1. 简单工厂模式
1.1 日志工厂
在实际项目开发过程中,日志其实有点复杂。首先,日志的实现就有很多种:
- log4j:Apache Log4j是一个基于Java的日志记录工具。
- log4j2:Apache Log4j 2是 apache 开发的一款Log4j的升级产品
- Commons Logging Apache基金会所属的项目,是一套Java日志接口,之前叫Jakarta Commons Logging,后更名为Commons Logging。
- Slf4j 类似于Commons Logging,是一套简易Java日志门面,本身并无日志的实现。(Simple Logging Facade for Java,缩写Slf4j)。
- Jul (Java Util Logging):自 Java1.4 以来的官方日志实现
- Logback: 一套日志组件的实现(Slf4j阵营)。
看了上面的介绍是否会觉得比较混乱,这些日志框架之间有什么异同,都是由谁在维护,在项目中应该如何选择日志框架,应该如何使用? 有兴趣的可以去了解一下 here
这时候作为一个第三方框架,例如 MyBatis,Tomcat 等,肯定不能直接选择某一款日志框架,否则假设“应用程序开发程序员”直接引入“你开发的框架”到应用程序项目中时,应用程序项目出现了 2 种不同的日志框架。
所以第三方框架应该使用和应用程序开发者一致的日志框架来打印日志,这样才能保证应用中只有一套日志体系。
那么架构师们是如何做到第三方框架和它的使用方保持一致的日志体系的呢?以面试常问的框架 Mybatis 为例。
1.1.1 LogFactory 源码
你可以选择创建一个 Maven 项目,并引入 MyBatis 依赖:
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
或者在 GitHub 上在线阅读源码 LogFactory
package org.apache.ibatis.logging;
import java.lang.reflect.Constructor;
/**
* @author Clinton Begin
* @author Eduardo Macarron
*/
public final class LogFactory {
/**
* Marker to be used by logging implementations that support markers.
*/
public static final String MARKER = "MYBATIS";
private static Constructor<? extends Log> logConstructor;
static {
// 依次尝试初始化以下 Log 类构造器
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
private LogFactory() {
// disable construction
}
// 工厂方法,用 clazz 做参数创建一个 Log 实例
public static Log getLog(Class<?> clazz) {
return getLog(clazz.getName());
}
// 工厂方法,用字符串做参数创建一个 Log 实例
public static Log getLog(String logger) {
try {
return logConstructor.newInstance(logger);
} catch (Throwable t) {
throw new LogException("Error creating logger for logger " + logger + ". Cause: " + t, t);
}
}
public static synchronized void useCustomLogging(Class<? extends Log> clazz) {
setImplementation(clazz);
}
public static synchronized void useSlf4jLogging() {
setImplementation(org.apache.ibatis.logging.slf4j.Slf4jImpl.class);
}
public static synchronized void useCommonsLogging() {
setImplementation(org.apache.ibatis.logging.commons.JakartaCommonsLoggingImpl.class);
}
public static synchronized void useLog4JLogging() {
setImplementation(org.apache.ibatis.logging.log4j.Log4jImpl.class);
}
public static synchronized void useLog4J2Logging() {
setImplementation(org.apache.ibatis.logging.log4j2.Log4j2Impl.class);
}
public static synchronized void useJdkLogging() {
// 稍微提一嘴:这个jdk14表示的是 jdk1.4,因为 java util logging 是 java 1.4 的日志官方实现
setImplementation(org.apache.ibatis.logging.jdk14.Jdk14LoggingImpl.class);
}
public static synchronized void useStdOutLogging() {
setImplementation(org.apache.ibatis.logging.stdout.StdOutImpl.class);
}
public static synchronized void useNoLogging() {
setImplementation(org.apache.ibatis.logging.nologging.NoLoggingImpl.class);
}
private static void tryImplementation(Runnable runnable) {
// 如果 logConstructor 没有初始化成功,则继续尝试 runnable 中的代码
// 否则不进入 if 分支,即啥都不干
if (logConstructor == null) {
try {
// 这里是同步调用,多线程必学知识点,与 new Thread(runnable).start() 的异步调用不同!
runnable.run();
} catch (Throwable t) {
// ignore
}
}
}
private static void setImplementation(Class<? extends Log> implClass) {
try {
// 获取类的构造函数,参数为 String
Constructor<? extends Log> candidate = implClass.getConstructor(String.class);
// 这个 Log 是 mybatis 中定义的接口: org.apache.ibatis.logging.Log
Log log = candidate.newInstance(LogFactory.class.getName());
// 如果实例化成功,那么就立即打印一段 debug 日志
if (log.isDebugEnabled()) {
log.debug("Logging initialized using '" + implClass + "' adapter.");
}
// 赋值给 logConstructor,之后在 mybatis 的类中调用 getLog
logConstructor = candidate;
} catch (Throwable t) {
throw new LogException("Error setting Log implementation. Cause: " + t, t);
}
}
}
这个 LogFactory 最大的作用就是简化了日志框架的选择。
1.1.2 Log 日志工厂

LogFactory(工厂):核心部分,负责实现创建产品的内部逻辑,工厂类可以被外界直接调用,创建所需对象
Log(抽象类产品):工厂类所创建的所有对象的父类,封装了产品对象的公共方法,所有的具体产品为其子类对象
Slf4jImpl(具体产品):简单工厂模式的创建目标,所有被创建的对象都是某个具体类的实例。它要实现抽象产品中声明的抽象方法(有关抽象类)
1.2 “非典型”简单工厂模式
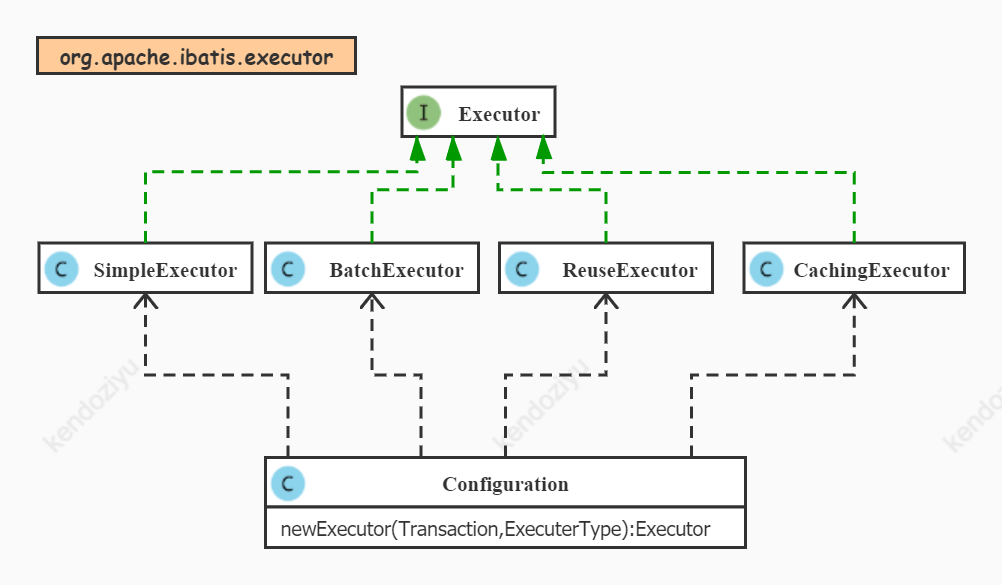
并不是命名时一定要加 Factory 这个单词才一定是简单工厂模式,以 MyBatis 源码中的“大管家” Configuration 为例,其中创建执行器对象 Executor 的代码也是简单工厂模式
1.2.1 Configuration.newExecutor
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根据 ExecutorType 枚举类型不同,生成对应的 Executor 实例
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 如果开启了二级缓存,则用 CachingExecutor
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 再为 executor 加上拦截器
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
从这段代码,我们可以总结一些使用工厂模式的意义:
1、降低对象构建的复杂度
2、标准化生产,加工处理(装饰、代理)
1.2.2 Executor 执行器工厂
1.3 评价优缺点和适用场景
简单工厂模式的优点
(1)封装性强:工厂类包含必要的逻辑判断,可以决定在什么时候创建哪一个产品的实例。客户端可以免除直接创建产品对象的职责
(2)客户端无需知道所创建具体产品的类名,只需知道参数即可
(3)也可以引入配置文件,在不修改客户端代码的情况下更换和添加新的具体产品类。
简单工厂模式的缺点
(1)工厂类集中了所有产品的创建逻辑,职责过重,一旦异常,整个系统将受影响
(2)使用简单工厂模式会增加系统中类的个数(引入新的工厂类),增加系统的复杂度和理解难度
(3)扩展性差:系统扩展困难,一旦增加新产品不得不修改工厂逻辑,在产品类型较多时,可能造成逻辑过于复杂
(4)简单工厂模式使用了static工厂方法,造成工厂角色无法形成基于继承的等级结构。
简单工厂模式的适用环境
(1)工厂类负责创建对的对象比较少,因为不会造成工厂方法中的业务逻辑过于复杂
(2)客户端只知道传入工厂类的参数,对如何创建对象不关心
2. 工厂方法模式
简单工厂模式中如果要增加一个产品种类,需要改动创建方法,扩展性不强。
- 比如 MyBatis 的 LogFactory 类中,static {} 静态块中需要引入新增加的日志实现类。
- 再比如 MyBatis 的 Configuration.newExecutor 需要增加 if 分支,同时 ExecutorType 中也需要增加新的类型。
工厂方法模式可以解决这一问题,即每个产品都有一个独有的工厂类来实现,当需要添加新产品时只要拓展新的工厂类即可。
2.1 Dubbo 注册中心
假如你也是 Maven 项目,你可以引入 dubbo 依赖来查看 dubbo 源码。
<!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>2.7.8</version>
</dependency>
2.1.2 类结构图

比如说 Nacos 注册方式是在 2.6.5 版本新增加的。所以在这个版本新增了 NaocsRegistryFactory 和 NacosRegistry 类,而不需要改动原先的代码。
另外 Dubbo 实现了一套自己的 SPI 机制,可以根据不同的协议头,创建或者获取不同的注册中心。
你可以查看一下 META-INF/dubbo.internal/org.apache.dubbo.registry.RegistryFactory, 这个文件配置了协议头和类的对应关系:
org.apache.dubbo.registry.RegistryFactory
service-discovery-registry=org.apache.dubbo.registry.client.ServiceDiscoveryRegistryFactory
wrapper=org.apache.dubbo.registry.RegistryFactoryWrapper
dubbo=org.apache.dubbo.registry.dubbo.DubboRegistryFactory
multicast=org.apache.dubbo.registry.multicast.MulticastRegistryFactory
zookeeper=org.apache.dubbo.registry.zookeeper.ZookeeperRegistryFactory
redis=org.apache.dubbo.registry.redis.RedisRegistryFactory
consul=org.apache.dubbo.registry.consul.ConsulRegistryFactory
etcd3=org.apache.dubbo.registry.etcd.EtcdRegistryFactory
nacos=org.apache.dubbo.registry.nacos.NacosRegistryFactory
sofa=org.apache.dubbo.registry.sofa.SofaRegistryFactory
multiple=org.apache.dubbo.registry.multiple.MultipleRegistryFactory
2.2 优缺点分析
优点:
(1) 创建产品简单:用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程。
(2)扩展性增强:对于新产品的创建,只需多写一个相应的工厂类。
典型的解耦框架。高层模块只需要知道产品的抽象类,无须关心其他实现类,满足迪米特法则、依赖倒置原则和里氏替换原则。
缺点:
(1)类的个数容易过多,增加复杂度
(2)增加了系统的抽象性和理解难度
(3)抽象产品只能生产一种产品,此弊端可使用抽象工厂模式解决。
3. 抽象工厂模式
抽象工厂模式有一个特点,就是可以创建多个“同系列”产品。但是,笔者目前也没有找到抽象工厂模式在 Java 开源项目中存在?如果有厉害的朋友遇到过,不妨告诉我。
3.1 类结构图
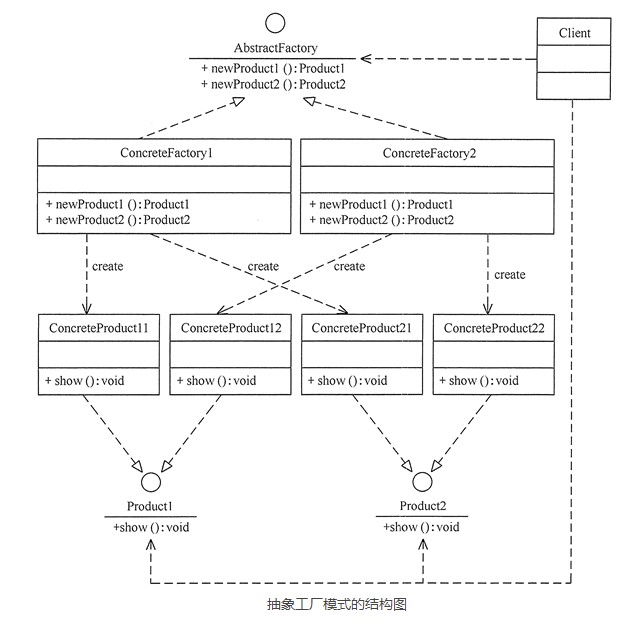
拿智能手机举例:
AbstractFactory 可以理解为手机出品厂商。
所谓产品族,在可以理解为品牌,就比方说 ConcreteFactory1 是小米手机族,ConcreteFactory2 是苹果手机族。
产品 Product1 指操作系统,Product2 指硬件。
那么,ConcreteProduct11 可以指小米的操作系统 MIUI,ConcreteProduct12 则指苹果的操作系统 OS。
然后,ConcreteProduct21 可以指小米的硬件,ConcreteProduct22 则指苹果的硬件。
软硬件需要配合使用,操作系统和硬件并不是完全独立的,而是相互依赖的。这一点和工厂方法模式不同,工厂方法模式中不同类型的工厂生产出来的产品,一般来说是相互独立的。
3.2 分析
优点:
(1)减少工厂类的数量:可以在类的内部对产品族中相关联的多等级产品共同管理,而不必专门引入多个新的类来进行管理。
(2)当需要产品族时,抽象工厂可以保证客户端始终只使用同一个产品的产品组。
(3)抽象工厂增强了程序的可扩展性,当增加一个新的产品族时,不需要修改原代码,满足开闭原则。
缺点:
当产品族中需要增加一个新的产品时,所有的工厂类都需要进行修改。增加了系统的抽象性和理解难度。
比如,新增产品种类 Product3 接口,需要增加 ConcreteProduct31 ... ConcreteProduct3n 这些,修改 AbstractFactory 代码增加抽象方法 createProduct3():Product3。然后还需要修改 ConcreteFactory1, ConcreteFactory2 ... 还需要增加 ConcreteFactoryn。
啊... 想想就头皮发麻。