写在前面
※ 关于 Kafka:
作为当代的 Java 开发工程师,在 Spring 的项目中,用到 Kafka 作为中间件是家常便饭。
但是,Kafka 是用 Scala 语言编写的服务,对 Java 程序员不是那么友好,尤其 Apache Kafka 客户端中也有大量 Scala 代码,导致学习成本上升。
※ 问题背景:
最近,我就遇到了一件头疼的事情————我们的 Spring 项目用到了 Apache Kafka 的客户端,在集群部署时,仅有一台服务器正常打印消费日志,其他服务则没有消费日志。
换句话说,看起来仅有一台服务器在“工作”,且把消费消息的“工作”包揽了。
所以,我需要了解一下 Apache Kafka 客户端的应用。PS:如果是想要了解 Kafka 与 SpringBoot 的整合,建议去搜索 Kafka SpringBoot,有大量文章讲解这个,但这不是本文的重点。
新旧Kafka版本
一开始,我去百度搜索关键字“Kafka客户端”,各种资料看得我眼花缭乱,但是却有很强的相互干扰性。因此,我先把各类不同的Kafka客户端代码归个类,你可以看一下代码对号入座。
| Kafka Broker集群版本 | 备注 |
|---|---|
| 0.8.2.2 | 早期使用Kafka的公司,用得最多的就是0.8.2.2这个版本,这个版本的Kafka 刚刚推出Java版producer ,而Java consumer 甚至还没有开发。 |
| 1.0.0 | 有不少公司选择在1.0.0版本开始使用Kafka,自l.0.0 版本开始, Kafka 正式进入到1.0 稳定版本 |
其他的一些版本,你可以阅读《Apache Kafka实战》————2.2 Kafka版本变迁————2.2.1 Kafka的版本演进。但是目前生产实践一般都是上面两个版本二选一。
当然,作为 Java 开发工程师,最关心的当然是 Maven 依赖如何引入?
★ 旧版本 0.8.2.2,客户端 Maven 依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.2.2</version>
</dependency>
我不知道你们是否有和我一样的疑惑————为什么出现了两个版本号?一个
2.9.2,一个0.8.2.2。其实这个2.9.2指的是 Scala 语言环境的版本号,而0.8.2.2才是 Kafka 的版本号。
我们可以通过 官网下载地址 查看:
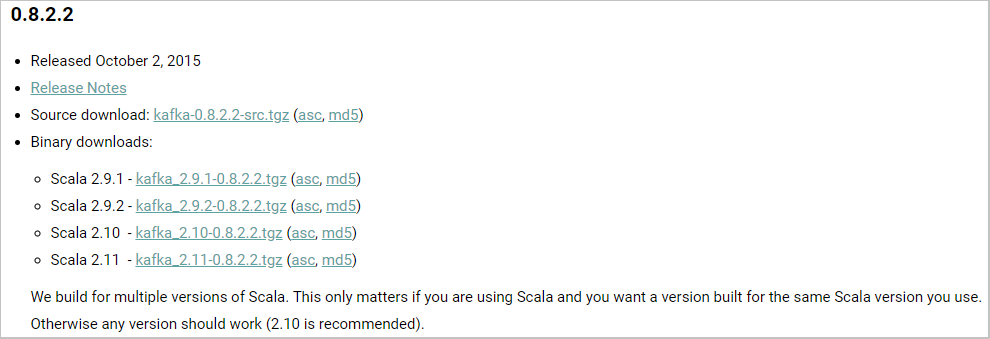
实际上,这里的
2.9.x,2.10和2.11是Scala 语言环境的版本————Kafka 最开始是使用Scala 语言编写的,就像普通的Java程序可以选择不同的Java版本编译一样。
★ 新版本 1.0.0,客户端 Maven 依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>1.0.0</version>
</dependency>
我们依然可以看一下官网的信息:
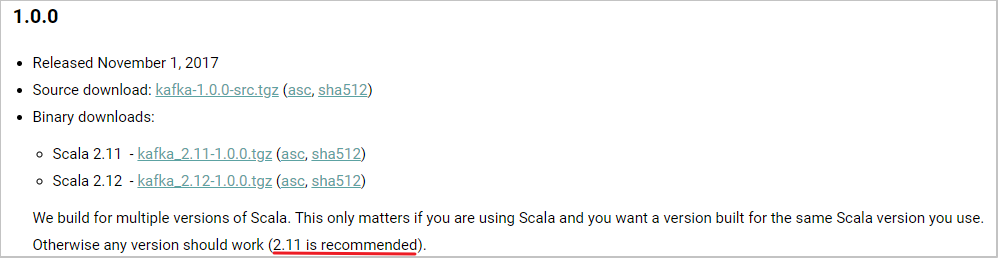
稍微提一下 kafka-clients 这个依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
这个其实不需要特别指定,因为 kafka_x.x.x 都会依赖相同版本号的 kafka-client,例如:
| kafka | kafka-client |
|---|---|
| 0.8.2.2 | 0.8.2.2 |
| 1.0.0 | 1.0.0 |
Kafka0.8.2.2客户端开发
在《Apache Kafka实战》这本书上,有比较详细的 Kafka1.0.0 的开发教学,但是这不是我要解决的问题的重点,本文主要还是解决线上 Kafka 0.8.2.2 版本的客户端问题。
所以我们聚焦 0.8.2.2 的客户端开发。
producer生产者
Kafka 0.8.2.2 版本已经推出了 Java 版本的 producer,因此主要使用类就是 org.apache.kafka.clients.producer.KafkaProducer。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* 功能描述:基于 Kafka 0.8.2.2 Java API 的消息发送者
*
* @author geekziyu
* @version 1.0.0
*/
public class Sender {
private static final Logger log = LoggerFactory.getLogger(Sender.class);
private String topic;
private KafkaProducer<String, String> producer;
public Sender(String topic) {
this.topic = topic;
this.producer = new KafkaProducer<>(createProducerConfig());
}
public Future<RecordMetadata> send(String message) {
return producer.send(createProducerRecord(message));
}
public void close() {
producer.close();
}
/**
* 创建一条Kafka消息记录
*
* @param message 消息内容
* @return Kafka消息记录
*/
private ProducerRecord<String, String> createProducerRecord(String message) {
return new ProducerRecord<>(this.topic, message);
}
/**
* 获取生产者配置
*
* @return 配置集合
*/
private Map<String, Object> createProducerConfig() {
Map<String, Object> result = new HashMap<>();
// 必填项,如果缺少会报错:Missing required configuration "bootstrap.servers" which has no default value.
result.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9091,kafka2:9092,kafka3:9093");
// 必填项,如果缺少会报错:Missing required configuration "key.serializer" which has no default value.
result.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 必填项,如果缺少会报错:Missing required configuration "value.serializer" which has no default value.
result.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
return result;
}
/**
* 使用示例
*
* @param args 运行参数
*/
public static void main(String[] args) {
Sender sender = new Sender("news");
List<Future<RecordMetadata>> futures = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Future<RecordMetadata> future = sender.send(String.valueOf(i));
futures.add(future);
}
sender.close();
futures.forEach(future -> {
try {
RecordMetadata recordMetadata = future.get();
log.info("Send message to [{},{}]", recordMetadata.topic(), recordMetadata.partition());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
log.info("Send message failed.", e);
}
});
}
}
KafkaProducer构造函数所需的参数 Map<String, Object>,键值key可以引用 ProducerConfig 中的静态常量。
| 必填配置 | 描述 |
|---|---|
bootstrap.servers |
代表的是 kafka 集群的地址,多个地址之间可以用逗号分隔; |
key.serializer |
键序列化配置,这里传入的是 StringSerializer 的全限定名; |
value.serializer |
值序列化配置,指定使用何种方式把消息内容编码成字节数组byte[] |
consumer消费者
下表是新旧版本 consumer 的对比:
| 编程语言 | API包名 | 主要使用类 | |
|---|---|---|---|
| 旧版本 | Scala | kafka.consumer.* |
ZookeeperConsumerConnector SimpleConsumer |
| 新版本 | Java | org.apache.kafka.clients.consumer.* |
KafkaConsumer |
我们现在用的是 Kafka 0.8.2.2 当然属于旧版本。在这个版本中,虽然已经有 KafkaConsumer 这个类,但是属于未完成品。比如,核心方法poll的实现居然是空的:
@Override
public Map<String, ConsumerRecords<K,V>> poll(long timeout) {
// TODO Auto-generated method stub
return null;
}
所以,只能老老实实地用 ConsumerConnector,但是同名类有两个:
kafka.javaapi.consumer.ConsumerConnector;kafka.consumer.ConsumerConnector;
两者的创建实例的方式略有不同:
前者,可以通过 kafka.consumer.Consumer.createJavaConsumerConnector(ConsumerConfig) 创建;
后者,则通过 kafka.consumer.Consumer.create(ConsumerConfig) 创建;
问题在于 createMessageStreams 方法:
kafka.javaapi.consumer.ConsumerConnector#createMessageStreams(scala.collection.Map)返回的是scala.collection.Map;kafka.consumer.ConsumerConnector#createMessageStreams(java.util.Map)返回的是java.util.Map;
所以,作为Java程序员应该选择 kafka.javaapi.consumer.ConsumerConnector,以下是消费者的代码:
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
import kafka.serializer.Decoder;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
/**
* 功能描述:基于 Kafka 0.8.2.2 的消息接收者
*
* @author geekziyu
* @version 1.0.0
*/
public class Receiver {
private static final Logger log = LoggerFactory.getLogger(Receiver.class);
private String topic;
private String groupId;
private ConsumerConnector consumer;
private Decoder<String> keyDecoder;
private Decoder<String> valueDecoder;
private Executor executor;
public Receiver(String topic, String groupId) {
this.topic = topic;
this.groupId = groupId;
this.consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
this.keyDecoder = new StringDecoder(new VerifiableProperties());
this.valueDecoder = new StringDecoder(new VerifiableProperties());
this.executor = Executors.newFixedThreadPool(2);
}
public void start() {
Map<String, List<KafkaStream<String, String>>> messageStreams = this.consumer.createMessageStreams(createTopicCountMap(), keyDecoder, valueDecoder);
// key 其实就是 topic
for (List<KafkaStream<String, String>> kafkaStreams : messageStreams.values()) {
for (KafkaStream<String, String> kafkaStream : kafkaStreams) {
executor.execute(() -> kafkaStream.forEach(this::printMessage));
}
}
}
public synchronized void printMessage(MessageAndMetadata<String, String> messageAndMetadata) {
String theme = messageAndMetadata.topic();
int partition = messageAndMetadata.partition();
String message = messageAndMetadata.message();
log.info("Receive message from [{},{}] : {}", theme, partition, message);
}
private Map<String, Integer> createTopicCountMap() {
Map<String, Integer> result = new HashMap<>();
result.put(topic, 2);
return result;
}
private ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
// 必填项,如果缺少会报错:Missing required property 'zookeeper.connect'
props.put("zookeeper.connect", "localhost:2181");
// 必填项,如果缺少会报错:Missing required property 'group.id'
props.put("group.id", groupId);
return new ConsumerConfig(props);
}
public static void main(String[] args) {
Receiver receiver = new Receiver("news", "staff");
receiver.start();
}
}
使用log4j打印日志
在 srcmain
esources 文件夹下的 log4j.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration SYSTEM "http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/xml/doc-files/log4j.dtd">
<log4j:configuration debug="true">
<!-- Appenders 日志信息输出目的地 -->
<!-- ConsoleAppender -->
<!-- 每个ConsoleAppender都有一个target,表示它的输出目的地。 -->
<!-- 它可以是System.out,标准输出设备(缓冲显示屏) -->
<!-- 或者是System.err,标准错误设备(不缓冲显示屏) -->
<appender name="console" class="org.apache.log4j.ConsoleAppender">
<param name="Target" value="System.out" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d %-5p [%t] %c - %m%n" />
</layout>
</appender>
<!-- 传说中的根logger -->
<!-- 输出级别是info级别及以上的日志,下面的ref关联的两个appender没有filter设置,所以,info及以上的日志都是会输出到这2个appender的 -->
<root>
<priority value="info" />
<appender-ref ref="console" />
</root>
</log4j:configuration>
问题再现
-
集群中有三台 Kafka 服务器
-
目标主题(比如本文中的
news)它的分区数是2,副本数也是2。

-
接着,我运行两个Receiver,再运行一次 Sender
我们发现,两个 Receiver 中只有一个 Receiver 接收到了信息,另一个没有接收到信息。 为什么呢?
猜测原因:分区策略
我关注到先启动的 Receiver 日志中包含:
2021-08-19 10:47:58,022 INFO [main] kafka.consumer.RangeAssignor - Consumer staff_win10-1629341277488-efccccb3 rebalancing the following partitions: ArrayBuffer(0, 1) for topic news with consumers: List(staff_win10-1629341277488-efccccb3-0, staff_win10-1629341277488-efccccb3-1)
2021-08-19 10:47:58,025 INFO [main] kafka.consumer.RangeAssignor - staff_win10-1629341277488-efccccb3-0 attempting to claim partition 0
2021-08-19 10:47:58,025 INFO [main] kafka.consumer.RangeAssignor - staff_win10-1629341277488-efccccb3-1 attempting to claim partition 1
后启动的 Receiver 日志对应的则是:
2021-08-19 10:57:02,096 INFO [main] kafka.consumer.RangeAssignor - Consumer staff_win10-1629341821418-e2f812b8 rebalancing the following partitions: ArrayBuffer(0, 1) for topic news with consumers: List(staff_win10-1629341277488-efccccb3-0, staff_win10-1629341277488-efccccb3-1, staff_win10-1629341821418-e2f812b8-0, staff_win10-1629341821418-e2f812b8-1)
2021-08-19 10:57:02,098 WARN [main] kafka.consumer.RangeAssignor - No broker partitions consumed by consumer thread staff_win10-1629341821418-e2f812b8-1 for topic news
2021-08-19 10:57:02,098 WARN [main] kafka.consumer.RangeAssignor - No broker partitions consumed by consumer thread staff_win10-1629341821418-e2f812b8-0 for topic news
要搞清楚生产者分区策略和消费者的分区策略。
★ 生产者分区策略:对于生产者而言,关键是把消息写入到哪一个分区上。
1、指明 partition 的情况下,直接将指明的值直接作为 partiton 值:
// 使用该构造函数,创建一个要发送到指定主题和分区的记录
public ProducerRecord(String topic, Integer partition, K key, V value) {
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null");
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
}
2、没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
public ProducerRecord(String topic, K key, V value) {
this(topic, null, key, value);
}
3、既没有 partition 值又没有 key 值的情况下,第一次调用时(第一条消息发往那个分区)随机生成一个整数( 后 面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
public ProducerRecord(String topic, V value) {
this(topic, null, value);
}
参考自 《Kafka 生产者分区策略》 链接,这个源码可以看到 ->
org.apache.kafka.clients.producer.internals.Partitioner
★ 消费者分区策略:topic-partition 如何安排给 消费者端-线程号?
比如我们的主题news有2个分区,因此可以用来分配的“资源”就是 news-0,news-1。竞争“资源”的是 [staff_win10-1629341277488-efccccb3-0, staff_win10-1629341277488-efccccb3-1, staff_win10-1629341821418-e2f812b8-0, staff_win10-1629341821418-e2f812b8-1]
按照 RangeAssigner 的分法:我们有2个分区,4个消费者线程 2除以4等于0余2,首先所有消费线程都分到0个,然后,前两个 staff_win10-1629341277488-efccccb3-0, staff_win10-1629341277488-efccccb3-1 各多分一个。
| 消费线程 | 消费分区 |
|---|---|
| staff_win10-1629341277488-efccccb3-0 | news-0 |
| staff_win10-1629341277488-efccccb3-1 | news-1 |
| staff_win10-1629341821418-e2f812b8-0 | 无 |
| staff_win10-1629341821418-e2f812b8-1 | 无 |
这就导致了,后启动的 Receiver 没有分到主题分区,自然就不会消费主题分区了。
参考自 《kafka的分区策略(partition assignment strategy)》 链接 的 Range(按范围) 部分。
0.8.2.2如何修改消费分区策略呢?
进行如下配置
props.put("partition.assignment.strategy", "roundrobin");
网上有用全限定名"org.apache.kafka.clients.consumer.RoundRobinAssignor"作为 value 的,但是那种方法,是针对 1.0.0 以后的 KafkaConsumer 的,对于 Kafka 0.8.2.2 的消费客户端是不生效的!
但是修改之后,还是没用。消费者RoundRobin策略:将所有主题的分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按照 hashCode 进行排序,将分区分别分配给不同的消费者线程。
参考自 《Kafka消费者组三种分区分配策略roundrobin,range,StickyAssignor》 链接
PS:Kafka 0.8.2.2 版本中只有 roundrobin 和 range 两种策略。源码中没有发现 StickyAssignor
“僧多粥少”如何破局?
我把消费者线程比作“僧”,把主题分区比作“粥”,现在不管采用 roundrobin 和 range,都不能解决这个问题?
能不能削减消费者线程的数量呢?我们把目光放到了 kafka.javaapi.consumer.ConsumerConnector#createMessageStreams 的第一个参数 topicCountMap 上!
/**
* Create a list of MessageStreams of type T for each topic.
*
* @param topicCountMap a map of (topic, #streams) pair
* @param keyDecoder a decoder that decodes the message key
* @param valueDecoder a decoder that decodes the message itself
* @return a map of (topic, list of KafkaStream) pairs.
* The number of items in the list is #streams. Each stream supports
* an iterator over message/metadata pairs.
*/
public <K,V> Map<String, List<KafkaStream<K,V>>>
createMessageStreams(Map<String, Integer> topicCountMap, Decoder<K> keyDecoder, Decoder<V> valueDecoder);
解决方案:topicCountMap
private Map<String, Integer> createTopicCountMap() {
Map<String, Integer> result = new HashMap<>();
// 由2改为1,这样启动两个消费客户端时,每个消费客户端启动一个消费线程,这样,每个消费客户端各自分到一个主题分区。
result.put(topic, 1);
return result;
}
topicCountMap
- 告诉Kafka我们在消费者客户端Consumer中将用多少个线程来消费该topic。
- topicCountMap的key是topic名称,value针对该topic是消费线程的数量。
参考自 《Kafka-topicCountMap》 链接
参考文档
Apache Kafka 0.8.2.x Consumer Config 官方文档链接
Kafka学习(三)-------- Kafka核心之Consumer 阅读
Kafka-topicCountMap 阅读 这篇又带出两篇
kafka的分区策略(partition assignment strategy) 阅读
从0开始学Kafka(下)阅读
【Kafka】kafka 重平衡(Rebalance) 阅读
Kafka 设计解析(四):Kafka Consumer 解析 阅读
kafka多线程消费topic的问题 阅读