1.什么是并查集?
当初第一次与ta邂逅,是在一次算法选修课上。ta只是用文本来做了简单的自我介绍,没有让我留下很深的印象,甚至都没有说自己在哪工作的,以使我已经很久都没能再与ta重逢。直至有一次在某篇博文上,以程序代码的形式出现让我看到了ta的真容,那时让我陷入ta的内在原理中研究了一番,最后通过与ta进行了一番深入交流,我自己重写了一遍ta的实现,以下是java语言版的代码实现形式:
public class UnionQuerySet {
private int[] c2p;
private int maxSize;
public UnionQuerySet(int maxSize) {
this.maxSize = maxSize;
int[] c2p = new int[maxSize];
for (int i = 0; i < c2p.length; i++) {
c2p[i] = i;
}
this.c2p = c2p;
}
public int find(int x) {
int p = x;
while (c2p[p] != p) {
p = c2p[p];
}
int c = x;
while (c != p) {
int i = this.c2p[c];
this.c2p[c] = p;
c = i;
}
return p;
}
public boolean union(int c1, int c2) {
int p1 = this.find(c1);
int p2 = this.find(c2);
if (p1 != p2) {
this.c2p[p1] = p2;
return true;
}
return false;
}
}
1.find方法(查询操作)
从代码不难看出它在干嘛:
1)第一,在找最顶端父节点(此处的最顶端父节点是满足(子节点,父节点)的映射c2p中c2p[i]=i的节点,即子节点本身的父节点就是它自己,这样的节点实际没有父节点,通过这样的标记区分出这些最顶端父节点而已);2)从当前节点出发,自底向上遍历经过的所有节点,把这些节点的父节点全置为最顶端父节点,这就是并查集的一大特性,叫路径压缩。通过路径压缩,使这种数据结构每次查询时就可以同时做结构调整,使树的层次在两层内收敛,大大缩短查询时间,提升查询效率。
2.union方法(合并操作)
1)分别查询待合并元素e1、e2的所在集合;
2)如果e1和e2所在集合不是同一个,做合并操作(把其中一个集合归并到另一集合中,成为一个大集合),返回true;否则,无需合并,返回false。
这就是并查集的两个核心操作,这也就诠释了名字的由来---支持高效合并和查询操作的集合。
二、并查集在哪工作?
说了那么多,ta又有什么用?坦白说,如果是在实际业务中使用场景很少。=>(全文终)
当然,ta虽然使用场景很少,但不可置否的是,ta设计和实现的巧妙之处很值得借鉴。另外,这次对ta的重温,正是因为遇上了ta的用武之处----在leetcode上的两道有趣的题。
话不多说,看题。
1. 冗余连接
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/redundant-connection
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
2.冗余连接II
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/redundant-connection-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
以上两道题,都可以通过并查集完成AC。不一样的是,相对于题1,题2难度可能更上一层(因人而异)。
题1要是没有联想到并查集的应用前,实际上很难想到如何在O(N)时间复杂度内找到题目要求的冗余边。有了并查集这样有趣的数据结构后,我们只需要依照题意,构造一个针对题中带了一条冗余边的树的节点的并查集,再按给出的边数组顺序遍历,在遍历过程中若发生遍历的当前边对应的两点在合并前已属于同一集合,说明之前已遍历的边构成的连通图中该两点已被连通,所以加上当前边后,就会形成环路,那当前边就必然是冗余边。具体代码如下:
public static int[] findRedundantConnection(int[][] edges) {
UnionQuerySet unionQuerySet = new UnionQuerySet(edges.length + 1);
int[] res = null;
for (int i = 0; i < edges.length; i++) {
int[] edge = edges[i];
if (unionQuerySet.union(edge[0], edge[1])) {
continue;
}
res = edge;
}
return res;
}
挺简洁的,时间和空间复杂度也还不错:
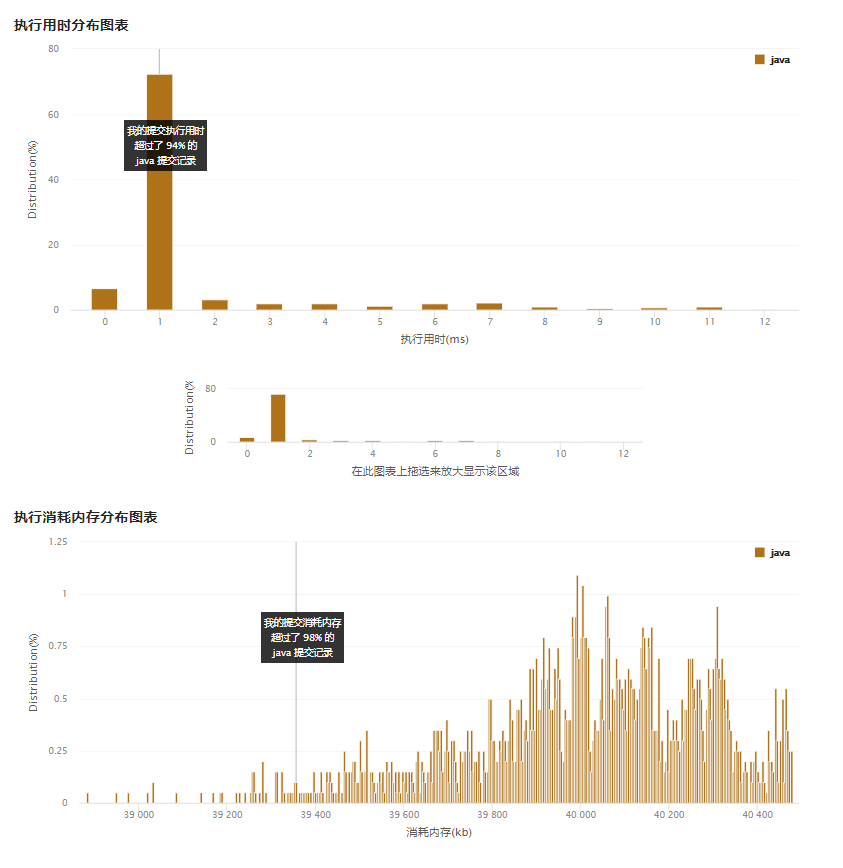
当然,这个得基于有意识使用并查集可以检查图的连通性的特性这个前提上,才知道该如何简单解决问题,说明去学习和掌握数据结构的运用,还是很重要且必要。如何掌握运用,无他,勤刷题。
题2要是在做完题1去做的,当时事实上误入思维误区好几次想放弃使用并查集另寻他法,但最后还是想到了办法去正确应用并查集。其实理解好题目就可以成功一半,只要区分清楚它跟题1的区别,很容易明白因为有向边的关系使冗余边多了另一种情况:两条有向边的儿子节点均为同一个节点,此时两边冲突,不可能在有向树中存在,所以必有一条边是冗余边,把环路边和冲突边分离清楚,环路边利用并查集去找到,冲突边再利用定义去找到(即找到拥有同一个儿子节点的两条有向边),此时取交集(或其中一种情况为无,根据题目显然环路边必然存在,冲突边是决定冗余边是环路中哪一条边而已)得到最终符合题意的冗余边。在此感谢leetcode题解(https://leetcode-cn.com/problems/redundant-connection-ii/solution/685-rong-yu-lian-jie-iibing-cha-ji-de-ying-yong-xi/)发挥的作用:让我明白,跟模拟删除冗余边同理,只要我找到正确的侯选边,再取交集即可。具体代码如下:
public static int[] findRedundantDirectedConnection(int[][] edges) {
if (null == edges || edges.length == 0) {
return null;
}
int n = edges.length + 1;
boolean[] nodes = new boolean[n];
int multiSon = -1;
for (int i = 0; i < edges.length; i++) {
if (nodes[edges[i][1]]) {
multiSon = edges[i][1];
break;
}
nodes[edges[i][1]] = true;
}
UnionQuerySet unionQuerySet = new UnionQuerySet(n);
int[][] conflictEdges = new int[2][];
int rp = 0;
for (int i = 0; i < edges.length; i++) {
if (edges[i][1] == multiSon) {
conflictEdges[rp ++] = edges[i];
continue;
}
if (!unionQuerySet.union(edges[i][1], edges[i][0])) {
return edges[i];
}
}
if (!unionQuerySet.union(conflictEdges[0][1], conflictEdges[0][0])) {
return conflictEdges[0];
}
if (!unionQuerySet.union(conflictEdges[1][1], conflictEdges[1][0])) {
return conflictEdges[1];
}
return null;
}
时间和空间复杂度如下:
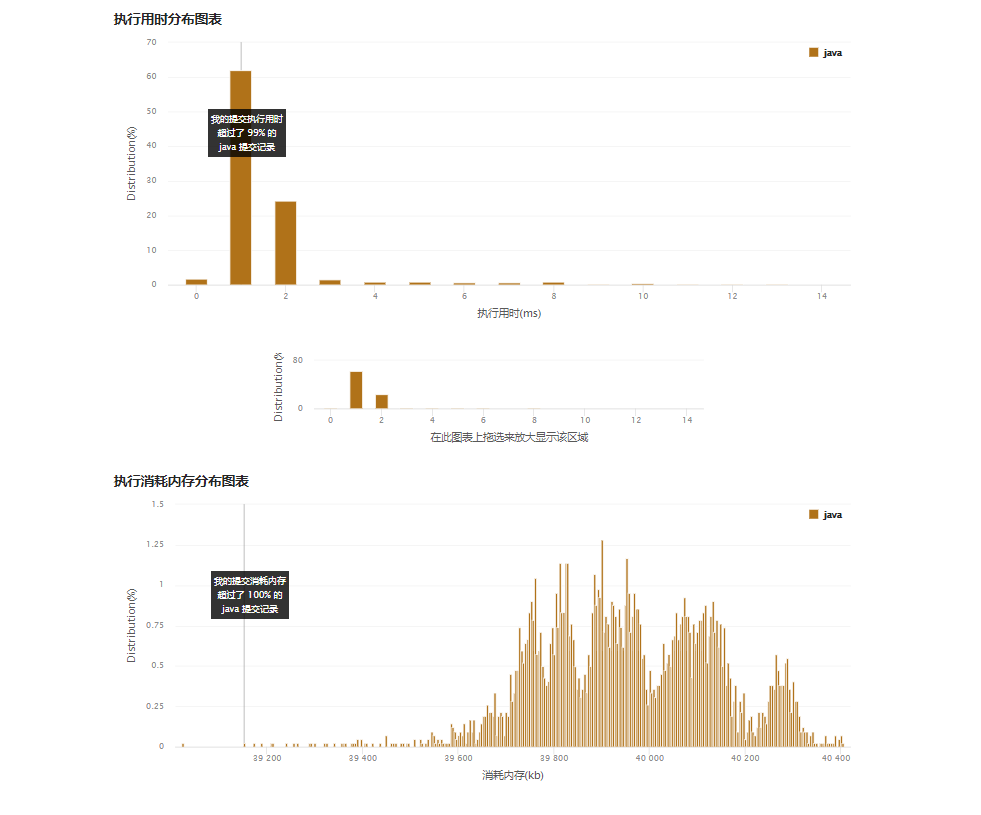
三、复盘:
1.因为热爱,所以坚持。加油做自己爱做的事,虽然过程很煎熬,但通过学习,获取到新的知识和技巧,能解决问题,感觉生活就是这样,不断在面对问题解决问题。
2.或许一时半刻,你会忘了老朋友,但ta们早晚会找上门来,庆幸并查集还记得我。
3.不要因为要应用而应用,要笃定一个方向:解决问题。把解决问题的思路捋清,该不该用数据结构就很显然易见了。
4.此外,并查集本质上的定义是能够快速合并和查询的集合,所以不单单只有验证图中节点的连通性这一功能,还有很多其他待发掘的用途,衷心希望以后还会和ta有来往,这不是寒暄。
5.预告下一篇:继续认识新朋友。