1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). 自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
4). 鸢尾花完整数据做聚类并用散点图显示.
5). 想想k均值算法中以用来做什么?
解:
1) 扑克牌演练k均值聚类过程
一共40张扑克牌,随机选取3张作为一开始的中心点:
第一轮聚类中心:1、2、3

第二轮聚类中心:1、2、7

第三轮聚类中心:1、3、8

2) 自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。
之前老师讲的做法,存在不足:
from sklearn.datasets import load_iris import numpy as np # 1.数据准备 iris=load_iris() data=iris['data'] m=data.shape[1] #样本的属性个数 n=len(data) #样本的个数 k=3 #类中心个数,即最终分类的类别数 # 2.数据初始话 dist=np.zeros([n,k+1]) #距离矩阵 center=np.zeros([k,m]) #初始类中心 new_center=np.zeros([k,m]) #新的类中心 # 选中心 center=data[:k,:] #选前3个样本作为初始类中心 number=0 # 求距离 while True: for i in range(n): for j in range(k): dist[i,j]=np.sqrt(sum((data[i,:]-center[j,:])**2)) # 归类 dist[i,k]=np.argmin(dist[i,:k]) #新的类中心 for i in range(k): index=dist[:,k]==i new_center[i,:]=np.mean(data[index,:]) # 判定结束 if (np.all(center==new_center)): break else: center=new_center number = number + 1 print('聚类分析迭代次数:',number) print('最终聚类结果:',dist[:,k])

3)用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签 iris = load_iris() X = iris.data[:,1] Y = X.reshape(-1,1) km=KMeans(n_clusters=3) km.fit(Y) km_Y=km.predict(Y) plt.scatter(Y[:,0],Y[:,0],c=km_Y,s=50,cmap='coolwarm') plt.title("sklearn.cluster.KMeans鸢尾花花瓣长度的散点图") plt.show()
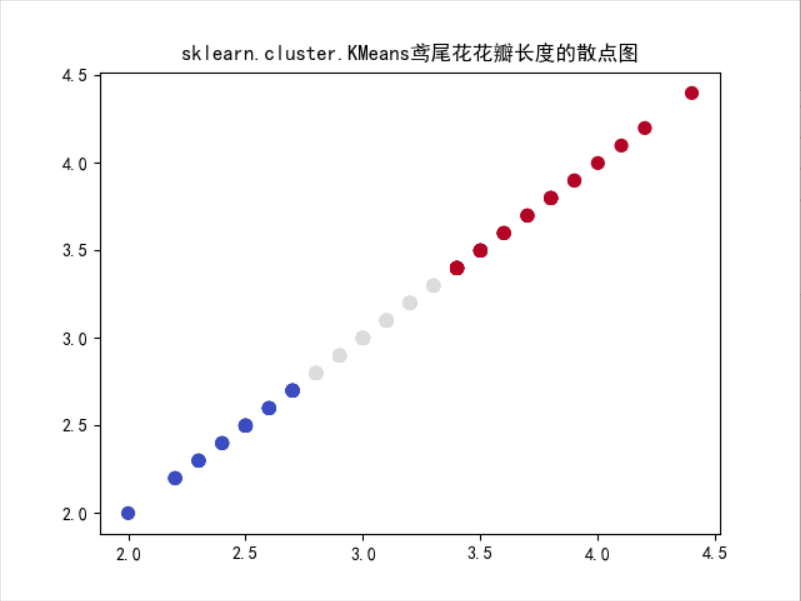
4)鸢尾花完整数据做聚类并用散点图显示
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签 iris = load_iris() X = iris.data km=KMeans(n_clusters=3) km.fit(X) km_Y=km.predict(X) plt.scatter(X[:,2],X[:,3],c=km_Y,s=50,cmap='coolwarm') plt.title("鸢尾花完整数据做聚类的散点图") plt.show()
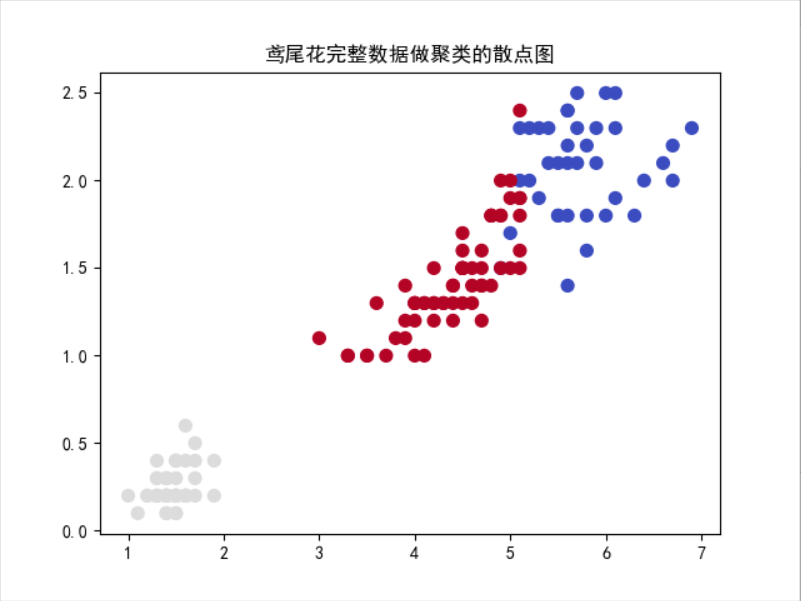
5)想想k均值算法中以用来做什么
比如检测犯罪的地点、客户类型分类、汽车数据分析等等可以分析近似的数据。