很喜欢notepad++, 简单而强大
今天想利用他来正则抽取所有sql语句中的表名,SQL语句如下,以供广大人民使用
getEntityData.sql=select s.analysis_group_id,s.period_id,s.period_value_id,s.fiscal_year_nbr,s.period_start_dt,s.period_end_dt,o.CURRENCY_ID from dbo.statement s,dbo.organization o where s.statement_id= @statementId and o.ORGANIZATION_ID=s.ANALYSIS_GROUP_ID union select s1.analysis_group_id,s1.period_id,s1.period_value_id,s1.fiscal_year_nbr,s1.period_start_dt,s1.period_end_dt,o1.CURRENCY_ID from dbo.statement s1,dbo.organization o1 where s1.statement_id=@statementId and o1.ORGANIZATION_ID=s1.ANALYSIS_GROUP_ID
getGLwithVequation.sql=select distinct h.account_id ,e.expression_txt,a.account_ds,e.business_txt,e1.expression_txt from dbo.FINANCIAL_ACCOUNT_HIERARCHY h,dbo.FINANCIAL_ACCOUNT a,dbo.FINANCIAL_ACCOUNT_CONDITION c, dbo.EXPRESSION e,dbo.EXPRESSION_SCOPE es,dbo.EXPRESSION e1 where a.active_ind=’Y’ and h.account_relationship_type_id=1 and h.account_id=a.account_id and c.account_id=h.account_id and c.evaluation_expression_id=e.expression_id and e.expression_scope_id=es.expression_scope_id and es.expression_cd=’VALIDATION’ and c.validation_expression_id=e1.expression_id and e.expression_id < 20000
思路: 尝试把匹配的表名放置到每一行,并且给表名前后加一个特别的标记, 然后利用Mark功能去掉unMarked的行,最后通过TextFX插件去掉重复的行
1. 将正则匹配的字符串替换变成行
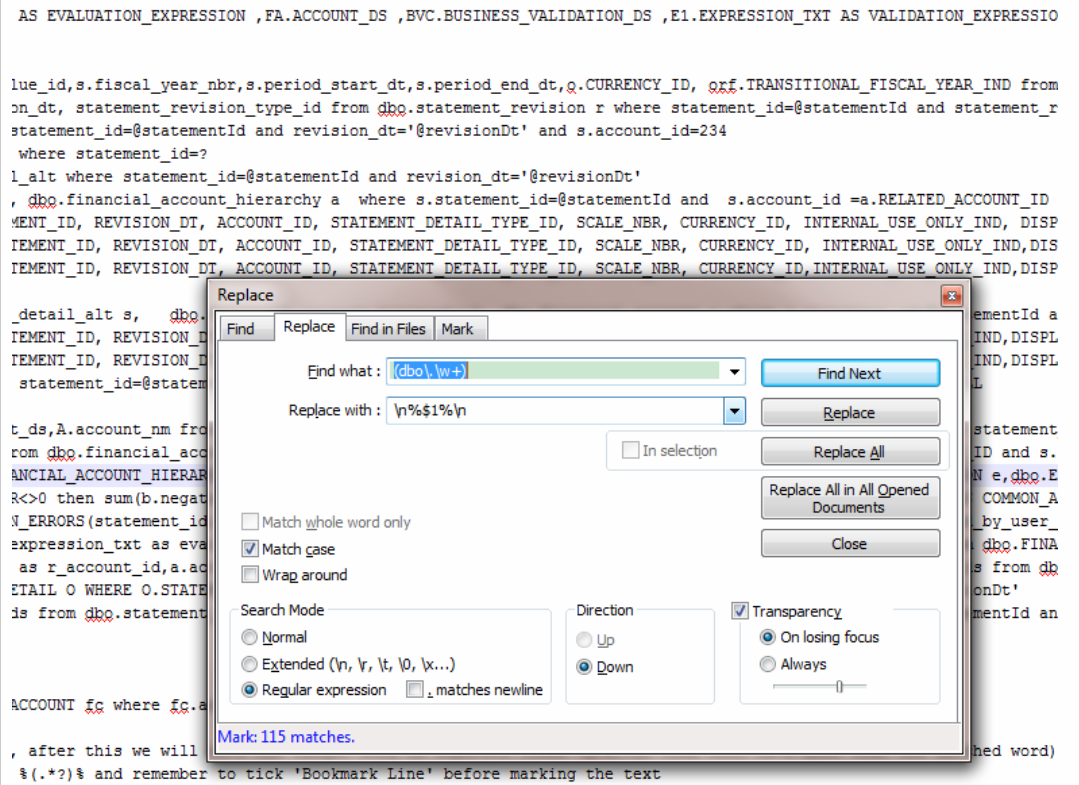
2.Mark,注意要勾选 Bookmark line.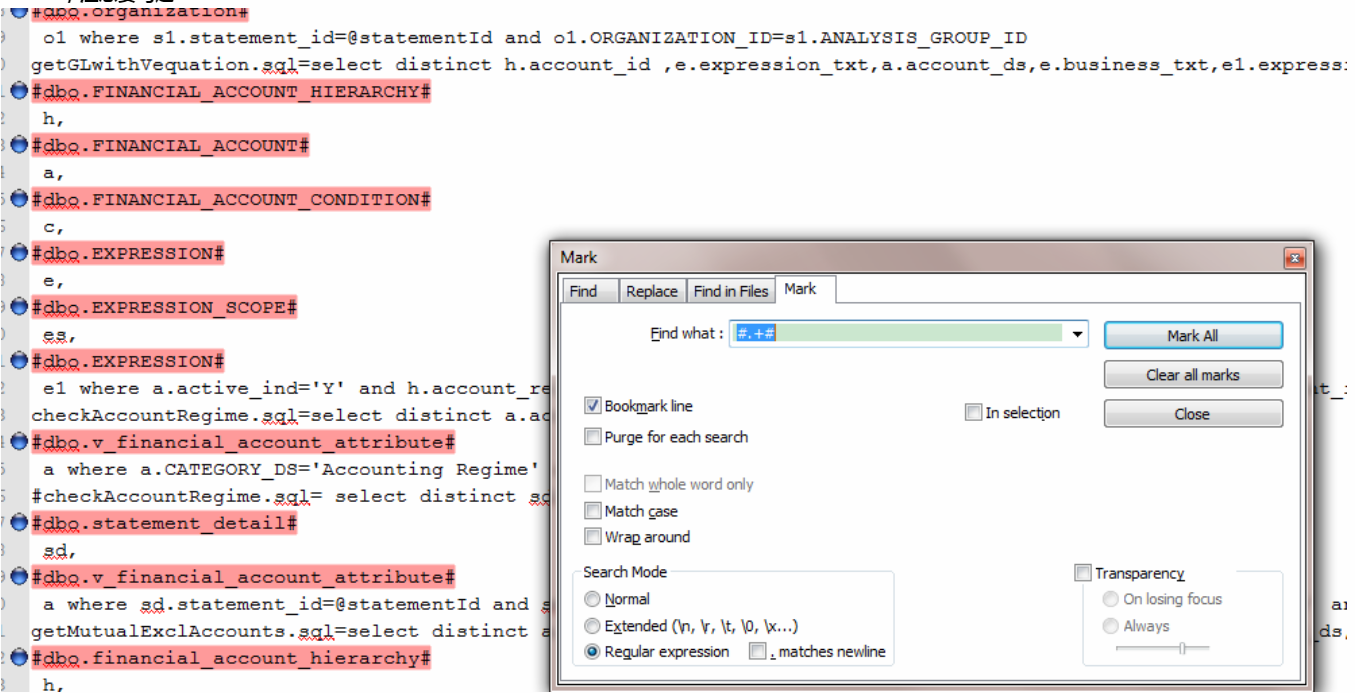
3,Search->Bookmark->Remove Unmarked Lines 去掉unmarked的行

4. 安装TextFX插件, 然后TextFX->TextFX Tools->Sort lines case insensitive 。注意要勾选Sort output only UNIQUE lines.

到此就可以提取到了所有正则匹配的数据。