Spark依赖于一个很特别的数据抽象,叫做弹性分布式数据集(resilient distributed datasets),也就是RDD,它是一个被集群分区(partitioned)的in-memory read-only对象。每一个RDD都是根据range(partitioning of consecutive records),或者是每条记录的key的hash值来进行分区。当然这两种不同的分区方法在特定的use case上有它自己的优点。例如利用hash值来分区,当不同的dataset共享一个key的时候,它能够通过这些record的局部性(locality),来提高join的效率。而采用range的方法,能够加快访问一小段经过过滤的数据。
尽管RDD并通过物理空间来存储数据,但是RDD依旧能够做到fault-tolerant。在这个过程中,它们并不需要复制或者保留备份数据,它们拥有一个”血统“(lineage)的概念,能够记住一些列建造这些RDD的指令,从而当数据丢失的时候,可以通过这些指令重新建造一份。
对于Spark来说,所有的工作只分为三种:建造新的RDD,转换(transformation)已存在的RDD和在RDD上运行各种指令。有一点需要声明的是,RDD采用的是lazily computed and ephemeral。所谓lazily computed,就是所有的transformation操作要到第一个action被用到的时候,它们才会开始执行。所谓Emphermal,就是当RDDs被某个应用程序用到的时候,可能会加载到内存里,并且在内存里进行计算,但随后它们就会从内存里被抹掉。
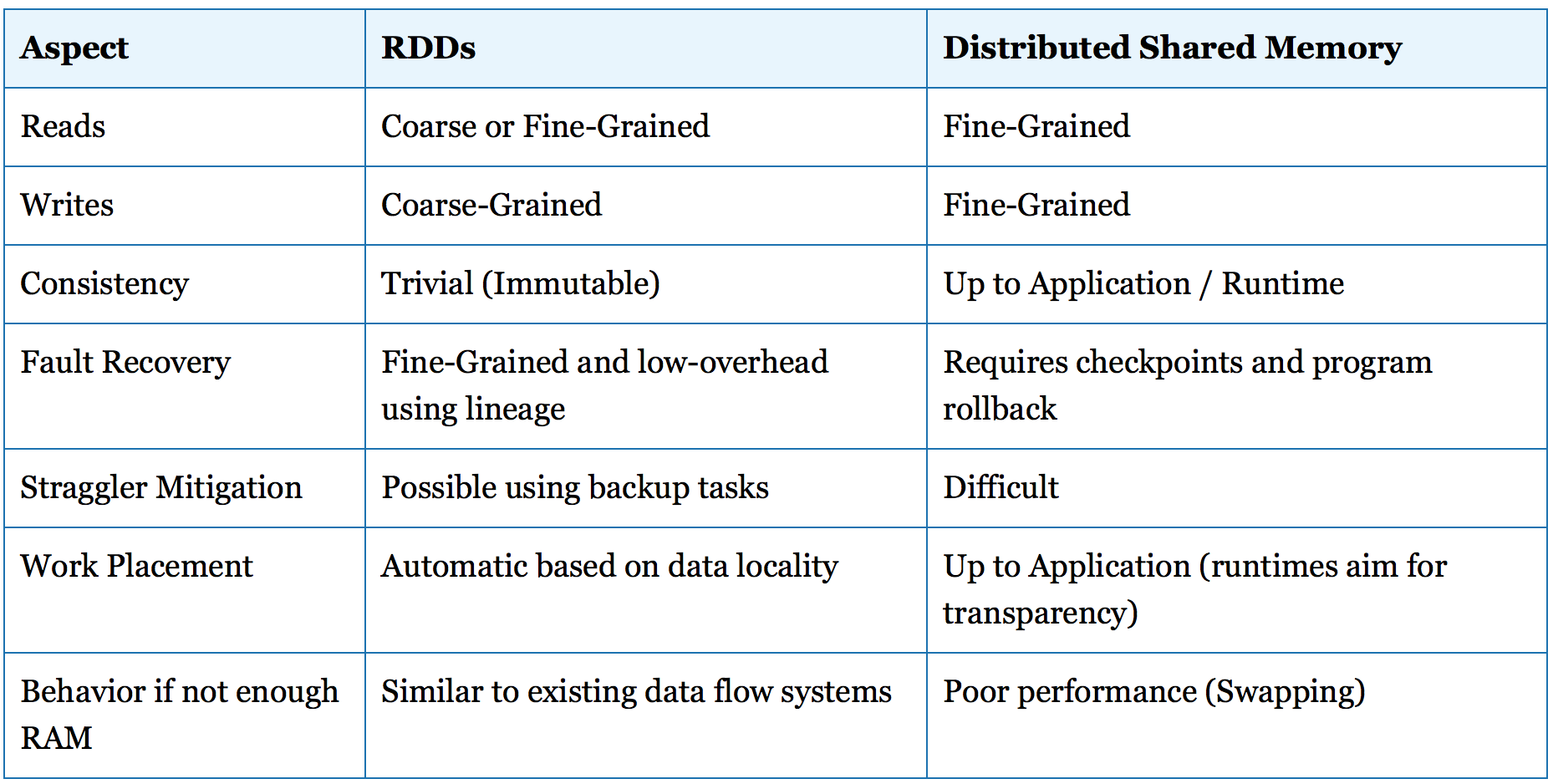
图 1 RDD和DSM的比较
RDD抽象是一种分布式共享收集系统(distributed shared collection system),它和传统的分布式共享内存系统 (Distributed Shared Memory systems, DSM)很像,所以我觉得可以把两者进行比较一番,可以看出个中的区别。
下面我来讲一下RDD的生命周期。
- Creating RDDs
在Spark的程序里,一个RDD默认为一个Scala的对象,虽然它也可以是Java或者是Python的对象。它通过以下几种方式被建造:
- 从分布式系统(如HDFS)的文件里
- 通过并行化(parallelizing)一个集合(collection或者array)并分配到许多节点上
- 通过转换(transforming)一个已经存在的RDD(后面有详细说明)
- 通过改变一个已经存在的RDD的persistence level,它有以下两种action:
-
- cache:它能够让RDD在第一次运行后依旧保存在内存里,以备将来再次调用
- save:把数据写到分布式系统上,如HDFS。
下面是以下create新的RDD的例子(本文采用Scala,它能够直接在Spark Scala Shell上运行):
-
- 通过textFile()方法把加载一个文本文档”server.logs“到RDD上:
>>> log_lines_RDD = sc.textFile("server.logs")
-
- 并行化一个已经存在的RDD:
>>> greeting_lines_RDD = sc.parallelize(["hello", "world"])
- RDD上的指令
RDD一旦被建立起来,它支持两种不同的指令:
- Transformations:从已存在的RDD里重新create一个新的RDD的指令
- Actions:在RDD上计算并且返回一个对象给driver。
正如之前所说,Transformations是lazy的,他们并不会马上被计算,他们成批的存储起来,直到一个Action被执行的时候他们才会被执行(如图2)。一个action的执行使得所有lineage上的RDD被“物化”,存到内存里。当然,一旦计算结束,一个RDD只有在显式指令下才能够继续保持,不然就会从内存中被抹掉。
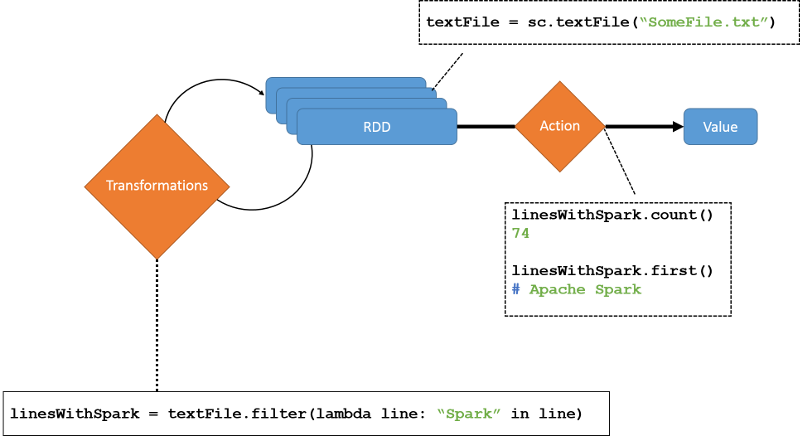
下面是一些常见的transformation和actions:
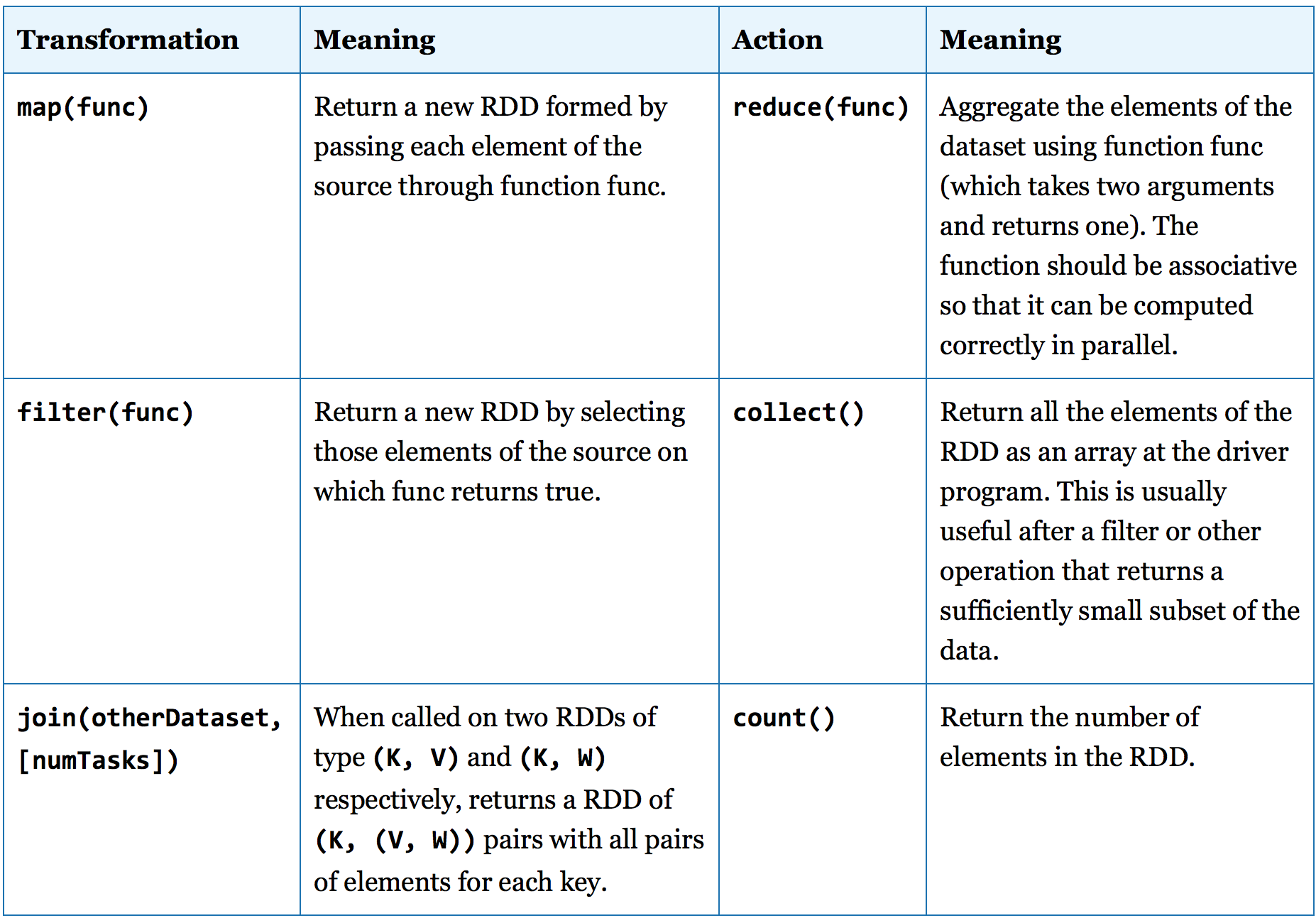
下面再举一些简单的例子,希望能让读者对RDD的指令有更为深刻的理解:
Transformations:
>>> log_lines_RDD = sc.textFile("server.logs")
>>> xss_RDD = log_lines_RDD.filter(lambda x: "%3C%73%63%72%69%70%74%3E" in x)
>>> sqli_RDD = log_lines_RDD.filter(lambda x: "bobby_tables" in x)
>>> owasp_attacks_RDD = xss_RDD.union(sqli_RDD)
上述代码是用来过滤log_lines_RDD,通过对某个关键字段的逐行搜索,找到web server被攻击的记录。
filter()并不会修改原来的RDD,相反,上例中它建立了两个新的RDD,而原来的log_lines_RDD仍然可以在以后被使用上。union()也是一个transformation,把两个RDD合并起来并且生成一个新的owasp_attacks_RDD。
Actions:
>>> log_lines_RDD = sc.textFile("server.logs")
>>> xss_RDD = log_lines_RDD.filter(lambda x: "%3C%73%63%72%69%70%74%3E" in x)
>>> sqli_RDD = log_lines_RDD.filter(lambda x: "bobby_tables" in x)
>>> owasp_attacks_RDD = xss_RDD.union(sqli_RDD)
上述代码是用来计算owasp_attacks_RDD中web server被攻击的总数。一个action会导致所有batched的RDD被materialization(存储到内存中)。
由此可以看出,RDD非常适合批量指令(batch operations),尤其是当这些指令可以同时被应用到数据集的所有元素上。因为他们是免疫的(immutable),因而为每一个额外的输入计算一个新的RDD的开销是十分巨大的。所以,当处理real-time数据输入的时候,Spark经常在短时间内批量(batch)所有的变化,而并不马上执行它们。
Persisting RDDs
一般来说有四种方法可以维持RDDs:
- 作为反序列化后的对象存在于内存里;
- 作为序列化的数据存在于内存里;
- 硬盘存储;
- 离堆存储(off-heap storage)。