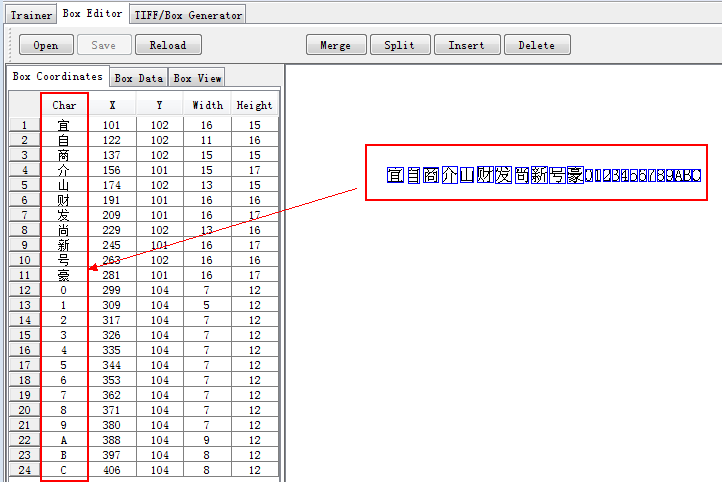
4.启动jTessBoxEditor-1.6

使用qiny.MyFont.exp0.tif生成:
qiny.MyFont.exp0.box
qiny.font_properties
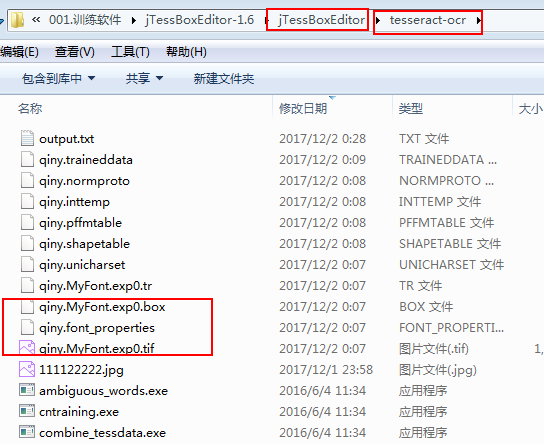
5.把如下三个文件COPY到如下目录中
6. 生成字库:
1、tesseract qiny.MyFont.exp0.tif qiny.MyFont.exp0 -l chi_sim batch.nochop makebox
该步骤会生成一个qiny.MyFont.exp0.box文件,把tif文件和box文件放在同一目录,用jTessBoxEditor.jar打开tif文件,然后根据实际情况修改box文件
这一步在第四步中已经做出业就不用再做了,直接从第二步开始就可以了。
2、tesseract qiny.MyFont.exp0.tif qiny.MyFont.exp0 box.train
该步骤生成一个qiny.MyFont.exp0.tr文件
不加tesseract qiny.MyFont.exp0.tif qiny.MyFont.exp0 nobatch box.train
这句执行不了
3、unicharset_extractor qiny.MyFont.exp0.box
该步骤生成一个unicharset文件
4、新建一个font_properties文件
里面内容写入MyFont 0 0 0 0 0 表示默认普通字体
5、运行命令
shapeclustering -F qiny.font_properties -U unicharset qiny.MyFont.exp0.tr
mftraining -F qiny.font_properties -U unicharset -O qiny.unicharset qiny.MyFont.exp0.tr
cntraining qiny.MyFont.exp0.tr
6、把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上qiny.
7、执行combine_tessdata qiny.
然后把image.traineddata放到tessdata目录
8、用新的字库对图片进行分析
tesseract qiny.MyFont.exp0.tif output -l qiny
7.效果:
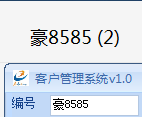
这样就可以认别出训练的字了