原文Understanding How Graal Works - a Java JIT Compiler Written in Java,讲了jvmci和ideal graph的基本概念以及一些优化技术,很不错的一篇文章,开头结尾不太重要的部分已经省略,请见谅。
JIT编译器是什么
我敢说很多读者都知道JIT编译器是什么,但是我还是会覆盖基本概念,让在场各位都没有基础上的疑问。
当你运行javac命令,或者用IDE保存的时候就做编译,你的java程序会从java代码编译成JVM字节码。JVM字节码是Java代码的二进制形式的表示。它比起源码来说更紧凑,更简单。但是绝大多数CPU是不能直接执行JVM字节码的。
要运行java程序需要jvm解释字节码。解释字节码通常都会比运行在真正CPU上的机器代码要慢,所以JVM可以在运行时使用其他编译器,将字节码编译成你的CPU可以直接跑的机器代码。
这个编译器通常会比javac更复杂,会做很多优化来产出高质量的机器代码。
为什么JIT编译器要用Java来写
OpenJDK是JVM的一个实现,现在它包含两个JIT编译器。客户端编译器,也叫C1,设计目的是编译速度要快,所以产出的代码会包含较少优化。服务器编译器,也叫opto或者C2,设计初衷是花更多的时间产出高效优化的代码。
两者的设计动机是C1适合桌面应用程序,它们不能容忍因为JIT编译导致长时间的停顿,C2适合长时间运行的服务器程序,它们可以花更多时间在编译上面。
现在的JVM将它们组合在了一起,代码首先使用C1编译,如果后面还在运行而且值得为它花费额外时间就使用C2再做编译。这个机制叫做分层编译。
让我们把目光转向C2——花更多时间在优化上面
我们可以从github克隆openjdk镜像,或者可以直接浏览它的网站下载。
$ git clone https://github.com/dmlloyd/openjdk.git
C2代码位于openjdk/hotspot/src/share/vm/opto.
首先,C2使用C++写的。当然C++没什么本质上的错误,但却有一些麻烦。C++是一门不安全的语言——这意味这C++的错误可以造成虚拟机crash。也由于代码年代久远,用C++写的C2变得很难维护,很难扩展。
C2背后的关键人物Cliff Click说他再也不会用C++写虚拟机,我们也听Twitter JVM团队说C2目前是一滩死水,亟待一个替代品,因为在它上面开发太困难了。


所以回到问题,为什么Java可以帮我们解决这些问题?呃因为上述所有需求都暗示我们用Java而不是C++。Java异常比C++ crash更安全,没有内存泄漏,没有悬空指针,也有很多工具比如调试器,profiler,visualvm,还有很多ide支持,等等。
你可能会想用Java写一个JIT编译器这怎么可能?你可能认为只有使用低级系统语言比如C++才能做到,但是在这个talk中我想说不是的,完全不是!事实上JIT编译器要做的只是接受JVM字节码然后产出机器代码——你收到一个byte[]数组然后返还一个byte[]即可。它可能背后做很多复杂的工作,但是这完全不涉及一个真的“系统”,你也不需要一个“系统”语言——一些定义认为系统语言是指类似C或者C++的语言,但不是Java。
配置graal
我们要做的第一件事是java9。graal使用的接口叫做jvmci,由JEP 243Java-Level JVM Compiler Interface提案加入到Java中。 第一个实现提案的版本是java9。我使用9+181。如果有特殊需求也可以使用backport jvmci的java8。
$ export JAVA_HOME=`pwd`/jdk9
$ export PATH=$JAVA_HOME/bin:$PATH
$ java -version
java version "9"
Java(TM) SE Runtime Environment (build 9+181)
Java HotSpot(TM) 64-Bit Server VM (build 9+181, mixed mode)
下一步需要一个构建工具mx。 他有点像maven或gradle,但是可能你从没在你的程序上用过它。它支持一些复杂的使用样例,但是我们只使用它做简单的构建工作。
$ git clone https://github.com/graalvm/mx.git
$ cd mx; git checkout 7353064
$ export PATH=`pwd`/mx:$PATH
接着我们克隆graal本身。。我是用graalvm的一个版本,版本号是0.28.2
$ git clone https://github.com/graalvm/graal.git --branch vm-enterprise-0.28.2
该仓库包含了一些项目,目前我们不关心。我们可以切换到compiler子目录,那就是graal jit本身。然后使用mx构建它。
$ cd graal/compiler
$ mx build
现在我要使用eclipse ide打开graal源码。我是用eclipse 4.7.1。 mx支持生成eclipse项目文件。
$ mx eclipseinit
如果你想使用graal作为workspace,点File,Import...,General,Existing projects然后选择graal目录即可。如果你没用Java9运行eclipse本身,那你可能需要attach一个jdk。
ok,现在万事俱备,以一个简单的代为例我会展示它是如何工作的。
class Demo {
public static void main(String[] args) {
while (true) {
workload(14, 2);
}
}
private static int workload(int a, int b) {
return a + b;
}
}
我们将用javac编译,然后使用jvm运行。首先使用传统的C2 JIT。在这之前我们加上一些参数,用-XX:+PrintCompilation jvm记录哪些方法便已过,用-XX:CompileOnly=Demo::workload让编译器只编译某个方法,免得输出太多了。
$ javac Demo.java
$ java
-XX:+PrintCompilation
-XX:CompileOnly=Demo::workload
Demo
...
113 1 3 Demo::workload (4 bytes)
...
上面的log表示workload方法被编译了,其他细节信息我不做解释。
现在让我们使用刚刚构建的Graal作为Java9 JVM的JIT编译器。我们需要再加一些比较复杂的flags。
·--module-path=...和--upgrade-module-path=...把graal加入模块路径。注意模块是Jigsaw模块系统的东西,现在已经加入Java9,目前来说你可以将模块路径看成是classpath。
我们需要-XX:+UnlockExperimentalVMOptions因为JVMCI(graal使用的)现目前还是实验性质的。
然后加上-XX:+EnableJVMCI告诉JVM我们要使用JVMCI,然后加上-XX:+UseJVMCICompiler告诉jvm我们想配置一个新的JIT编译器。
接着简单起见,加上-XX:-TieredCompilation关闭分层编译让JVM只有一个JVMCI编译器而不是C1和JVMCI混合分层。
当然,前面的-XX:+PrintCompilation 和-XX:CompileOnly=Demo::workload还是保持不变。和之前一样,我们会看到有一个方法被编译了虽然是使用graal编译的。现在请只管跟着我做。
$ java
--module-path=graal/sdk/mxbuild/modules/org.graalvm.graal_sdk.jar:graal/truffle/mxbuild/modules/com.oracle.truffle.truffle_api.jar
--upgrade-module-path=graal/compiler/mxbuild/modules/jdk.internal.vm.compiler.jar
-XX:+UnlockExperimentalVMOptions
-XX:+EnableJVMCI
-XX:+UseJVMCICompiler
-XX:-TieredCompilation
-XX:+PrintCompilation
-XX:CompileOnly=Demo::workload
Demo
...
583 25 Demo::workload (4 bytes)
...
JVMCI编译器接口
我们现在做的很牛逼了不是吗?我们有个JVM,然后用新的JIT替换了之前的那个,还用它编译了代码,且没有改变JVM的任何代码。让这一切变得可能的正是JVMCI——JVM编译器接口——之前提到过JEP243提出它现在已经并入java9。
这个idea和jvm现有的一些技术其实差不多。
以前你可能用Java注解处理API添加过一些注解到javac,它们可以处理源代码。不难看出java注解就是个获取它们附着于的源代码,然后产出新源代码的工具。
你可能使用过java agent做自定义的java字节码处理。它可以拦截java字节码然后修改它。
JVMCI和它们一样。它让你可以插入一个java写的jit编译器到jvm上。
等下我会介绍ppt上展示的代码的一些方法,然后我会简化标识符和逻辑帮助你理解这个idea,接着我会切换到eclpse的一些屏幕截图向你展示真的代码,虽然可能有点复杂,但是大体上是一样的。这个talk的重要内容就是帮助你深入源码本身,所以我不想隐藏它,尽管它很复杂。
首先我想消除你觉得jit编译器极其复杂的想法。JIT编译器的输入什么?它获取要编译的方法的字节码,字节码,看名字就知道是“一个字节数组的代码”。JIT编译器输出什么?它输出方法对应的机器代码。机器代码也是“一个字节数组的代码“
所以当你写一个新jit插入到jvm的时候你要实现的接口看起来类似下面:
interface JVMCICompiler {
byte[] compileMethod(byte[] bytecode);
}
所以你大可不必认为java怎么能做jit编译产出机器码这么底层的事情,他就是个byte[]到byte[]的函数而已。
不过实际上的比这要复杂一些。只是一个字节数组的代码还不够,我们还想要一些信息比如局部变量的个数,栈的大小,解释器收集到的profiling信息等,这让我们可以了解实际代码运行的情况。因此输入不是字节数组而是一个CompilationRequest,它可以告诉我们哪一个JavaMethod要编译,然后给我们需要的所有信息。
interface JVMCICompiler {
void compileMethod(CompilationRequest request);
}
interface CompilationRequest {
JavaMethod getMethod();
}
interface JavaMethod {
byte[] getCode();
int getMaxLocals();
int getMaxStackSize();
ProfilingInfo getProfilingInfo();
...
}
同样,接口不返回编译好的机器代码。取而代之是你调用其他API告诉虚拟机你想装配上机器代码。
HotSpot.installCode(targetCode);
现在为jvm写一个jit编译器我们只需要实现这个接口就好了。我们得到了想要编译的方法的信息,然后编译成机器代码,最后调用installCode
class GraalCompiler implements JVMCICompiler {
void compileMethod(CompilationRequest request) {
HotSpot.installCode(...);
}
}
让我们切换到eclipse ide,看看这些接口到底长什么样。和我前面说的一样,他有点复杂但不是很复杂
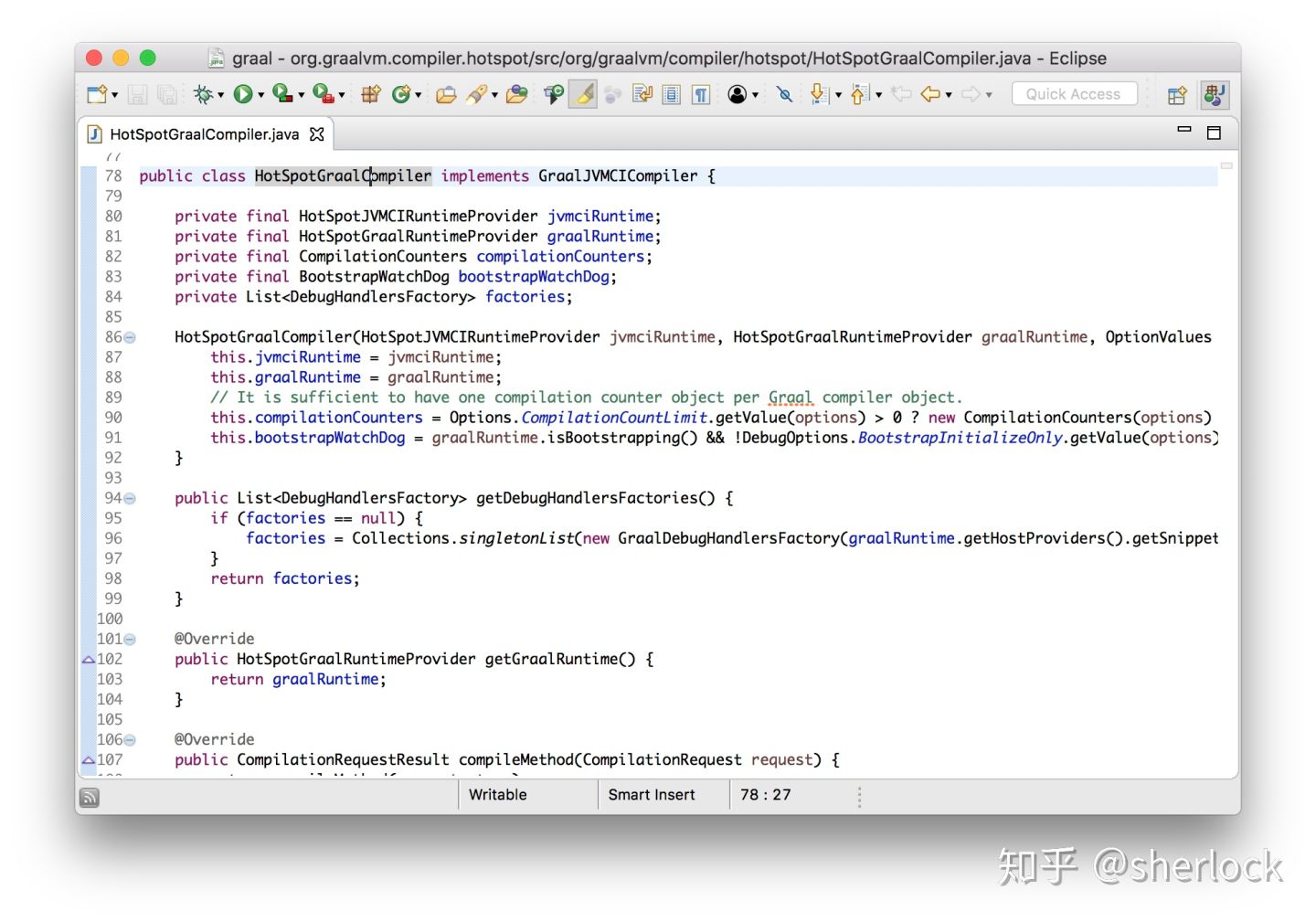
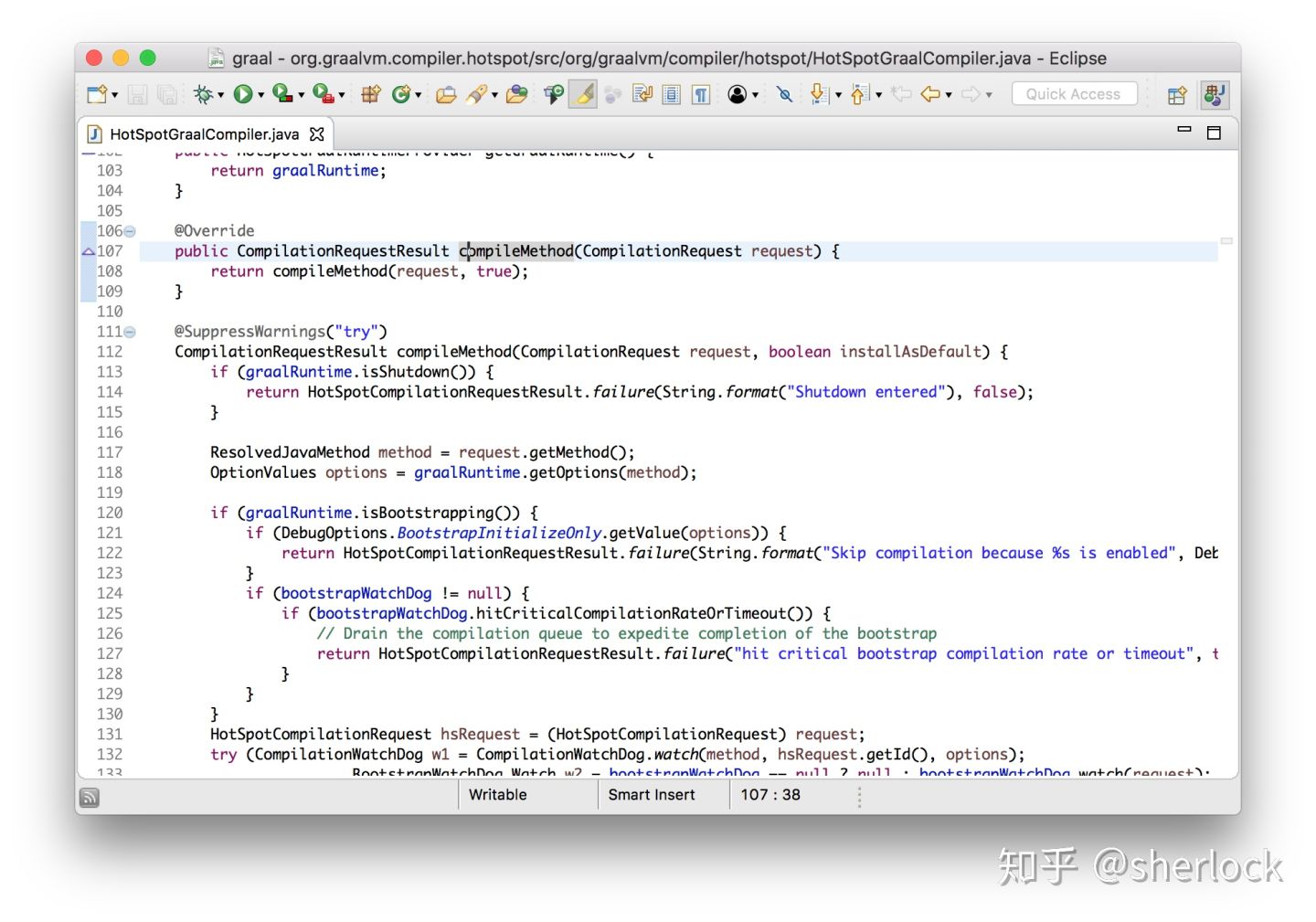
现在我想像你展示的就是我们可以马上改graal的代码然后在java9中使用它。我会在graal编译方法的地方加一些log代码
class HotSpotGraalCompiler implements JVMCICompiler {
CompilationRequestResult compileMethod(CompilationRequest request) {
System.err.println("Going to compile " + request.getMethod().getName());
...
}
}
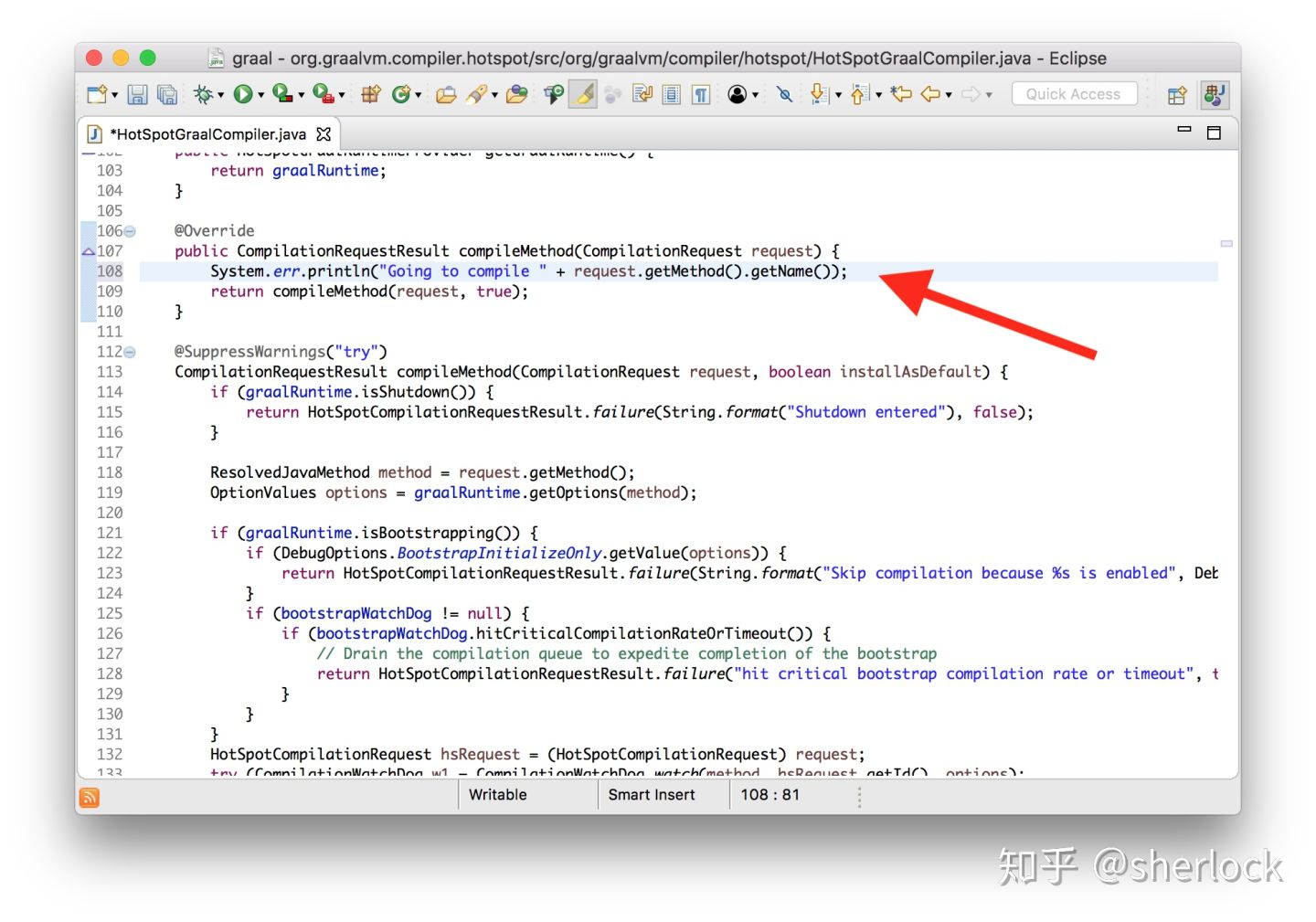
现在关闭HotSpot的编译记录,然后用我们修改的版本
$ java
--module-path=graal/sdk/mxbuild/modules/org.graalvm.graal_sdk.jar:graal/truffle/mxbuild/modules/com.oracle.truffle.truffle_api.jar
--upgrade-module-path=graal/compiler/mxbuild/modules/jdk.internal.vm.compiler.jar
-XX:+UnlockExperimentalVMOptions
-XX:+EnableJVMCI
-XX:+UseJVMCICompiler
-XX:-TieredCompilation
-XX:CompileOnly=Demo::workload
Demo
如果你在elipse中编辑,你会注意到我们甚至没有运行mx build。正常的eclipse编译即可。我们完全不需要编译jvm本身。我们可以看可以立刻把修改好的编译器插入到现有的jvm。
Graal graph
ok,现在我们知道graal是把byte[]转成另一个byte[]。让我们说说这个转化背后 的理论和数据结构。因为它有点不寻常,即使是对于编译器来说。
本质来说编译器做的事情是操纵程序。要操纵程序需要一些用来表示程序本身的数据结构。字节码和类似的指令序列都行,但是表达力不强。
相反,graal使用图结构来表示你的程序。如果你对两个局部变量做加法,图将为每个局部变量创建一个node,还有一个表示加法的node,两条边指示局部变量node流入加法node。
这种图也被叫做程序依赖图。
如果有一个表达式比如x+y,我们会看到两个表示x,y的node,一个对两者做加法的node。
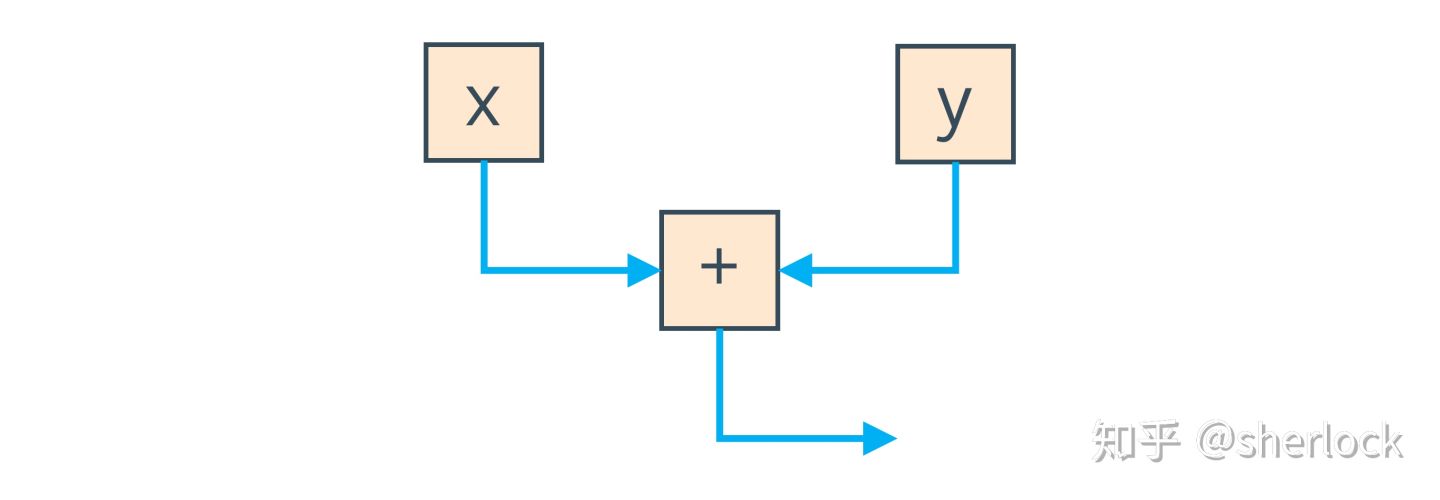
图中蓝色的边表示数据流,它们读取局部变量的值,流入加法node。我们也可以使用边表示程序运行的顺序。如果我们调用两个方法而不是读取两个局部变量,比如getX(),getY(),然后我们需要记住调用顺序。这个也可以通过一条边来表示,即下面的红边。
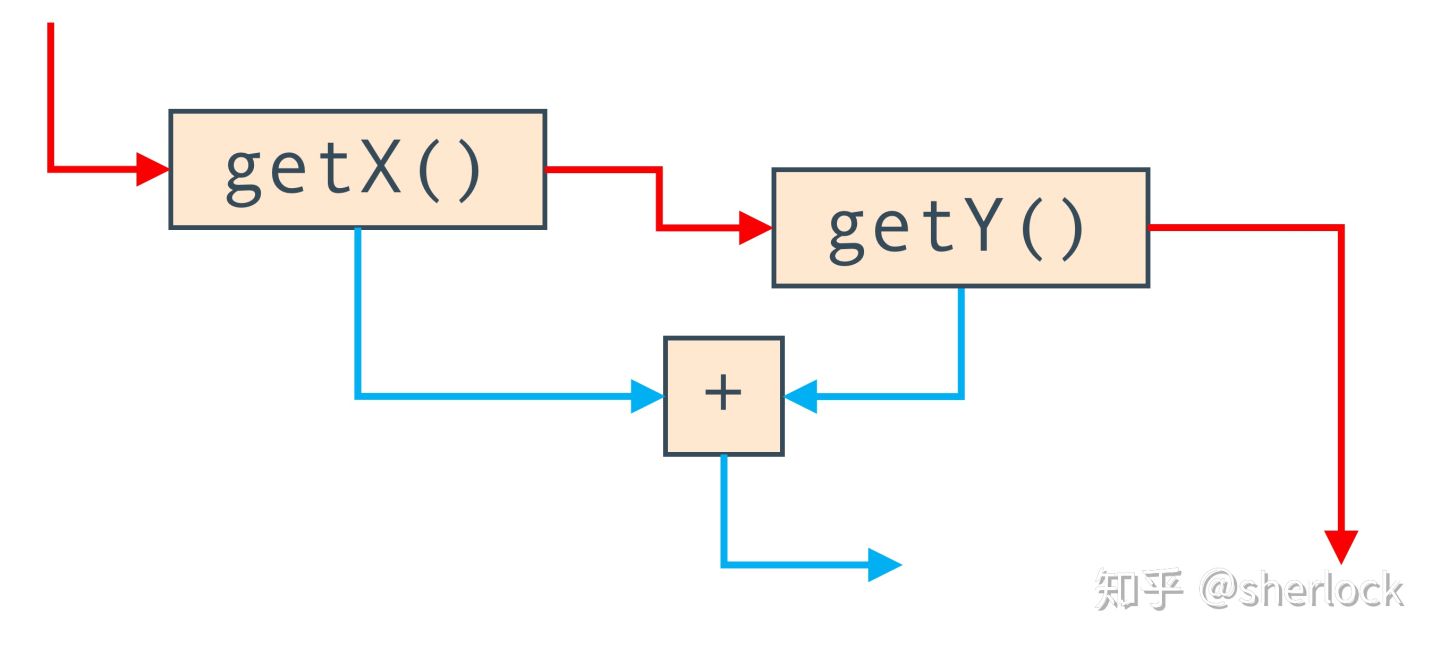
graal图可以说是将两种图以某种方式结合到了一起。节点相同,但是一个边集(edge set)表示数据流,另一个边集表示控制流。
你可以用IdealGraphVisualiser这个工具可视化graal图。运行mx igv即可。
然后jvm加上参数-Dgraal.Dump
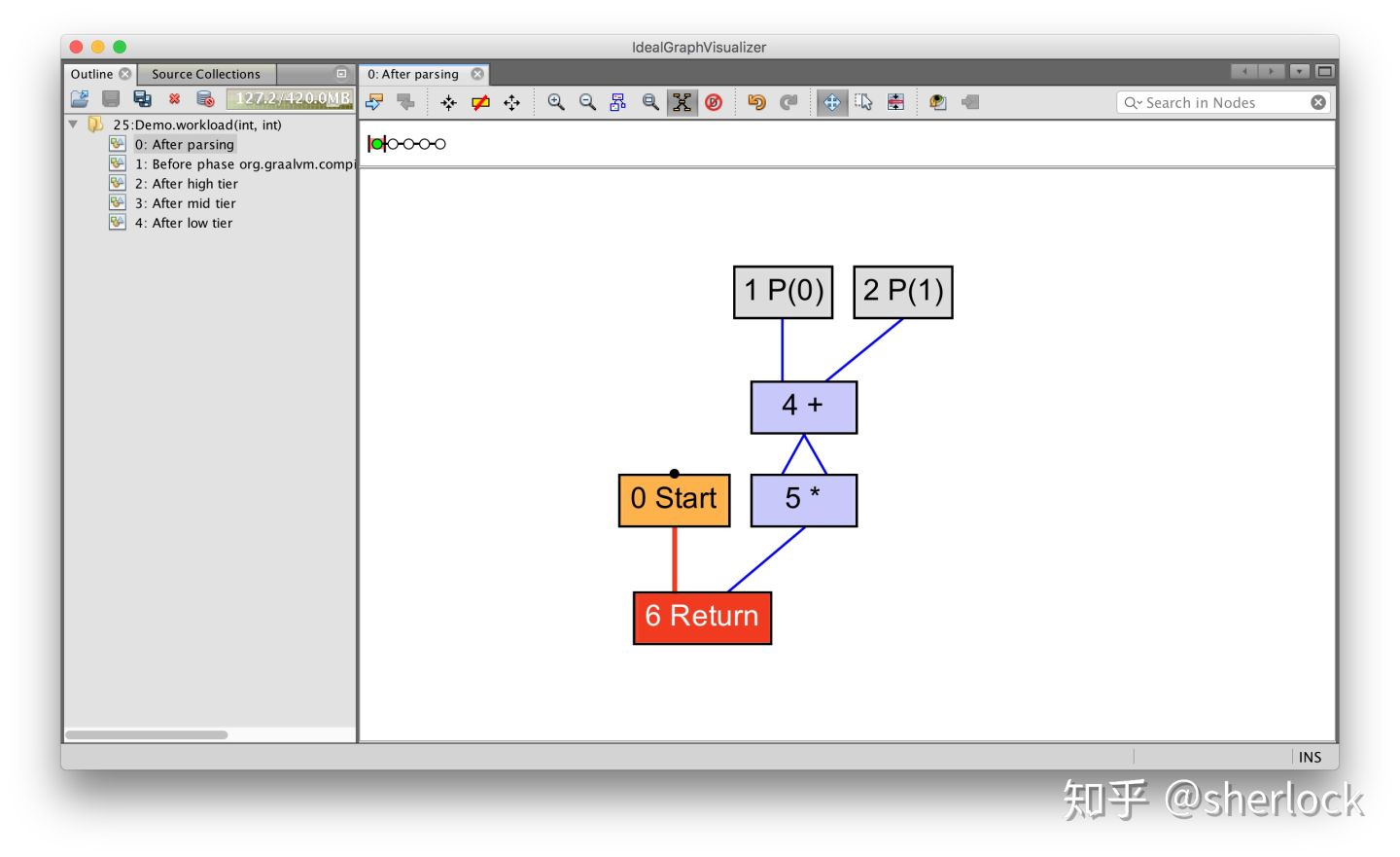
我们可以写个简单的表达式看看数据流
int average(int a, int b) {
return (a + b) / 2;
}
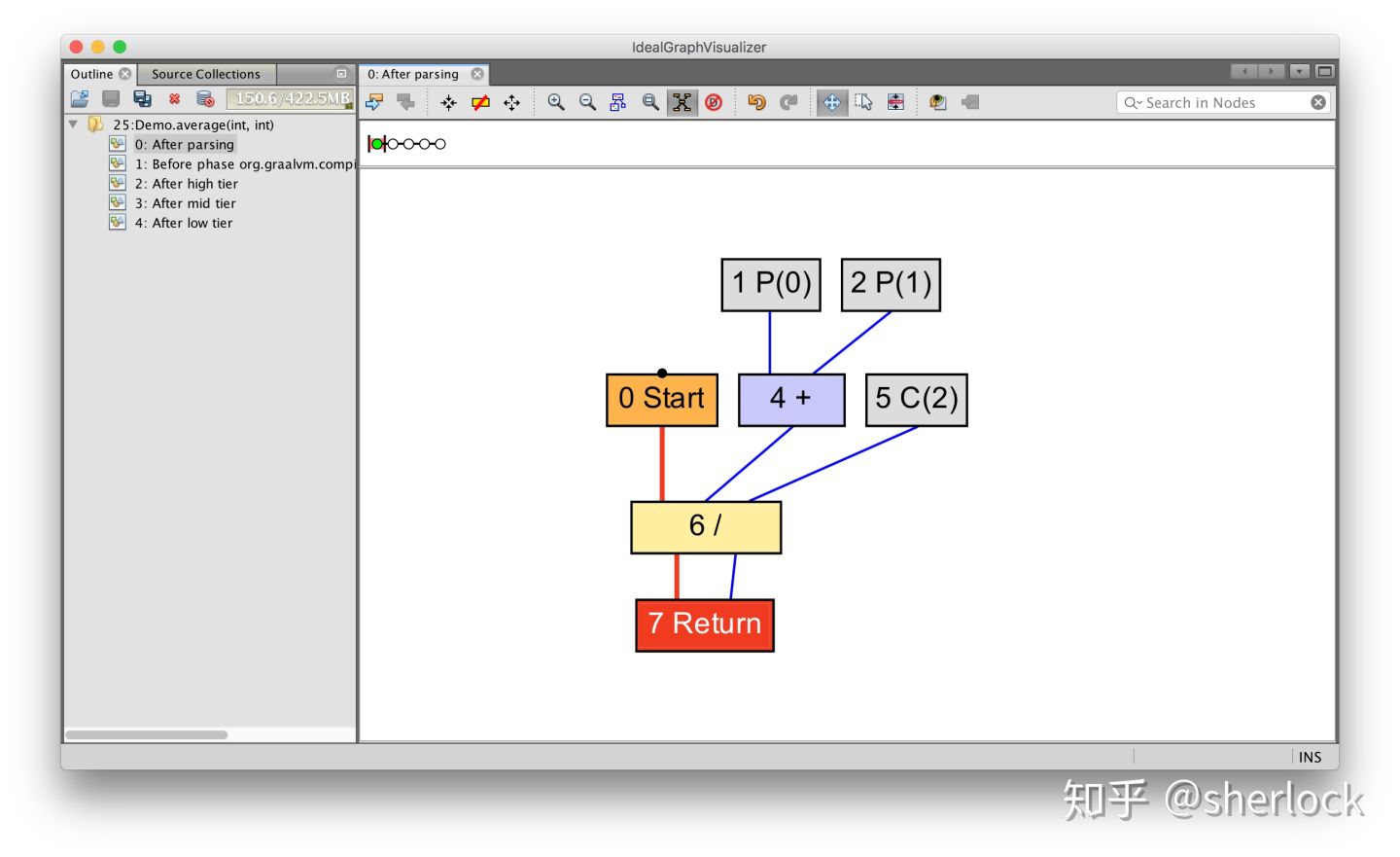
你可以看到参数0(写作P(0))和参数1(写作P(1))是如何送入加法操作的,然后结果是如何和常量2(写作C(2))送入除法操作的。计算最后结果返回。
如果我们引入一个循环可以看到更复杂的数据流和控制流
int average(int[] values) {
int sum = 0;
for (int n = 0; n < values.length; n++) {
sum += values[n];
}
return sum / values.length;
}
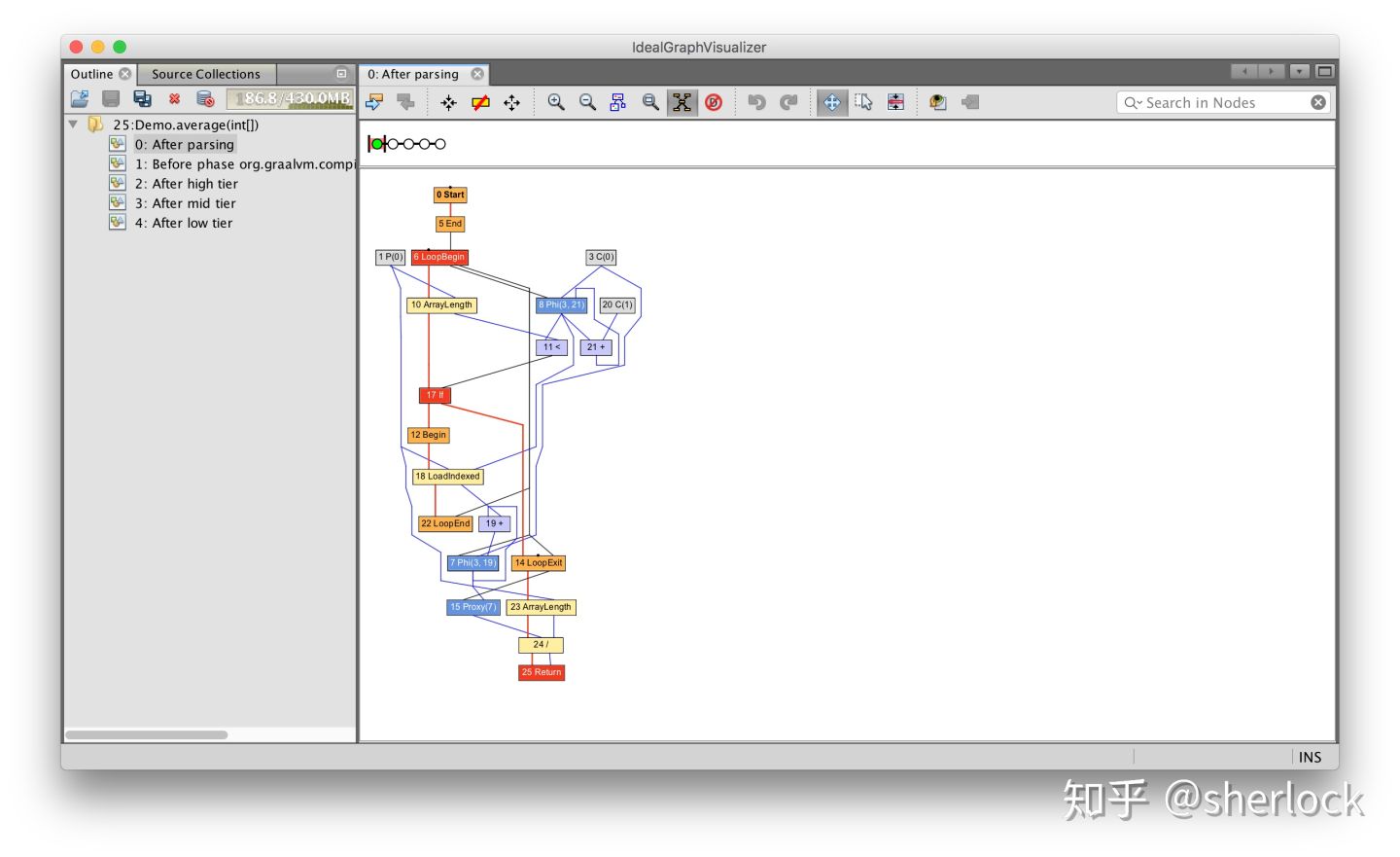
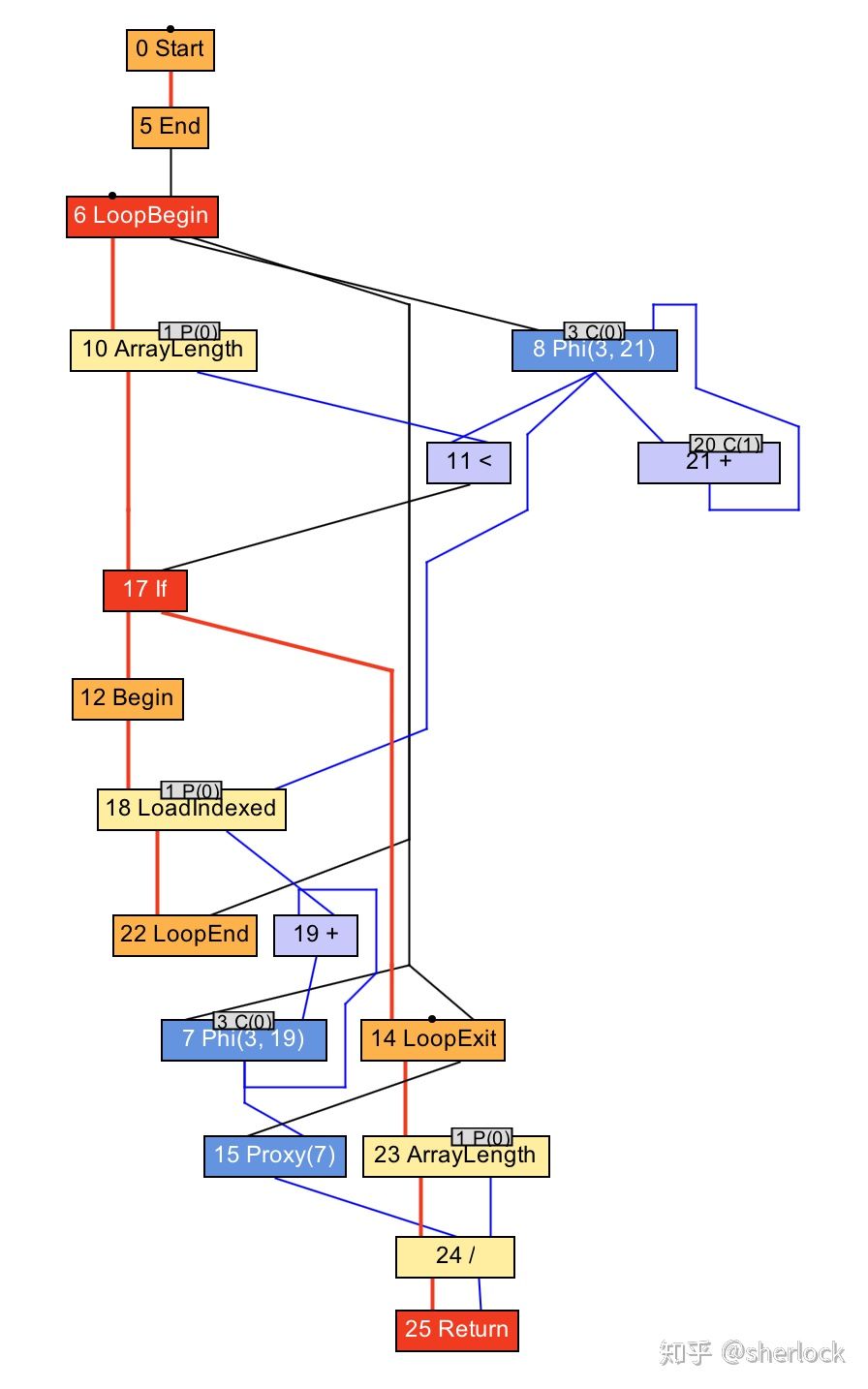
现在图中有节点表示循环起始,有节点表读取数组元素,有节点读取数组长度。和之前一样,蓝线表示数据流,红线表示控制流。
从上面不难看出为什么这个数据结构有时候又叫做节点海(sea of nodes),或者节点汤(soup of nodes)。
我想说c2使用非常类似的数据结构,也正是因为c2使得这种节点海编译器变得留下,它不是graal的创新。
关于图是怎么构建的这里我先不展示,当你的程序使用graal graph这种格式,编译和优化都修改这个数据结构而已。这也是为什么用java写jit没问题的原因。java是oop语言,graal graph是对象的集合,然后引用视作边将他们链接起来。
从字节码到机器代码
让我们从实际除法,看看编译的流程。
1.字节码输入
编译始于字节码。我们回到之前的简单加法示例。
int workload(int a, int b) {
return a + b;
}
我们在编译开始位置输出要编译的字节码
class HotSpotGraalCompiler implements JVMCICompiler {
CompilationRequestResult compileMethod(CompilationRequest request) {
System.err.println(request.getMethod().getName() + " bytecode: "
+ Arrays.toString(request.getMethod().getCode()));
...
}
}
workload bytecode: [26, 27, 96, -84]
2.字节码解析器和图构造器
字节数组被解析为jvm字节码然后放入图构造器。这是另一种形式的解释器,只是比较抽象。它解释执行字节码,只是不传递它们的值而是传递边然后将他们连接起来。让我们享受一下java写graal的好处,用elipse navigation工具看看它怎么工作的。我们知道示例有一个加法节点,现在看看它们是怎么创建的。
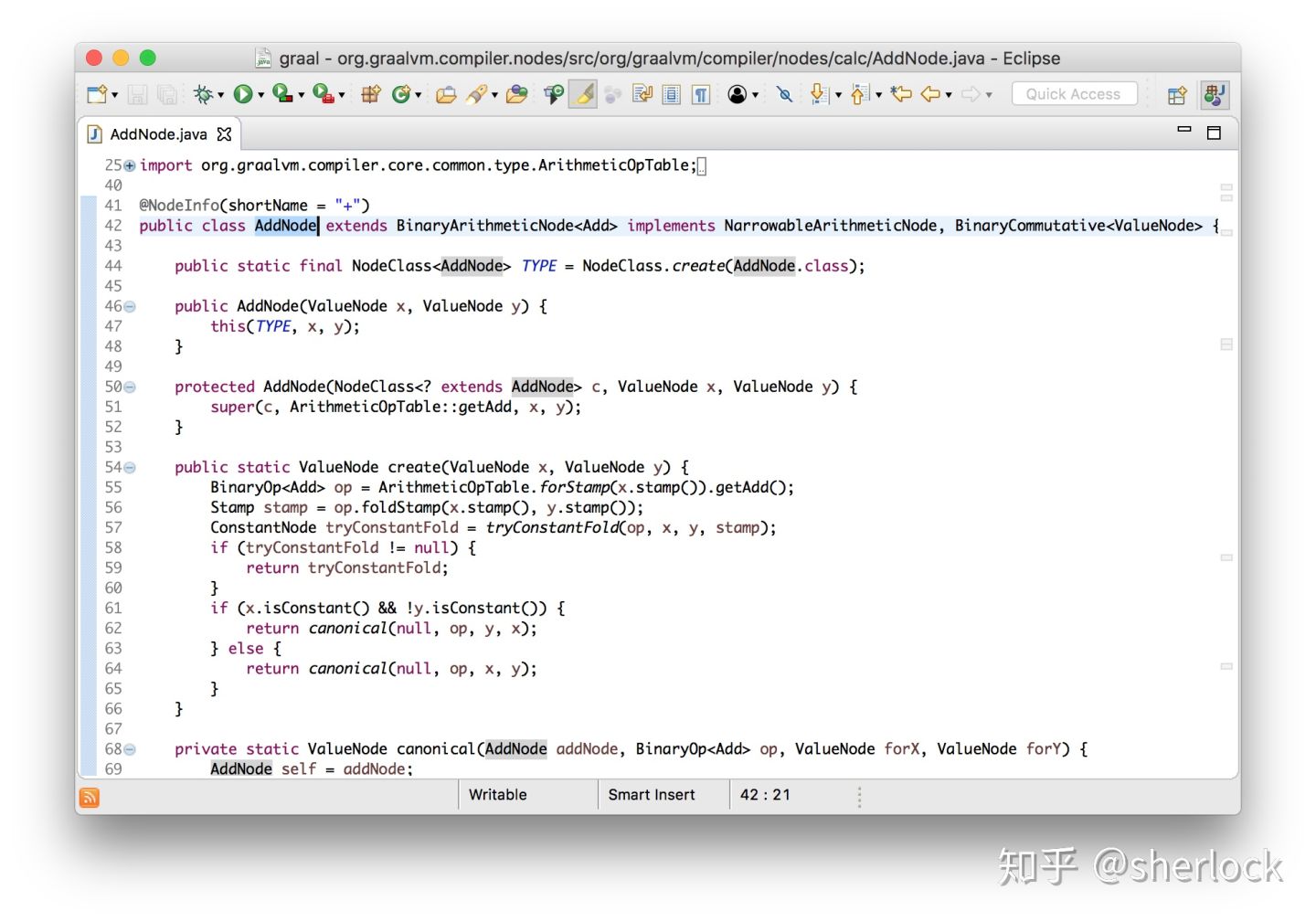
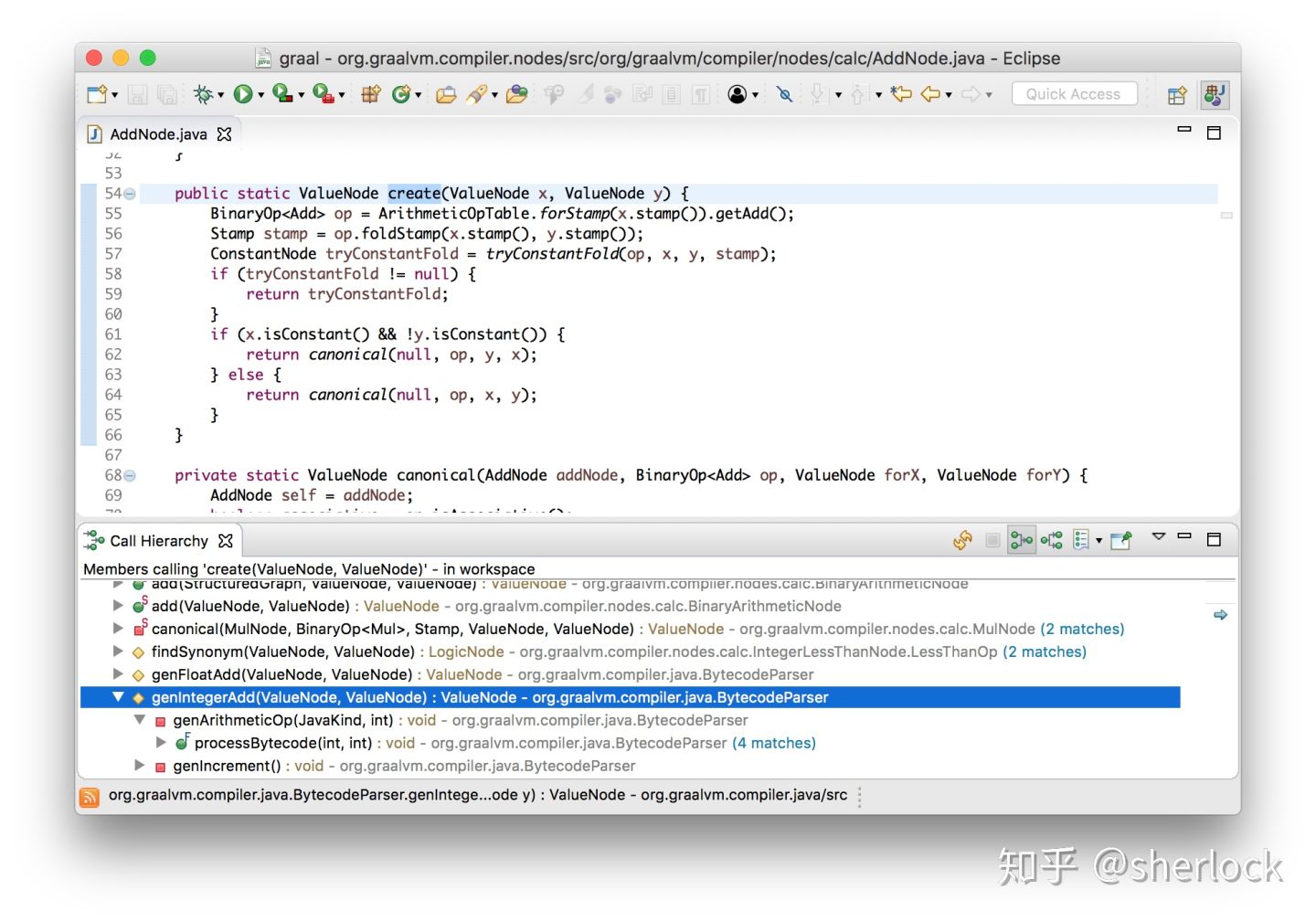
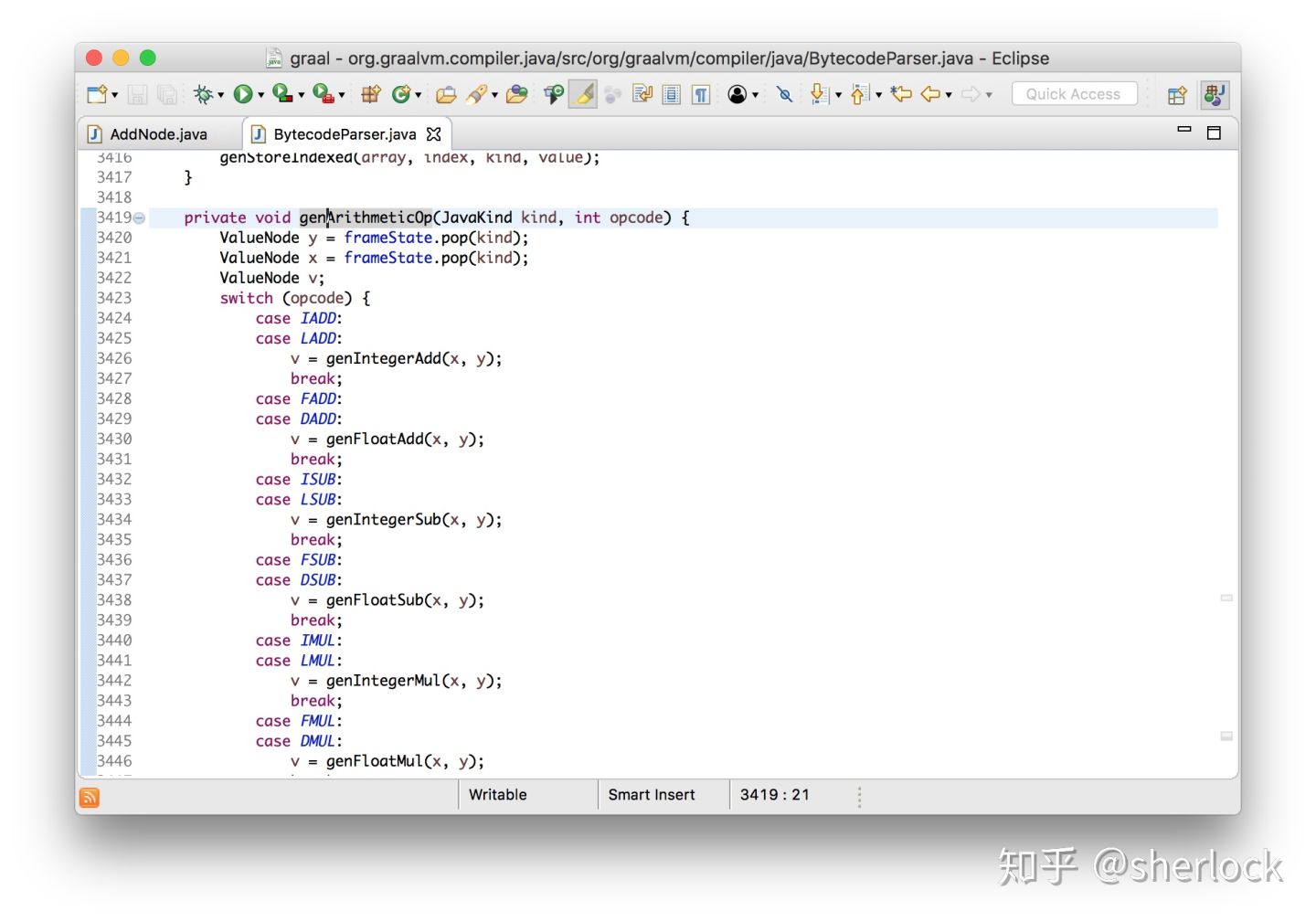
可以看到字节码解析器解析到iadd的时候创建了它们。如果这是一个真的jvm解释器,他会pop两个栈上的值,然后做加法,然后push结果到栈上。现在从栈上pop两个node表示计算的操作数,然后添加一个node表示加法操作,最后把它们push到栈上表示计算结果。如此操作我们得倒了graal graph。
3. 生成汇编
我们想要将graal graph转化为机器代码,需要为图中每个node生成机器代码。这一步在generate方法中完成。
void generate(Generator gen) {
gen.emitAdd(a, b);
}
再一次的,我们在高层次抽象上面工作,有一个类生成类加法的汇编,但是不知道细节。emitAdd的细节有点复杂和抽象,因为算数操作会根据operand的不同很多组合,并且不同的操作符可以共享绝大部分代码,所以我们简化一下程序
int workload(int a) {
return a + 1;
}
它使用加法指令,然后我会向你展示类似的汇编
void incl(Register dst) {
int encode = prefixAndEncode(dst.encoding);
emitByte(0xFF);
emitByte(0xC0 | encode);
}
void emitByte(int b) {
data.put((byte) (b & 0xFF));
}
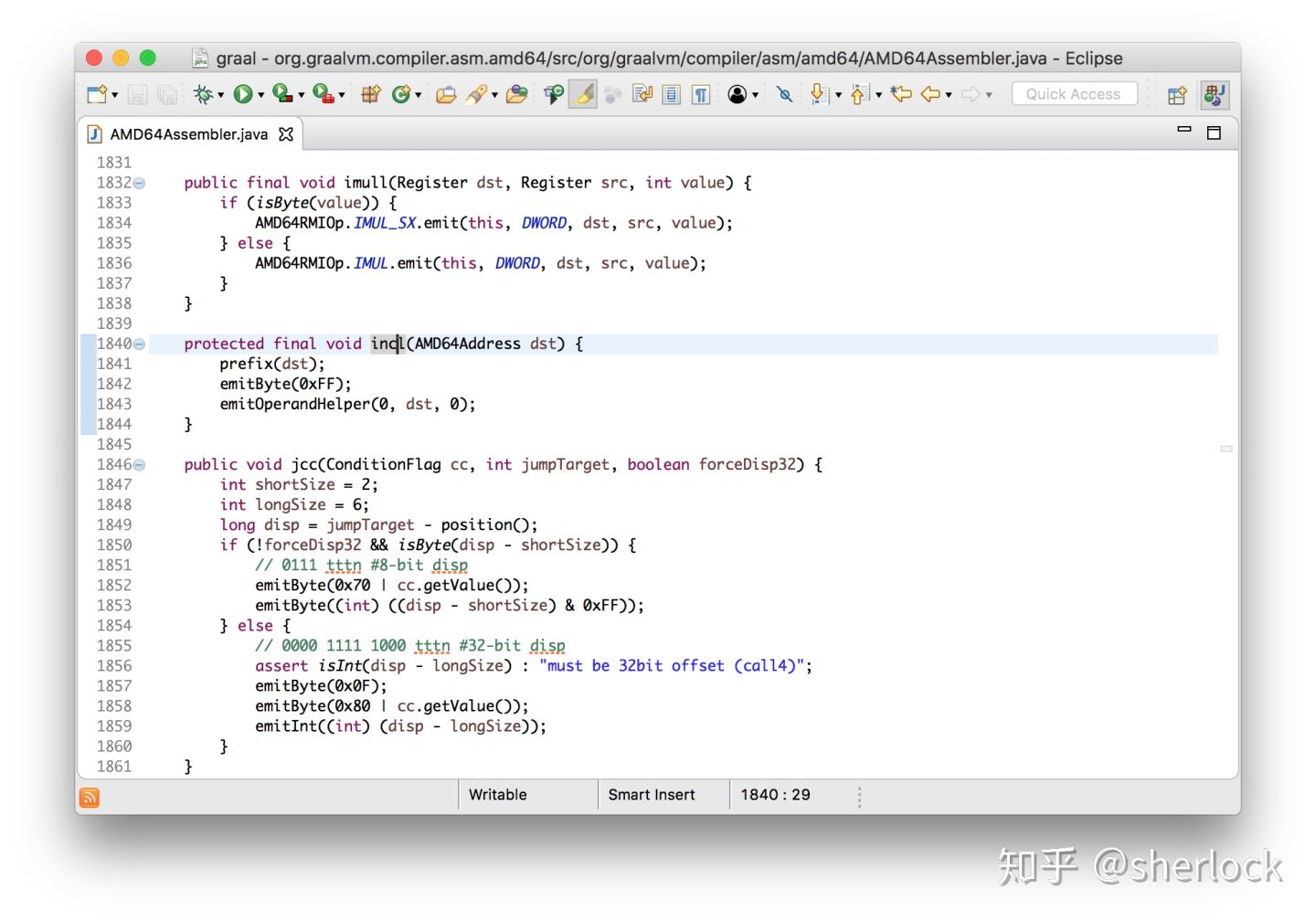
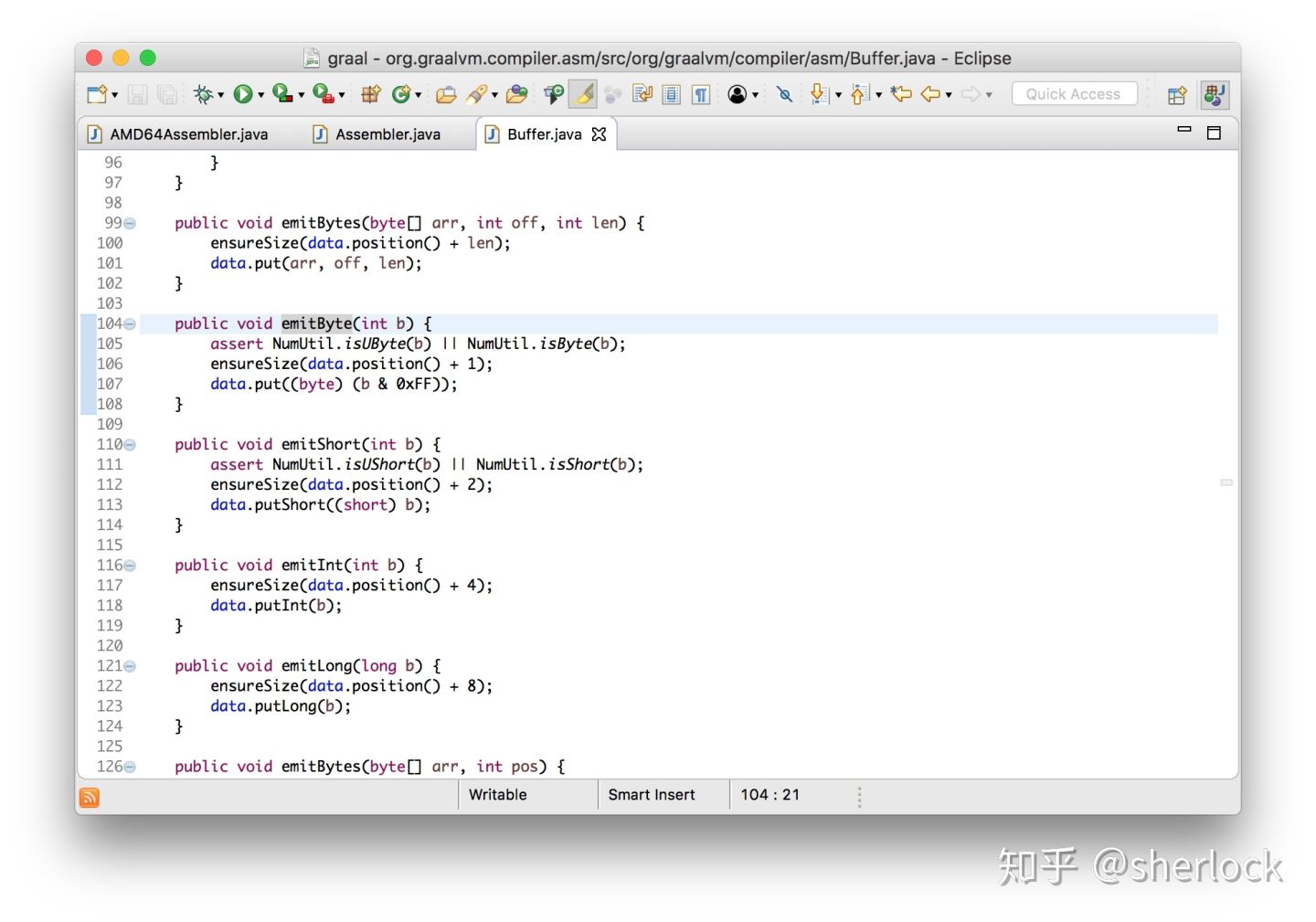
可以看到它生成字节作为输出,这些都放到一个标准的ByteBuffer里面——它可以用来构建字节数组
4. 汇编输出
和前面提到的字节码输入一样,我们看看机器代码的输出是什么样的。我们改一下源码让他log生成的机器码
class HotSpotGraalCompiler implements JVMCICompiler {
CompilationResult compileHelper(...) {
...
System.err.println(method.getName() + " machine code: "
+ Arrays.toString(result.getTargetCode()));
...
}
}
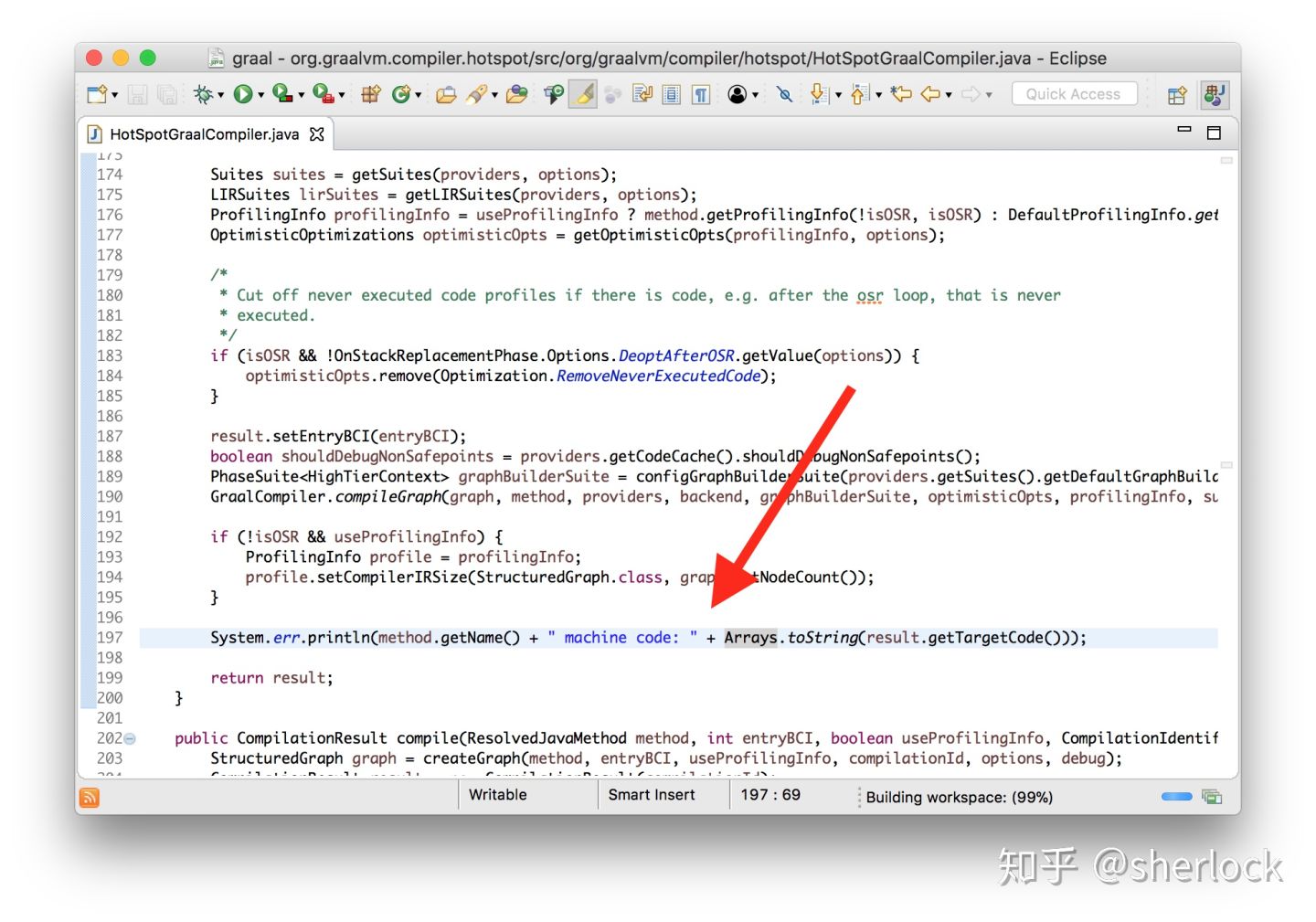
我们也可以使用一个工具反汇编生成的呃机器代码,它是hotspot的标准组件——不是graal的。我会展示怎么构建这个工具——它在openjdk仓库中但是默认没有在jvm中,所以只得自己构建它
$ cd openjdk/hotspot/src/share/tools/hsdis
$ curl -O http://ftp.heanet.ie/mirrors/gnu/binutils/binutils-2.24.tar.gz
$ tar -xzf binutils-2.24.tar.gz
$ make BINUTILS=binutils-2.24 ARCH=amd64 CFLAGS=-Wno-error
$ cp build/macosx-amd64/hsdis-amd64.dylib ../../../../../..
现在加上两个flag -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly
$ java
--module-path=graal/sdk/mxbuild/modules/org.graalvm.graal_sdk.jar:graal/truffle/mxbuild/modules/com.oracle.truffle.truffle_api.jar
--upgrade-module-path=graal/compiler/mxbuild/modules/jdk.internal.vm.compiler.jar
-XX:+UnlockExperimentalVMOptions
-XX:+EnableJVMCI
-XX:+UseJVMCICompiler
-XX:-TieredCompilation
-XX:+PrintCompilation
-XX:+UnlockDiagnosticVMOptions
-XX:+PrintAssembly
-XX:CompileOnly=Demo::workload
Demo
现在我们可以运行示例然后看看生成的加法指令
workload machine code: [15, 31, 68, 0, 0, 3, -14, -117, -58, -123, 5, ...]
...
0x000000010f71cda0: nopl 0x0(%rax,%rax,1)
0x000000010f71cda5: add %edx,%esi ;*iadd {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@2 (line 10)
0x000000010f71cda7: mov %esi,%eax ;*ireturn {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@3 (line 10)
0x000000010f71cda9: test %eax,-0xcba8da9(%rip) # 0x0000000102b74006
; {poll_return}
0x000000010f71cdaf: vzeroupper
0x000000010f71cdb2: retq
ok,为了检验我们是不是真的掌握了,我们修改一下加法的实现,用减法代替。我会修改generate方法的加法节点,然后生成减法
class AddNode {
void generate(...) {
... gen.emitSub(op1, op2, false) ... // changed from emitAdd
}
}
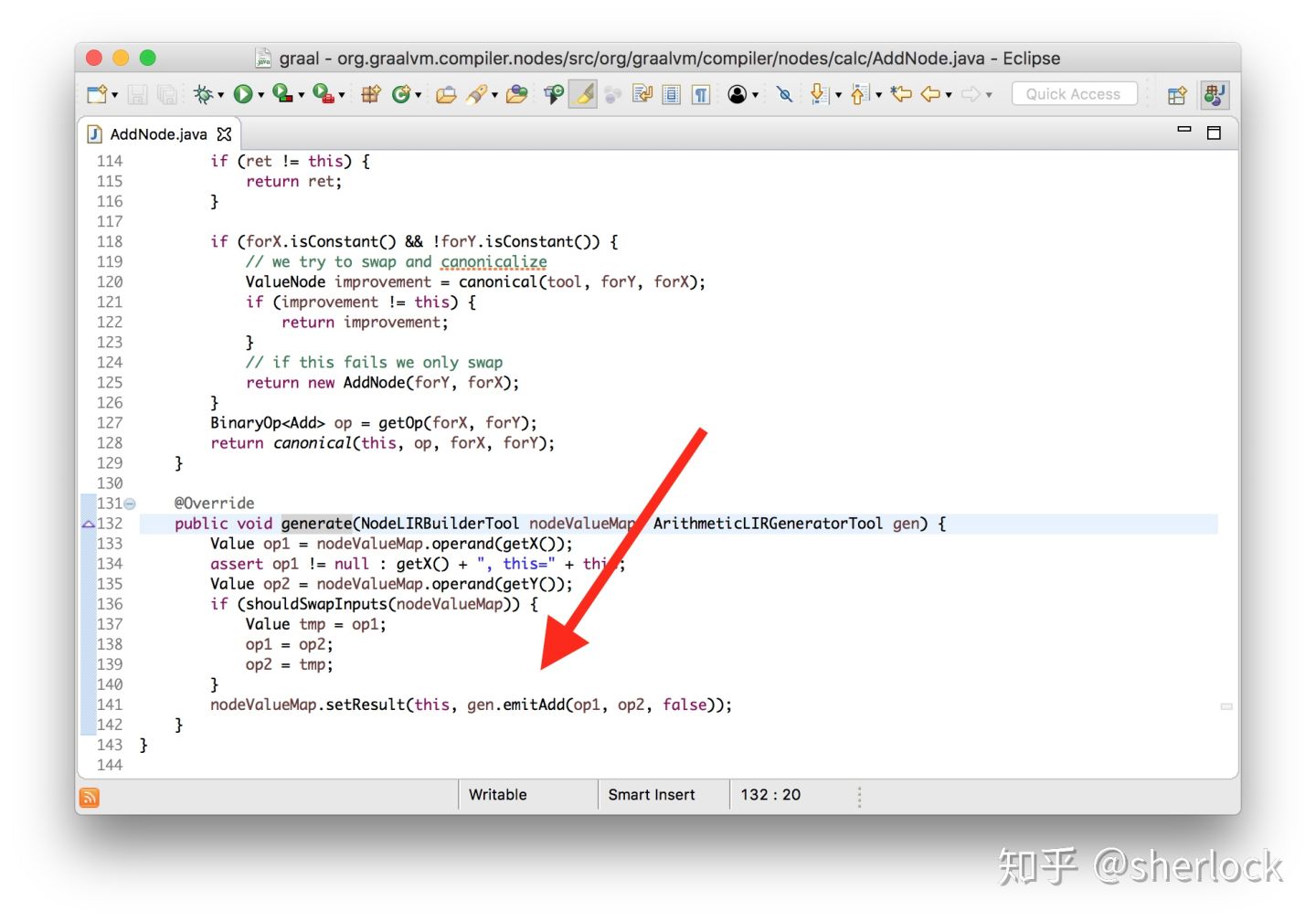
运行之后会看到生成的机器代码数组改变了,机器指令也改变了
workload mechine code: [15, 31, 68, 0, 0, 43, -14, -117, -58, -123, 5, ...]
0x0000000107f451a0: nopl 0x0(%rax,%rax,1)
0x0000000107f451a5: sub %edx,%esi ;*iadd {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@2 (line 10)
0x0000000107f451a7: mov %esi,%eax ;*ireturn {reexecute=0 rethrow=0 return_oop=0}
; - Demo::workload@3 (line 10)
0x0000000107f451a9: test %eax,-0x1db81a9(%rip) # 0x000000010618d006
; {poll_return}
0x0000000107f451af: vzeroupper
0x0000000107f451b2: retq
所以这里我们学到了什么?graal真的接受一个字节码数组,我们可以看到图node是如何从那个数组上创建的,我们可以看到机器代码是如何基于node生成的,然后机器指令是如何编码的。我们可以看到我们能改变graal工作机制。
[26, 27, 96, -84] → [15, 31, 68, 0, 0, 43, -14, -117, -58, -123, 5, ...]
优化
现在我们知道了怎么得到图表示,图node怎么生成机器代码,现在再让我们看看graal是怎么优化图让它高效的。
一个优化阶段(phase)是一个方法,它有修改图的机会。你要写一个优化阶段需要实现下面的接口。
interface Phase {
void run(Graph graph);
}
1. 规范化(Canonicalisation)
规范化意味着重排node,形成一个统一的表示,规范化还有些其他目的,不过这次ppt我们要说的是规范化意味着常量折叠和节点简化。
节点可以简化自身,它们本身有一个canonical方法
interface Node {
Node canonical();
}
让我们看看负节点(negate node),负节点即一元减法操作。如果一个一元减法作用于另一个一元减法,那么减法本身就会消除,只留下原始值,,即--x == x
class NegateNode implements Node {
Node canonical() {
if (value instanceof NegateNode) {
return ((NegateNode) value).getValue();
} else {
return this;
}
}
}
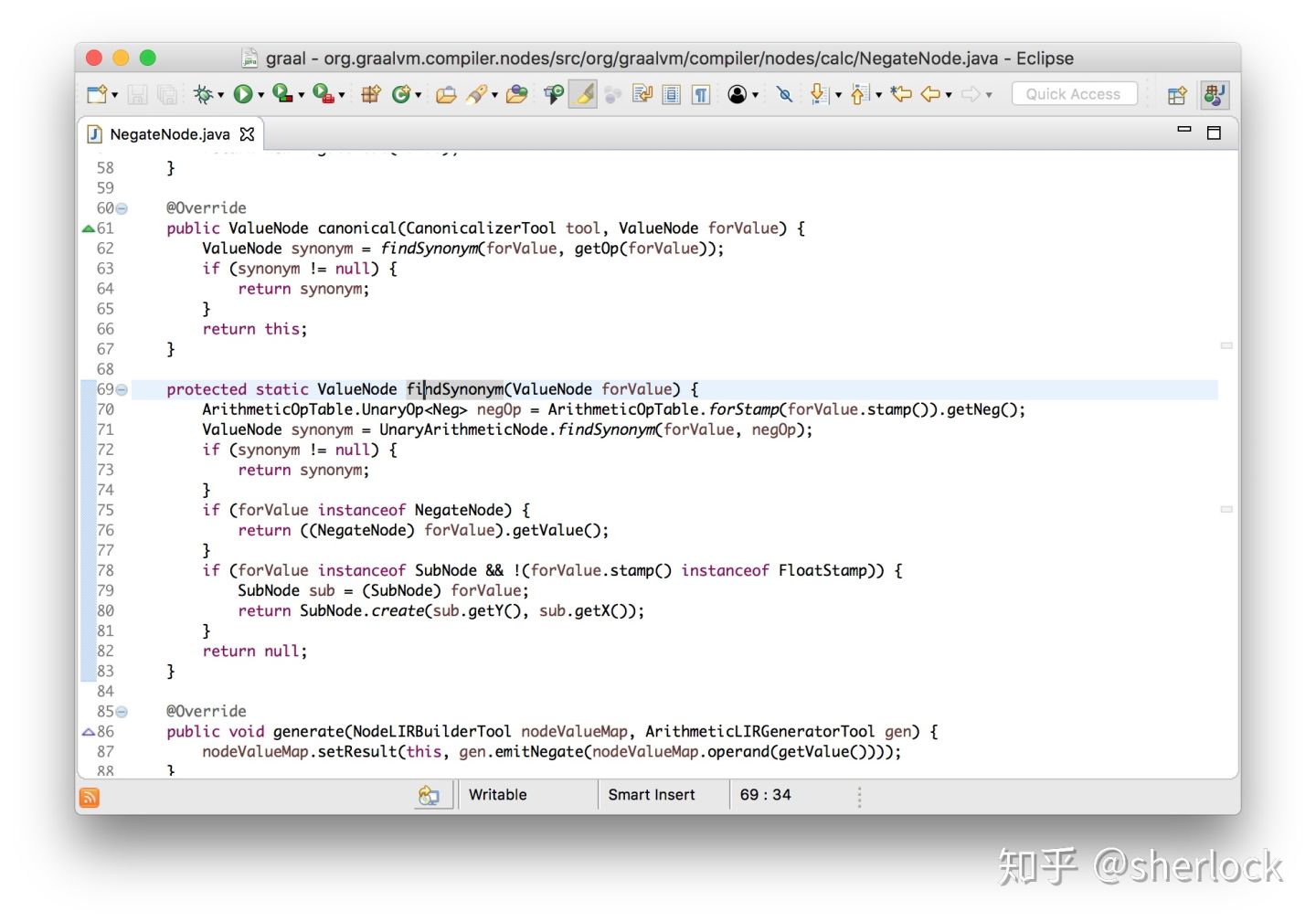
这是个理解graal绝佳的来自。代码逻辑已经不能在简化了。
如果你有一个java操作要简化,你可以修改canonical方法实现。
2. 全局值编号(global value numbering)
全局值编号是一种移除冗余代码的技术。这个例子中,a+b可以只计算一次,然后使用两次计算得倒的值。
int workload(int a, int b) {
return (a + b) * (a + b);
}
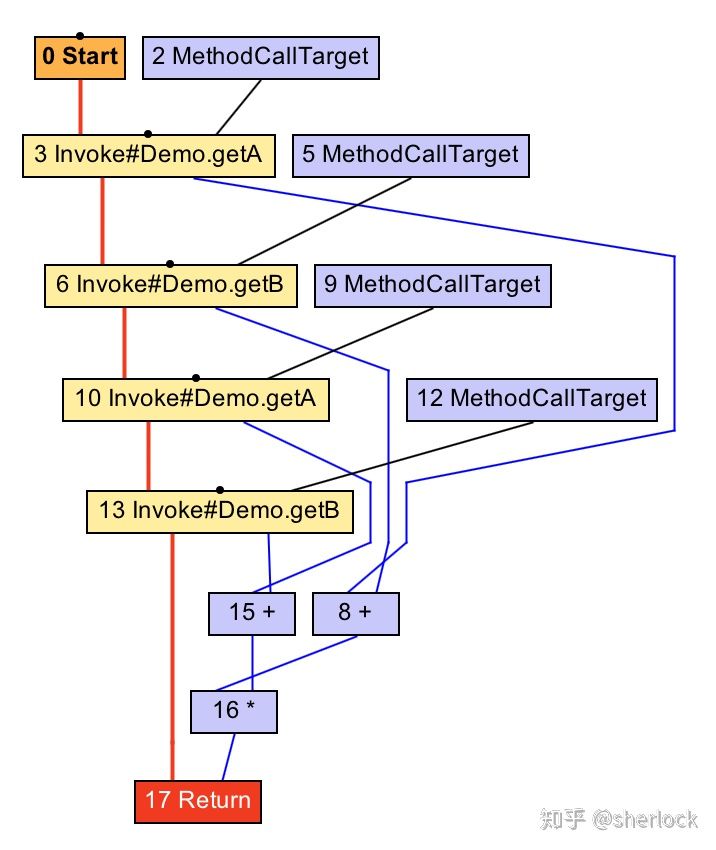
graal可以比较两个node看它们是否相等。如果相等则简化。graal的全局值编号阶段会迭代检查每个节点是否和其他任何节点相等,,如果相等就会替换为另一个节点的拷贝。他把所有节点放入hash map,这样可以高效完成。有点类似于node缓存。
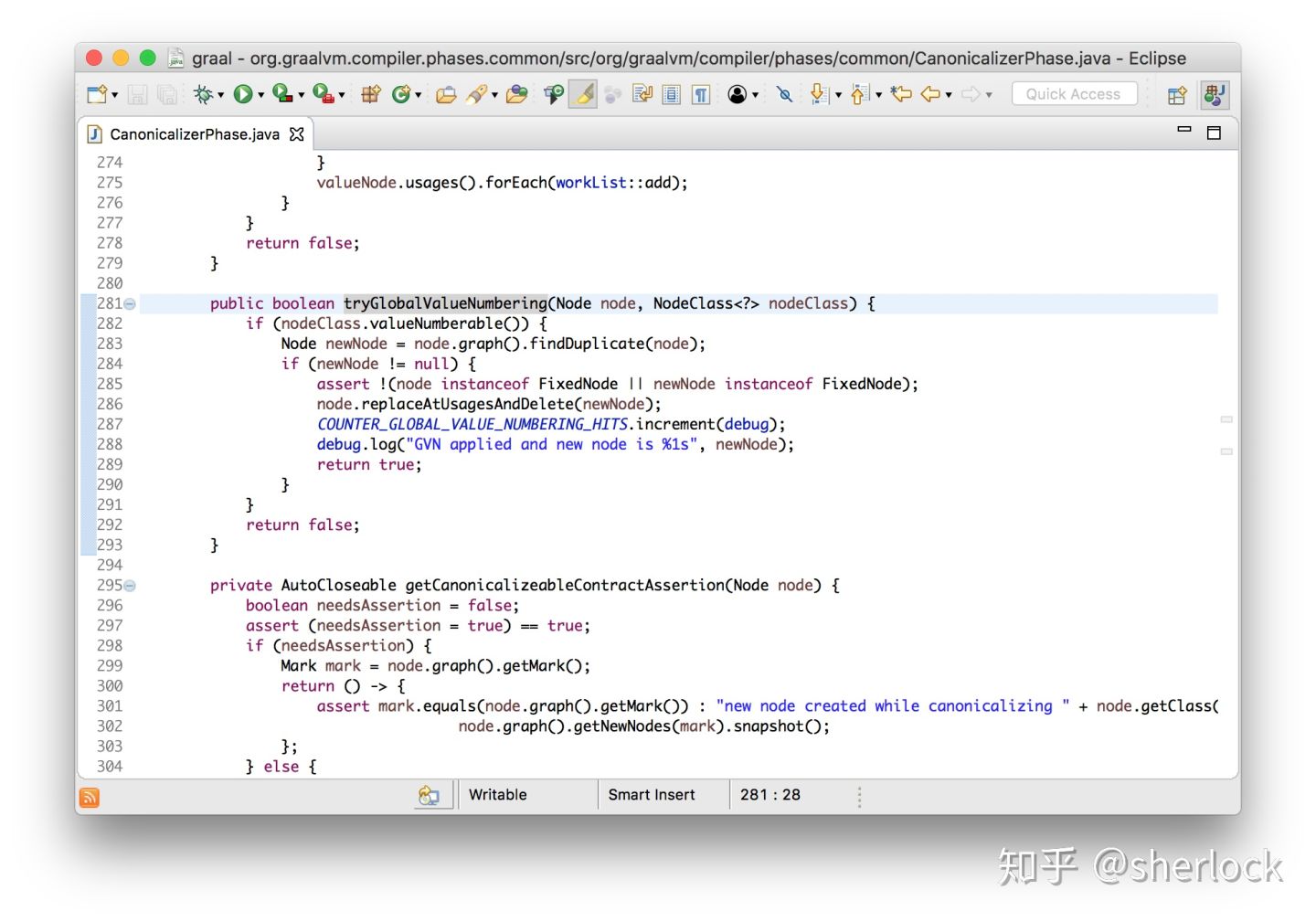
注意测试节点不是固定的,这意味着节点在某个确定的时间不能有副作用。如果我们使用方法调用代替,就变成了确定的
int workload() {
return (getA() + getB()) * (getA() + getB());
}
3. 锁粗化(lock coarsening)
来看一个更复杂的例子。有时候我们会在一个小范围内对同一个对象多次使用synchonrized,虽然可能不会有意为之,但是编译器内联优化可能会导致那种代码产生。
void workload() {
synchronized (monitor) {
counter++;
}
synchronized (monitor) {
counter++;
}
}
我们可以对它进行去糖化,然后高效实现
void workload() {
monitor.enter();
counter++;
monitor.exit();
monitor.enter();
counter++;
monitor.exit();
}
我们可以优化这段代码,只进出一次monitor而不是多次进出,这就是锁粗化
void workload() {
monitor.enter();
counter++;
counter++;
monitor.exit();
}
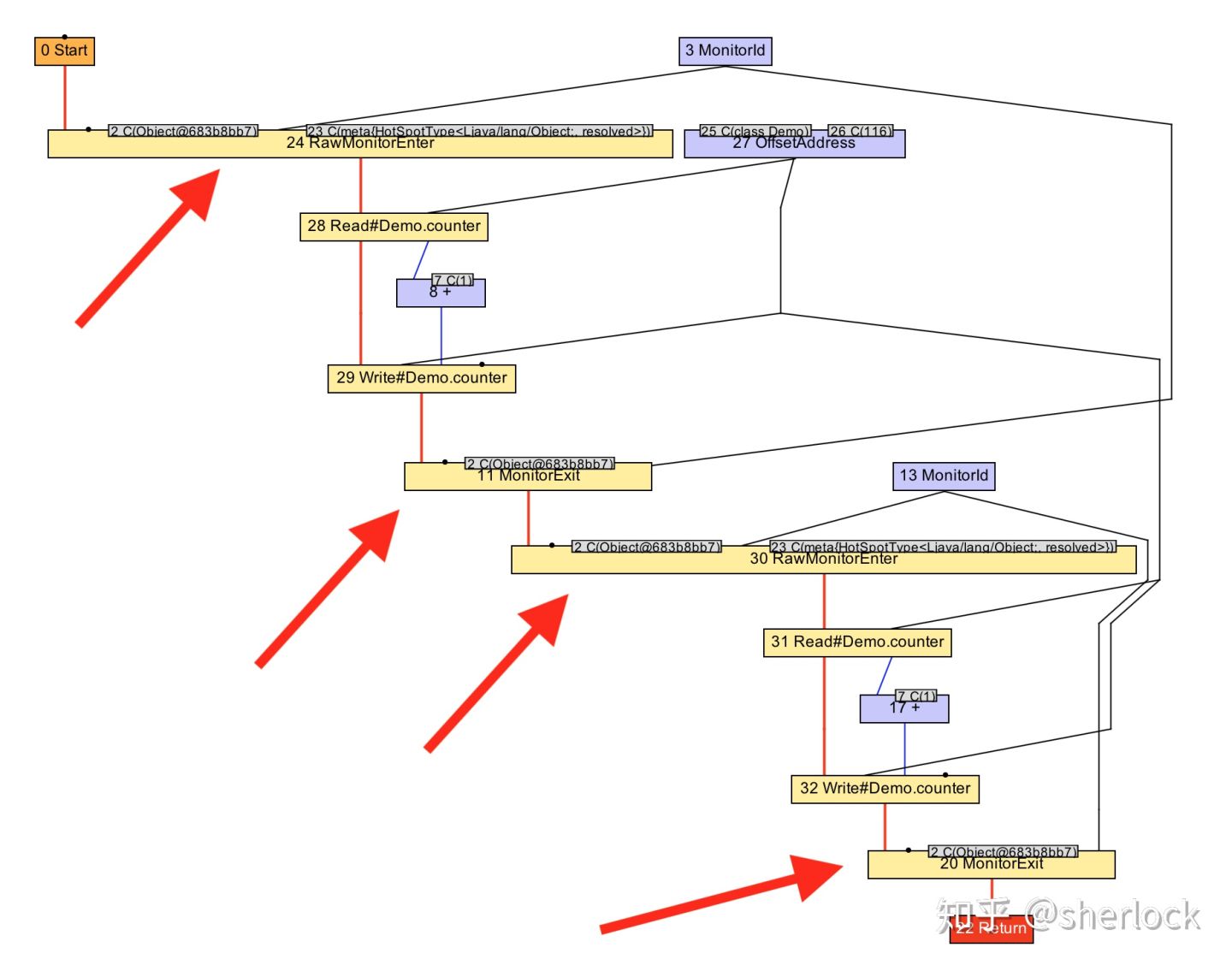
在graal中锁粗化由 LockEliminationPhase这个阶段实现。它的 run 方法查看所有monitor退出节点,然后看它们是否后面马上跟一个monitor 进入节点。如果后面确认使用了使用了相同的monitor,会移除它们,只留下一个monitor进/出节点。
void run(StructuredGraph graph) {
for (monitorExitNode monitorExitNode : graph.getNodes(MonitorExitNode.class)) {
FixedNode next = monitorExitNode.next();
if (next instanceof monitorEnterNode) {
AccessmonitorNode monitorEnterNode = (AccessmonitorNode) next;
if (monitorEnterNode.object() == monitorExitNode.object()) {
monitorExitNode.remove();
monitorEnterNode.remove();
}
}
}
}
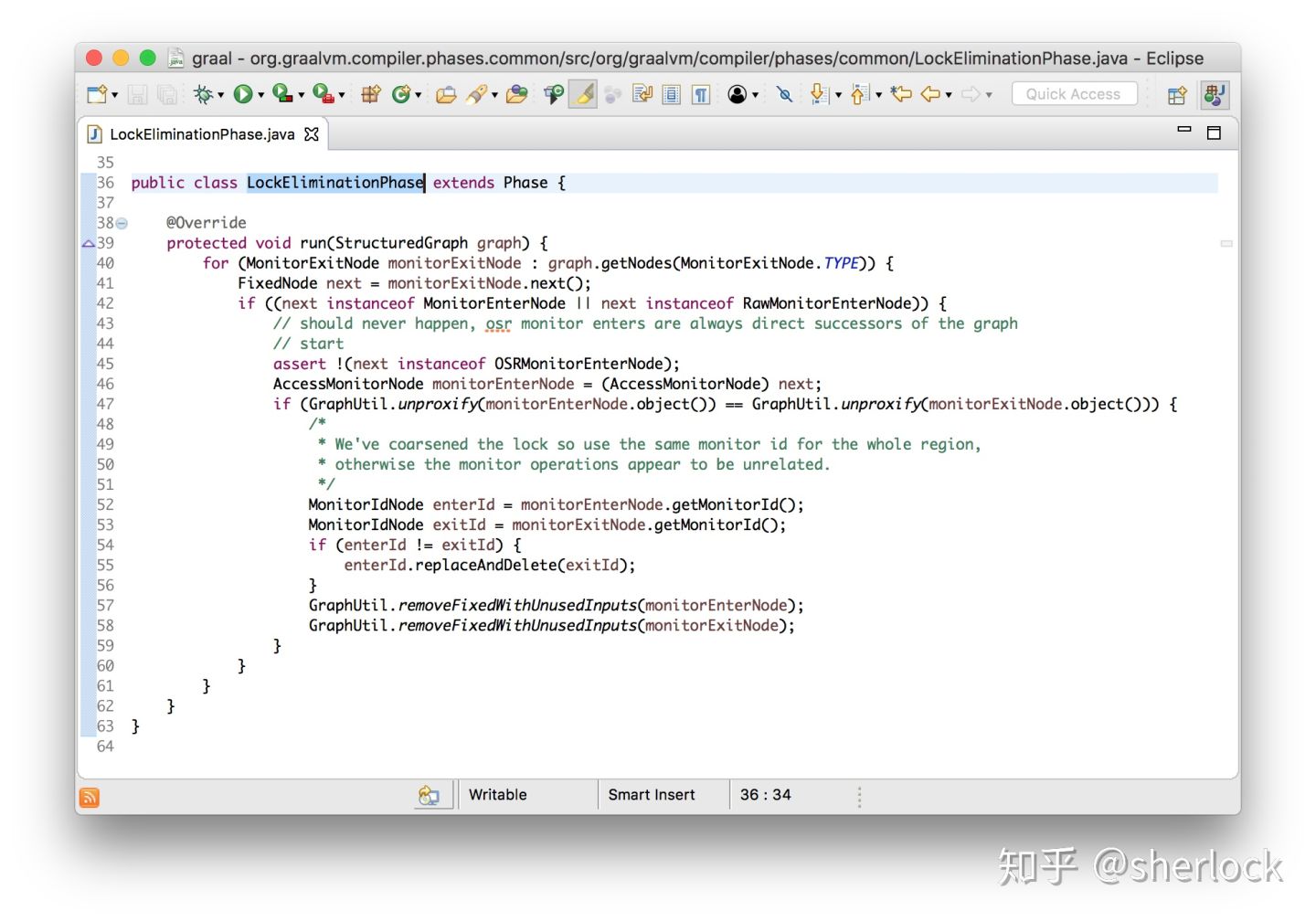
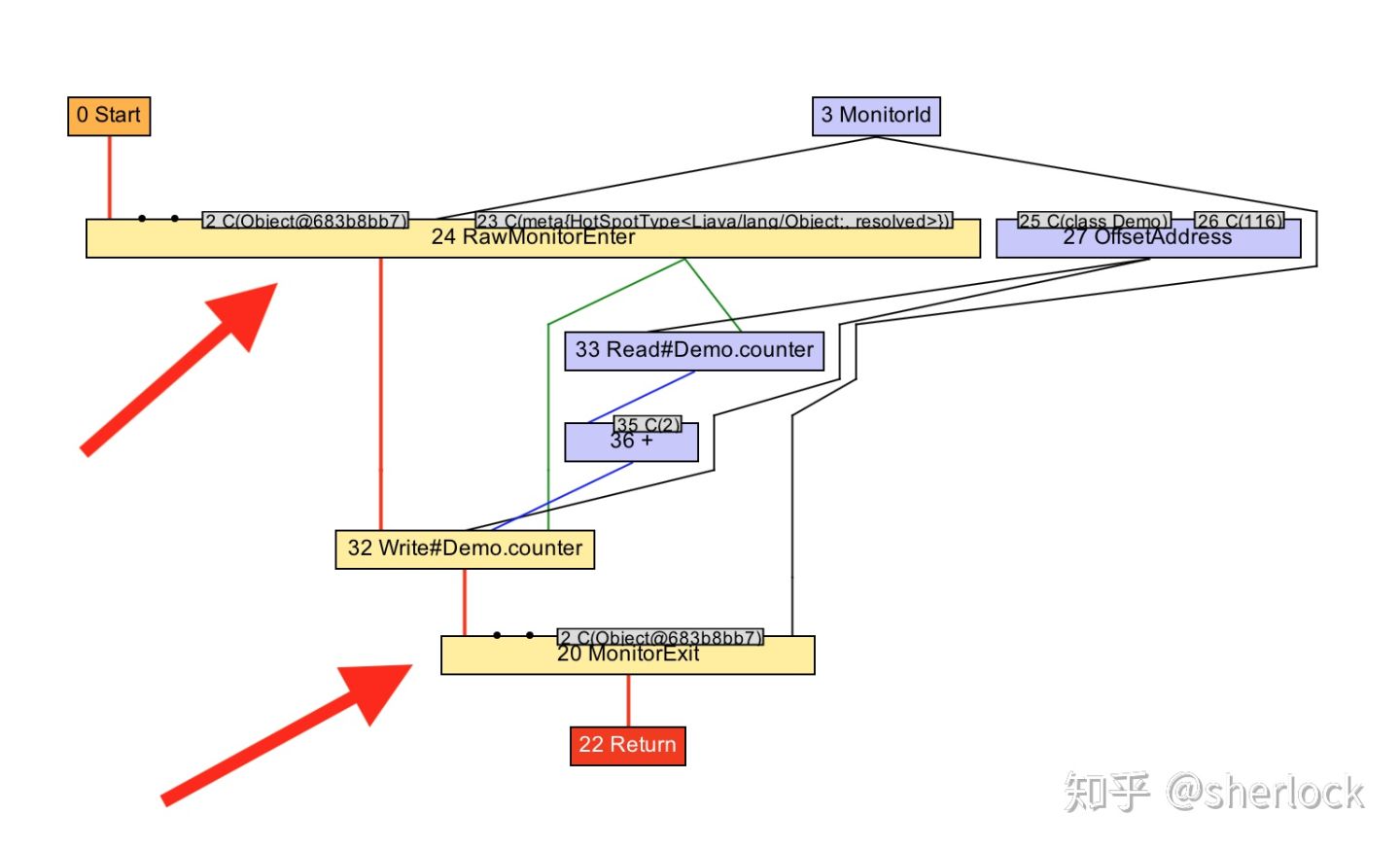
这样做是值得的,因为少了额外monitor进/出意味着代码变少了,其实这里还允许我们继续优化,可以把两个递增组合起来变成+2
void workload() {
monitor.enter();
counter += 2;
monitor.exit();
}
让我们用IGV看看。可以看到原图有两对monitoer enter/exit,然后变成了一对,当优化phase运行之后,两个递增变成了一个加法。