PC硬件架构
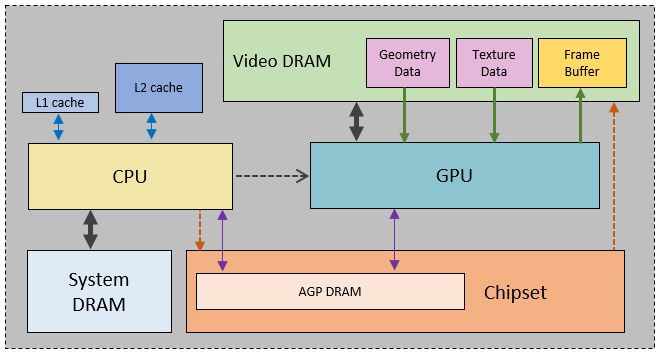
CPU Cache
L1为CPU的一级缓存、L2为二级缓存,L1离CPU更近,访问速度高于L2,但容量比L2小
SRAM和DRAM区别
随机访问存储器(RAM)分为静态随机访问存储器(Static Random Access Memory - SRAM)和动态随机存取存储器(Dynamic Random Access Memory -DRAM)
SRAM只要存入数据后,即使不刷新也不会丢失记忆;而DRAM的电容经常周期性地充电,否则无法确保记忆长存。由于复杂的内部结构,SRAM比DRAM的占用面积更大
SRAM比DRAM更为昂贵,但更为快速、非常低功耗(特别是在空闲状态)。因此SRAM首选用于带宽要求高,或者功耗要求低的情境。如:CPU Cache、GPU On-Chip Buffer
DRAM拥有非常高的密度,单位体积的容量较高,因此成本较低。但缺点是访问速度较慢,耗电量较大。一般用于:系统内存、显存。
内存类型
VM (Video Memory,Video DRAM )
居于显卡上的显存, GPU直接访问,CPU无法访问
SM (SYSTEM MEMORY,System DRAM )
居于系统内存中,CPU能访问, GPU无法访问
AM (AGP Momery, Accelerated Graphic Ports,AGP DRAM)
为了使系统和图形加速卡之间的数据传输获得比PCI总线更高的带宽,从SM上分配出来。
GPU能访问,CPU能访问。CPU读取AGP内存速度很慢,写的速度比读取稍微快,GPU读和写的速度比VM慢一些
资源类型
程序员在用DX创建不同类型的资源时,要根据资源的特点,来决定是放在VM、SM还是AM上
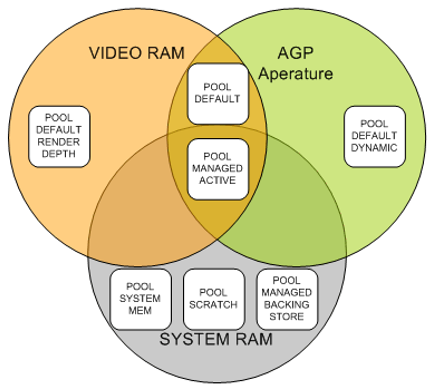
D3DPOOL_MANAGED (dx11对应D3D11_USAGE_DYNAMIC)
① 该类型的资源创建在SM上,在需要渲染时,pci到VM上,存在两份
DX会使用最近最少使用算法(LRU)来对VM进行释放,如果再次请求会在SM->(pci)->VM
② 设备失效后,VM那份丢失,将会自动从SM->(pci)->VM
③ 适用于静态物件(所有静态物件的veterx、index、GPU Skin等,凡是一次创建,终身使用,中途不再更改的)
D3DPOOL_DEFAULT (dx11对应D3D11_USAGE_DEFAULT)
① 有专属的分配优先级,分配原则:优先VM,次之AM,最后SM,等同于告诉DX抽象层:我要放在你认为最快访问的地方
② DX抽象层不负责该类型资源释放,用户自己进行release管理
③ 设备失效时,需要手动恢复
④ 适用于render targets、depth/stencil buffers等,gpu能快速访问
D3DPOOL_SYSTEMMEM (dx11对应D3D11_USAGE_STAGING)
① 放在SM中,不能用于图形管线,但格式仍然受到图形硬件、驱动限制(如:最大尺寸)。可通过pci随时对POOL_DEFAULT类型资源进行update
② 设备失效对该类型无影响
D3DPOOL_SCRATCH
① 放在SM中,不能用于图形管线,且不受图形硬件、驱动限制,资源之间可互相赋值。gpu无法访问
② 设备失效对该类型无影响
不同地组合情况见下图所示:
Mobile硬件架构
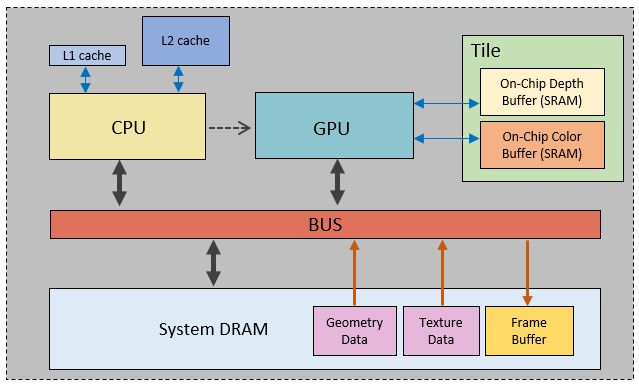
Mobile上使用统一的内存架构,CPU和GPU都通过总线来访问SM (SYSTEM MEMORY,System DRAM )
Geometry Data、Texture Data及Frame Buffer在SM中,GPU频繁地访问这些数据,会导致带宽消耗大,成为性能瓶颈
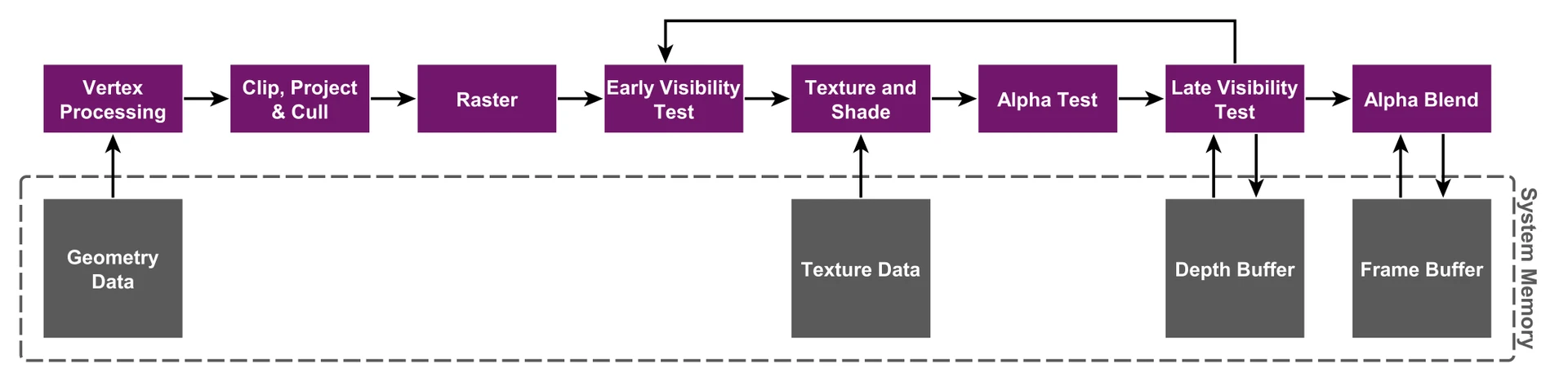
IMR(Immediate Mode Rendering)的管线
Mobile如果使用IMR(Immediate Mode Rendering)模式(直接在SM上读写Depth Buffer/Frame Buffer)的话
带宽消耗很大,另外与读写On-Chip Depth Buffer(SRAM) / On-Chip Color Buffer(SRAM)相比,耗电量很高(高出2个数量级)
Mobile设备通过DVFS(Dynamic Voltage and Frequency),动态控制手机功率,当耗电量大发热大时,就会引发降频,导致设备性能下降,游戏帧率低。
因此,Mobile上gpu的设计原则就是要尽量省电。
IMR模式流程图如下:
TBR(Tile-based rendering)的管线
基于上面原因,现代Mobile gpu都采用TBR(Tile-based rendering,基于图块的渲染)的管线
注1:On-Chip Depth Buffer(SRAM) / On-Chip Color Buffer(SRAM)统称为Local Tile Memory
注2:与DRAM相比,SRAM不需要充电来保持存储记忆,因此对SRAM的读写基本不耗电;但缺点是价格昂贵
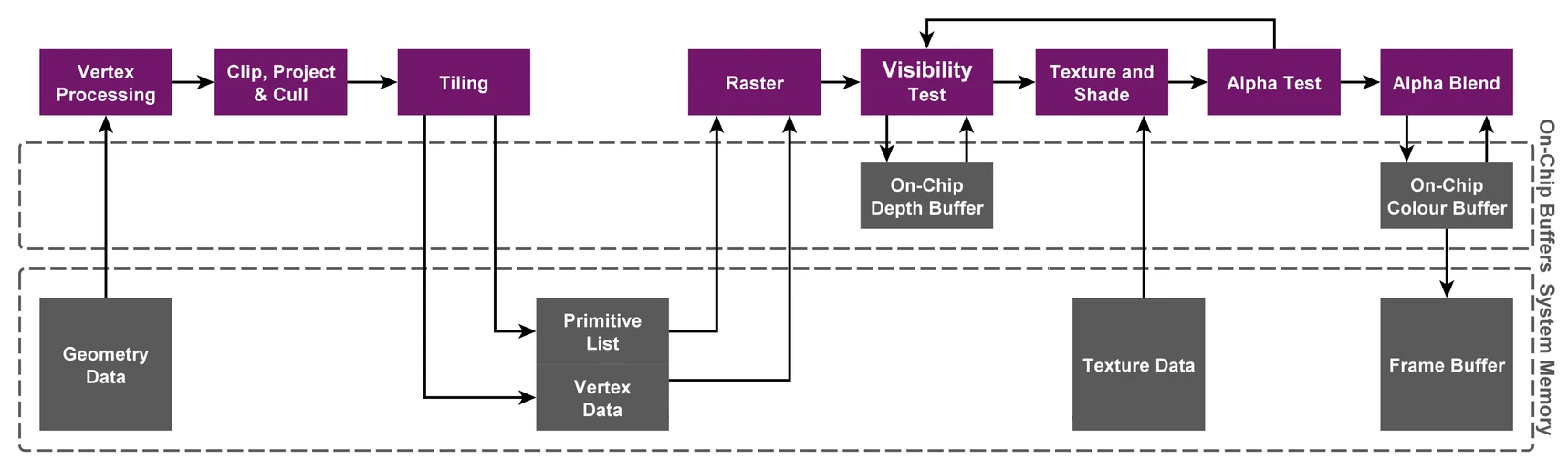
① 分块大小一般为16x16或32x32像素
② 在几何阶段之后,会执行分块(Tiling),然后将各个Tile逐个执行光栅化,并最后写入到Frame Buffer中
③ 按Tile为单位处理,会大大减少对Primitive List/Vertex Data、Texture Data和Frame Buffer的读写,从而大幅度减低对带宽的占用
④ 引入On-Chip Depth Buffer和On-Chip Colour Buffer片上Cache,gpu读写这些Cache速度极快,且不怎么耗电
TBDR(Tile-based deferred rendering)的管线

有了延迟渲染后,所有DrawCall会一起先VS处理,也就是说IMR上如果两个DrawCall,执行顺序是VS1->FS1->VS2->FS2,而TBDR是VS1->VS2->FS1->FS2。
TBDR在VS后就可以知道像素上哪个DrawCall绘制地最近。可以说从硬件层面实现了Early-Z类似的功能,并且不再依赖DrawCall顺序。
目前主流的移动平台gpu(高通、Mali、苹果)都采用的TBDR架构。
具体步骤:
第一部分处理所有vertex shader,输出结果到主内存
第二部分为HSR(Hidden Surface Removal),在tile上执行。会先处理所有三角形的可见性,保存在一个专用的buffer里面。
这个buffer里,会保存tile里每个像素位置目前可见的三角形,应该执行哪个shader等信息
第三部分真正开始执行fragment shader,在tile上执行。因为第二部分里有像素级别精度的可见性信息,所以这步只会计算实际可见的像素,不可见的像素不会浪费GPU计算力。
避免Overdraw时的无用计算
关于Early-Z说明:
Early-Z是IMR相关技术。绘制在VS处理后,可得到深度信息,进行深度测试(和已有的深度信息比较),如果比已有深度大,说明被挡住了,那么这个像素就不需要走FS了,从而提升性能。
Early-Z比较依赖DrawCall顺序,如果先绘制前景后绘制背景,大部分Draw可以被Early-Z挡住。但如果先绘制背景再绘制前景就会OverDraw了。
这要求游戏引擎要对绘制对象进行由近到远的排序,往往需要额外的排序性能。
性能优化建议
① 切换FBO(OpenGL中叫FBO,D3D中叫RT)时,先进行clear,避免load frame buffer中无效数据到高速缓存
② 不需要使用的FBO,比如某些深度图,使用discard/invalidate来避免高速缓存写入frame buffer
③ 由于TBDR是延迟渲染(注:该延迟渲染和PC上延迟渲染有一些差异),合适的时候调用glClear可清空已取消的延迟渲染队列,提高性能
④ 如果移动端在硬件层实现了LRZ(Low Resolution Z)和HSR(Hidden Surface Removel),软件层面Draw Call的顺序不那么重要
⑤ 优化渲染顺序:不透明物体,Mask镂空物体,透明物体(Alpha Blend)
注1:LRZ是高通gpu的专利。该优化执行的时机是在划分tile之后,执行vs之前
注2:HSR是苹果gpu的专利。该优化执行的时机是在所有vs及光栅化之后,执行ps之前
Mobile上消耗带宽的常见原因
① 切换rendertarget 如:后处理、渲染shadowmap
② 大量采样贴图 如:在ps里面采样大的物体(地形、天空、大的建筑)的贴图
③ 顶点、面数过多
参考
Understanding PowerVR Series5XT: PowerVR, TBDR and architecture efficiency
A look at the PowerVR graphics architecture: Tile-based rendering
A look at the PowerVR graphics architecture: Deferred rendering
How low can you go? Building low-power, low-bandwidth ARM Mali GPUs