本周.NET生态圈内的更新源源不断,除了.NET Core 2.2,ASP.NET Core 2.2和Entity Framework Core 2.2之外,ML.NET 0.8也一并登上舞台。
新的推荐场景
ML.NET使用基于矩阵分解(Matrix Factorization)和场感知分解机(Field-aware Factorization Machine)的方法来作推荐。一般而言,场感知分解机是矩阵分解更通用的例子,它允许传入额外的元数据。
在ML.NET 0.8中新加了运用矩阵分解的推荐场景。
| 推荐场景 | 推荐方案 | 示例链接 |
|---|---|---|
| 基于产品Id,评价,用户Id和诸如产品描述,用户特征(年龄,国家)的额外元数据的产品推荐 | 场感知分解机 | ML.NET 0.3 |
| 基于产品Id,评价,用户Id的产品推荐 | 矩阵分解 | ML.NET 0.7 |
| 基于产品Id和与其一同购买的产品Id的产品推荐 | One Class矩阵分解 | ML.NET 0.8 |
在新的推荐场景中,即使没有可用的评价,也可以通过历史购买数据为用户构建"经常一起购买的产品"(Frequently Bought Together)的列表。
通过预览数据改进调试功能
在多数例子里,当开始运行你的机器学习管道(pipeline),且加载数据时,能看到已经载入的数据是很有用的功能。尤其是在某些中间转换过程之后,需要确保数据如预期的一样发生变化。
现在当你想要预览DataView的数据模式(Schema)时,可以悬停鼠标在IDataView对象上,展开它,观察它的数据模式属性。
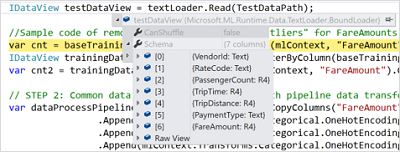
而要查看DataView中已加载的实际数据,通过以下三步可以达成目标。
- 在调试模式中打开观察窗口
- 输入DataView对象的变量名,调用它的Preview方法
- 点开想看的某行,这样就能显示其中实际加载的数据
默认情况下,只会显示100行的数据,但可以在Preview方法里传入参数,比如Preview(500),以获得更多的数据。
模型可解释性
为了让模型更具可解释性,ML.NET 0.8引入了新的API,用以帮助理解模型的特征重要性(整体特征重要度(Overall Feature Importance))以及创建能被其他人解释的高效模型(广义加性模型(Generalized Additive Models))。
整体特征重要度用于评判在模型中哪些特性是整体上最重要的。它帮助理解哪些特征是最有价值的,从而得到更好的预测结果。例如,当预测汽车价格时,一些特性比如里程数和生产商品牌是更重要的,而其它特性,如汽车颜色,则是影响甚小。
模型的整体特征重要度可以通过"排列特征重要度"(Permutation Feature Importance)(PFI)技术来获得。PFI借由"如果特征值设为随机数,会怎样影响模型"这一问题以测量特征重要度。
PFI方法的好处是其与模型无关,任何模型都可以用它作评估,并且它还可以使用任意数据。
使用PFI的方法如下例代码所示:
// Compute the feature importance using PFI
var permutationMetrics = mlContext.Regression.PermutationFeatureImportance(model, data);
// Get the feature names from the training set
var featureNames = data.Schema.GetColumns()
.Select(tuple => tuple.column.Name) // Get the column names
.Where(name => name != labelName) // Drop the Label
.ToArray();
// Write out the feature names and their importance to the model's R-squared value
for (int i = 0; i < featureNames.Length; i++)
Console.WriteLine($"{featureNames[i]} {permutationMetrics[i].rSquared:G4}");
生成的结果包括了特征名与它的重要度。
Console output:
Feature Model Weight Change in R - Squared
--------------------------------------------------------
RoomsPerDwelling 50.80 -0.3695
EmploymentDistance -17.79 -0.2238
TeacherRatio -19.83 -0.1228
TaxRate -8.60 -0.1042
NitricOxides -15.95 -0.1025
HighwayDistance 5.37 -0.09345
CrimesPerCapita -15.05 -0.05797
PercentPre40s -4.64 -0.0385
PercentResidental 3.98 -0.02184
CharlesRiver 3.38 -0.01487
PercentNonRetail -1.94 -0.007231
广义加性模型拥有很好的预测可解释性。在便于理解上,它类似于线性模型,但更加灵活,并具有更佳的性能以及利于分析的可视化能力。
更多的API增强
在DataView中过滤行
有时你会需要对数据集过滤一部分数据,比如那些离群值(outlier)。ML.NET 0.8中新加入了FilterByColumn()API可以帮助解决类似问题。
使用方法如下面的代码所示:
IDataView trainingDataView = mlContext.Data.FilterByColumn(baseTrainingDataView, "FareAmount", lowerBound: 1, upperBound: 150);
缓存功能的API
当对同一数据作多次迭代处理时,通过缓存数据可以大幅减少训练时间。
以下例子可以减少50%的训练时间:
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("Area", "Label")
.Append(mlContext.Transforms.Text.FeaturizeText("Title", "TitleFeaturized"))
.Append(mlContext.Transforms.Text.FeaturizeText("Description", "DescriptionFeaturized"))
.Append(mlContext.Transforms.Concatenate("Features", "TitleFeaturized", "DescriptionFeaturized"))
//Example Caching the DataView
.AppendCacheCheckpoint(mlContext)
.Append(mlContext.BinaryClassification.Trainers.AveragedPerceptron(DefaultColumnNames.Label,
DefaultColumnNames.Features,
numIterations: 10));
以IDataView二进制格式保存读取数据
将经过转换的数据保存为IDataView二进制格式相较普通的文本格式,可以极大地提升效率。同时,由于此格式保留了数据模式,所以可以方便读取而不需要再指定列类型。
读取与保存的API如下所示,十分简单:
mlContext.Data.ReadFromBinary("pathToFile");
mlContext.Data.SaveAsBinary("pathToFile");
用于时间序列问题的状态性预测引擎
ML.NET 0.7里可以基于时间序列处理异常检查问题。然而,其预测引擎是无状态的,这意味着每次要指出最新的数据点是否是异常的,需要同时提供历史数据。
新的引擎中可以保留时间序列的状态,所以现在只要有最新的数据点,即可以进行预测。需要改动的地方是将CreatePredictionFunction()方法替换成CreateTimeSeriesPredictionFunction()。