1.前言
各位网上冲浪时是否遇到烦人的验证码?抑或无法复制的文字?
小编为大家推荐一款专为麻瓜设计的OCR识别模块:https://pypi.org/project/muggle-ocr
在2020不平凡的一年,6月1日,在pypi仓库中偷偷潜入一位新同学,他就是MuggleOCR,他有多厉害呢?
作为一个本地识别的模块,他的体积居然小于10MB,模型分别有两个,安装后可以在 site-packages/muggle_ocr 路径里看到

OCR模型仅为4MB,验证码模型仅为2MB,如此小的模型,识别效果是否能有惊喜呢?
2.测评
小编做了一份测试:
import time
import muggle_ocr
import os
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
root_dir = r"./imgs"
for i in os.listdir(root_dir):
n = os.path.join(root_dir, i)
with open(n, "rb") as f:
b = f.read()
st = time.time()
text = sdk.predict(image_bytes=b)
print(i, text, time.time() - st)
笔者在网上找了几张验证码图片一探究竟:

输出结果:
MuggleOCR Session [captcha] Loaded.
1a2v1_444cbc94c5a3bf1682ab71cc1e5319c0.jpg 1a2v1 0.009941816329956055
1a2yc_1534434561732.jpg 1a2yc 0.009974956512451172
2a3ka_1d94eaff16ab6612fc6445c6b5d56684.jpg 2a3ka 0.009972333908081055
2a3w_900a9e3672ded254e63ef4cba6e1f465.jpg 2a3w 0.009982109069824219
dU5g_c406889e89ca47e5a2d632798baead21.jpg du5g 0.010939359664916992
LGKX_85bbfbe824074944bd4529b61f8ccb75.png lgkx 0.011968135833740234
mhhm_3085e25cd1ee6b062d02522bb1133257.bmp mhhm 0.011968612670898438
Q8U7_4fab05a68b694d54842e1165d0539ce4.jpg q8u7 0.011966943740844727
居然都识别出来了!而且在速度上也是极快,0.01s是什么概念,10ms,市面上售卖的验证码识别大多也要40ms-100ms以上。
那么小编再带大家测评一下OCR识别的性能。
识别结果:
写到这里小编只能说“tql,oh my god”。这是什么神仙工具,用它用它用它。
3.如何使用
以下内容摘取至官方文档:
首先安装模块 pip install muggle_ocr
调用示例:
import time
# 导入包
import muggle_ocr
# 初始化;model_type 包含了 ModelType.OCR/ModelType.Captcha 两种
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
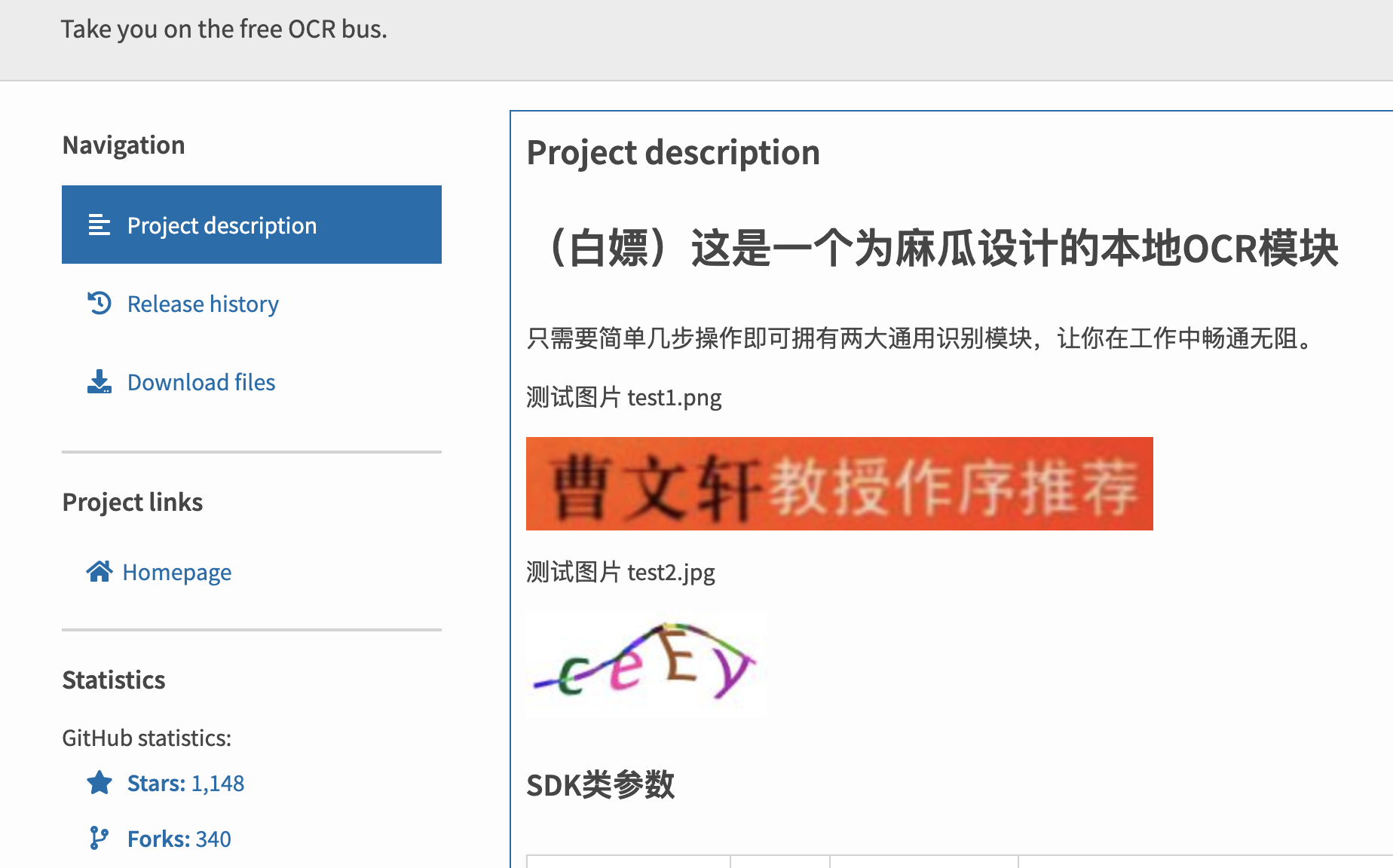
# ModelType.Captcha 可识别光学印刷文本
with open(r"test1.png", "rb") as f:
b = f.read()
for i in range(5):
st = time.time()
text = sdk.predict(image_bytes=b)
print(text, time.time() - st)
# ModelType.Captcha 可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
with open(r"test2.jpg", "rb") as f:
b = f.read()
for i in range(5):
st = time.time()
text = sdk.predict(image_bytes=b)
print(text, time.time() - st)
使用竟如此简单!
此外追踪作者github可见:
这套模型竟然是基于 https://github.com/kerlomz/captcha_trainer 训练的,对工具核心感兴趣的可以自行了解,小编这里就不多做介绍了。