1. 简介
生成式模型(generative model)会对(x)和(y)的联合分布(p(x,y))进行建模,然后通过贝叶斯公式来求得(p(y|x)), 最后选取使得(p(y|x))最大的(y_i). 具体地, (y_{*}=arg max_{y_i}p(y_i|x)=arg max_{y_i}frac{p(x|y_i)p(y_i)}{p(x)}=arg max_{y_i}p(x|y_i)p(y_i)=arg max_{y_i}p(x,y_i)).
判别式模型(discriminative model)则会直接对(p(y|x))进行建模.
关于二者之间的优劣有大量的讨论. SVM的发明者Vapnik声称"one should solve the (classification) problem directly and never solve a more general problem as an intermediate step [such as modeling p(x|y)]", 但是, 最近Deep Learning大行其道, 其代表性算法DBN就是生成式模型. 通常来说, 因为生成式模型要对类条件密度(class conditional density)(p(x|y_i))进行建模, 而判别式模型只需要对类后验密度(class-posterior density)进行建模, 前者通常会比后者要复杂, 更难以建模, 如下图所示.
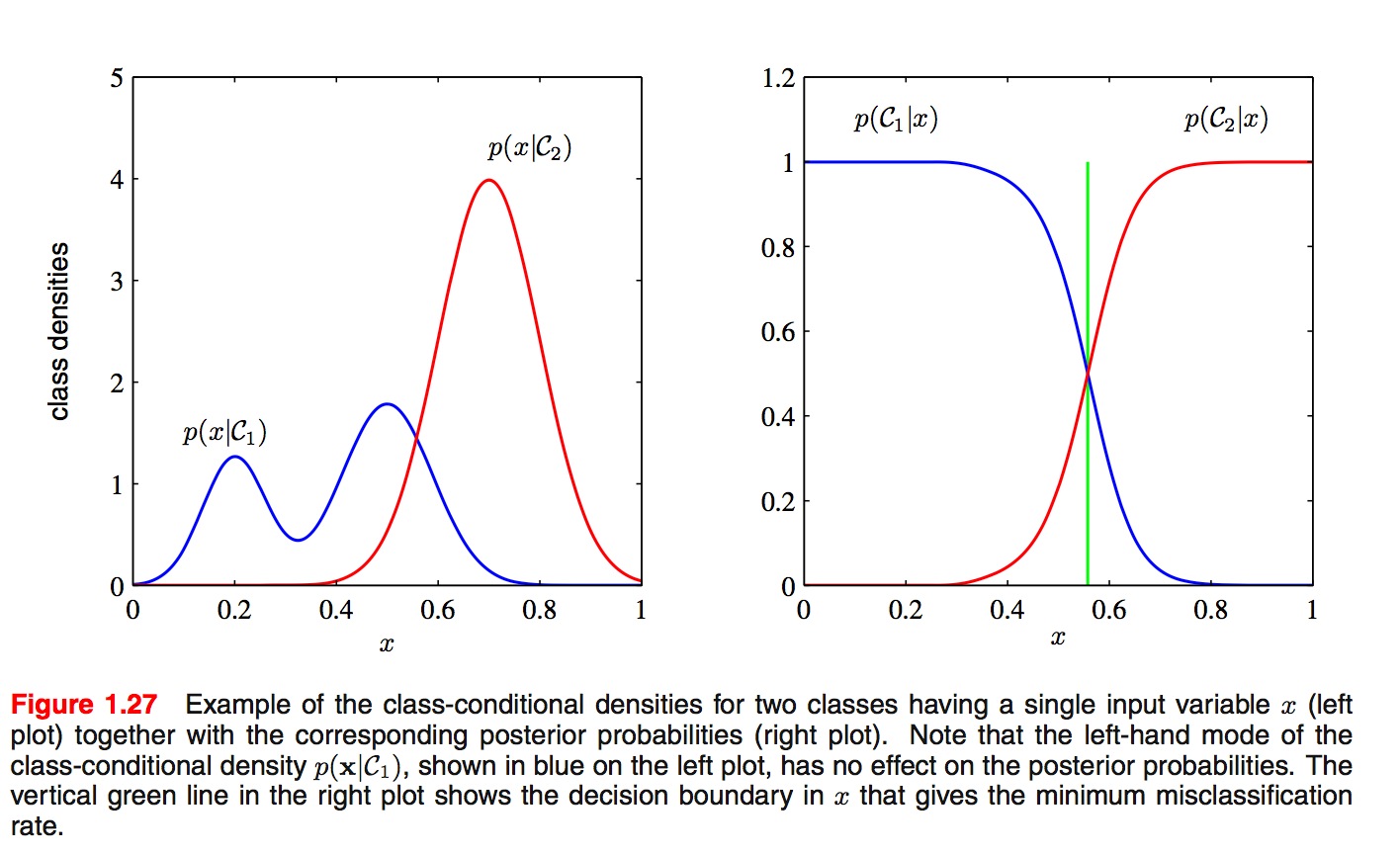
2. 对比
下面简单比较下生成式模型和判别式模型的优缺点.
1. 一般来说, 生成式模型都会对数据的分布做一定的假设, 比如朴素贝叶斯会假设在给定(y)的情况下各个特征之间是条件独立的:(p(X|y)=prod_{i=1}^{N}p(x_i|y)), GDA会假设
(p(X|y=c, heta)=mathcal{N}(mu_c,Sigma_c)). 当数据满足这些假设时, 生成式模型通常需要较少的数据就能取得不错的效果, 但是当这些假设不成立时, 判别式模型会得到更好的效果.
2. 生成式模型最终得到的错误率会比判别式模型高, 但是其需要更少的训练样本就可以使错误率收敛[限于Genarative-Discriminative Pair, 详见[2]].
3. 生成式模型更容易拟合, 比如在朴素贝叶斯中只需要计下数就可以, 而判别式模型通常都需要解决凸优化问题.
4. 当添加新的类别时, 生成式模型不需要全部重新训练, 只需要计算新的类别(y_new)和(x)的联合分布(p(y_new,x))即可, 而判别式模型则需要全部重新训练.
5. 生成式模型可以更好地利用无标签数据(比如DBN), 而判别式模型不可以.
6. 生成式模型可以生成(x), 因为判别式模型是对(p(x,y))进行建模, 这点在DBN的CD算法中中也有体现, 而判别式模型不可以生成(x).
7. 判别式模型可以对输入数据(x)进行预处理, 使用(phi(x))来代替(x), 如下图所示, 而生成式模型不是很方便进行替换.

左图中直接使用(x)进行逻辑斯蒂回归, 而右图则使用径向基核对(x)进行变换后再使用逻辑斯蒂回归.
3. 二者所包含的算法
3.1 生成式模型
- 判别式分析
- 朴素贝叶斯
- K近邻(KNN)
- 混合高斯模型
- 隐马尔科夫模型(HMM)
- 贝叶斯网络
- Sigmoid Belief Networks
- 马尔科夫随机场(Markov Random Fields)
- 深度信念网络(DBN)
3.2 判别式模型
- 线性回归(Linear Regression)
- 逻辑斯蒂回归(Logistic Regression)
- 神经网络(NN)
- 支持向量机(SVM)
- 高斯过程(Gaussian Process)
- 条件随机场(CRF)
- CART(Classification and Regression Tree)
参考文献:
[1]. Kevin P. Murphy. Machine Learning: A Probabilistic Perspective, Chapter 8.6, Page267-271.
[2]. Andrew Y. Ng, Micheal I. Jordan. On Discrimintive vs. Generative Classifiers: A comparison of logistic regression and naive Bayes.
[3]. Stack Overflow: What is the difference between a Generative and Discriminative Algorithm?