sed是一个流编辑器(stream editor),一个非交互式的行编辑器。它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕;接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。在日常的运维工程中,会时常用sed命令来处理行操作,下面根据工作中的使用经验对sed的用法做一梳理:
sed(stream editor)特征:
1)流线型,非交互式的编辑器。它每次只处理一行文件并把输出打印到屏幕上。
2)模式空间(Pattern space)即存放当前正在处理的行的缓存空间。 一旦处理工作完成,sed就会把结果输出到屏幕,然后清空模式空间并把下一行读入模式空间,进行相关处理;直到最后一行。
3)sed是无破坏性的,它可以不更改原文件,除非使用重定向保存输出结果或者使用特定生效参数(比如-i)。
4)对于一行文本,sed命令是依次执行的,如果有多个命令的话。这时,要注意各命令之间可能产生的相互影响。
5)对于多个sed命令,我们可以用“{}”把它们括起来。但要注意,右花括号一定要单独成行。
6)可以把一系列的sed命令写入文件中并用sed的-f选项调用
sed的语法及寻址方式:
语法:
sed [options] 'command' filename(s)
寻址方式:
1)单行寻址:[line-address]command;寻找匹配line-address的行并进行处理。
2)行集合寻址:[regexp]command ;匹配文件中的一行或多行,如/^A/command匹配所有以A开头的行。
3)多行寻址: [line-address1,line-address2] command;寻找在两个地址之间的内容并做相应的处理。
4)嵌套寻址:10,20{
/^$/d
#上面三种寻址方法都可以应用在这里
}
sed选项

sed的相关命令:
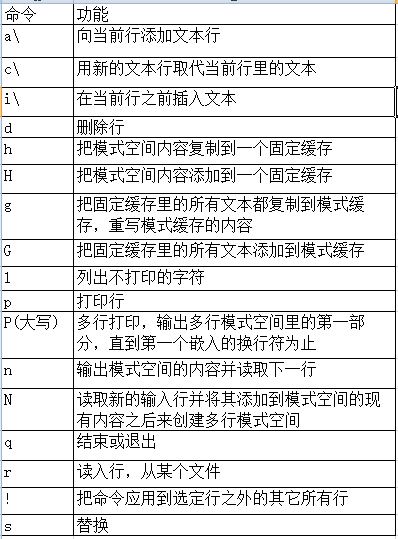
替换标志:

sed支持的一些元字符:

----------------------------------------------------------------------------------------------------------------------------
sed -n 'ap' filename 打印第a行
sed -n 'a,mp' filename 打印第a到m行
sed -n 'ap;mp' filename 打印第a行和第m行
sed -n '/wang/p' filename 打印包含wang字符的行
sed -n '3,$p' filename 打印第3到最后一行
sed -i 'nd' filename 删除第n行
sed -i 'n,md' filename 删除第n到m行
sed -i 'nd;md' filename 删除第n行和第m行
sed -i '/wang/d' filename 删除包含wang字符的行
sed -i '3,$d' filename 删除第3到最后一行
sed -i 's/a/b/g' filename 将a替换成b,全文替换
sed -i 'ns/a/b/g' filename 将第行中的a替换成b
sed -i 'n,ms/a/b/g' filename 将第n到m行中的a替换成b
sed -i 'ns;ms/a/b/g' filename 将第n行和第m行中的a替换成b
sed -i '3,$s/a/b/g' filename 将第3到最后一行中的a替换成b
sed -i '/wang/s/a/b/g' filename 将包含wang字符的行中的a替换成b
sed的替换命令格式有三种:
1)s/A/B/g
2) s#A#B#g
3) s_A_B_g
g表示全局替换
例如:
将php.ini文件中的/Data/app/php5.5.1/lib/php/extensions/no-debug-non-zts-20121212/替换成/Data/app/php5.6.26/lib/php/extensions/no-debug-non-zts-20131226/
# sed -i 's#/Data/app/php5.5.1/lib/php/extensions/no-debug-non-zts-20121212/#/Data/app/php5.6.26/lib/php/extensions/no-debug-non-zts-20131226/#g' php.ini
----------------------------------------------------------------------------------------------------------------------------
sed常用到的几个选项与参数解释:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;(加多个-e,表示可以多点编辑)
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。(这个很关键!)
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行);
c :取代, c 的后面可以接字串,这些字串可以取代 多行 之间的内容;
d :删除,因为是删除啊,所以 d 后面通常不接任何内容;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行;
s :取代,可以直接进行取代的工作。通常这个 s 的动作可以搭配正规表示法;例如 sed -i '1,20s/old/new/g' filename 将第1行到20行的old替换为new
要注意的是,sed 后面接的动作,最好以''单引号括住。当然用""双引号也可以。
如果使用单引号,那么就没办法通过’这样来转义,就有双引号就可以了,在双引号内可以用”来转义。
下面通过实例说明sed的用法:
1)以行为单位的新增/删除
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
[root@www ~]# cat /etc/passwd | sed '2,5d'
只要删除第2行
[root@www ~]# cat /etc/passwd | sed '2d'
要删除第3到最后一行
[root@www ~]# cat /etc/passwd | sed '3,$d'
在第二行后(亦即是加在第三行)加上drink tea字样!
[root@www ~]# cat /etc/passwd | sed '2a drink tea'
那如果是要在第二行前添加
[root@www ~]# cat /etc/passwd | sed '2i drink tea'
在匹配root的行的前面添加extension="huanqiu"
(-i参数表示直接在文件里添加,而不是仅仅在终端输出里添加)
[root@www ~]# cat /etc/passwd | sed -i '/root/i extension="huanqiu"'
如果是要增加两行以上,在第二行后面加入两行字,例如『Drink tea or .....』与『drink beer?』
[root@www ~]# cat /etc/passwd | sed '2a Drink tea or ...... //回车,添加第二行内容,每行之间用隔开
> drink beer ?'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
注意:
每一行之间都必须要以反斜杠『 』来进行新行的添加!
所以,上面的例子中,我们可以发现在第一行的最后面就有 存在。
添加多行内容如下:
添加多行内容如下:
[root@www ~]# cat /etc/passwd | sed '2a Drink tea or ......
> drink beer ?
> wangshibo
> hahaha'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
wangshibo
hahaha
如果多行之间不加隔开,那么就默认加到一行:
[root@www ~]# cat /etc/passwd | sed '2a Drink tea or ...... wangshibo'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ...... wangshibo
2)以行为单位的替换与显示
将第2-5行的内容取代成为『No 2-5 number』
[root@www ~]# cat /etc/passwd | sed '2,5c No 2-5 number'
透过这个方法我们就能够将数据整行取代了!
仅列出 /etc/passwd 文件内的第 5-7 行
[root@www ~]# cat /etc/passwd | sed -n '5,7p'
可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示
3)数据的搜寻并显示
搜索 /etc/passwd有root关键字的行
[root@www ~]# cat /etc/passwd | sed '/root/p'
如果root找到,除了输出所有行,还会输出匹配行。
使用-n的时候将只打印包含模板的行。
[root@www ~]# cat /etc/passwd | sed -n '/root/p'
4)数据的搜寻并删除
删除/etc/passwd所有包含root的行,其他行输出
[root@www ~]# cat /etc/passwd | sed '/root/d'
5)数据的搜寻并执行命令
找到匹配模式eastern的行后,执行后面花括号中的一组命令,每个命令之间用分号分隔。
下面表示搜索匹配root的行后,把bash替换为blueshell,再输出这行:
[root@www ~]# cat /etc/passwd | sed -n '/root/{s/bash/blueshell/;p}'
1 root:x:0:0:root:/root:/bin/blueshell
如果只替换/etc/passwd的第一个bash关键字为blueshell,就退出
[root@www ~]# cat /etc/passwd | sed -n '/bash/{s/bash/blueshell/;p;q}'
1 root:x:0:0:root:/root:/bin/blueshell
最后的q是退出。
6)数据的搜寻并替换
除了整行的处理模式之外,sed 还可以用行为单位进行部分数据的搜寻并取代。基本上sed的搜寻与替代的与vi相当的类似!
它有点像这样:
sed 's/要被取代的字串/新的字串/g'
先观察原始信息,利用 /sbin/ifconfig 查询 IP
[root@www ~]# /sbin/ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
将 IP 前面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g'
192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
接下来则是删除后续的部分,亦即: 192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
将 IP 后面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*$//g'
192.168.1.100
7)多点编辑(-e参数)
一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell
[root@www ~]# cat /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
1 root:x:0:0:root:/root:/bin/blueshell
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
-e表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell。
8)直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向!
不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试! 我们还是使用下载的 regular_express.txt 文件来测试看看吧!
利用sed将regular_express.txt 内每一行结尾若为 . 则换成 !
[root@www ~]# sed -i 's/.$/!/g' regular_express.txt
利用sed直接在 regular_express.txt 最后一行加入『# This is a test』
[root@www ~]# sed -i '$a # This is a test' regular_express.txt
由于$代表的是最后一行,而a的动作是新增,因此该文件最后新增『# This is a test』
sed的-i选项表示:可以直接修改文件内容,这功能非常有帮助!
举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!
这个时候就可以利用sed了,非常高效方面!!透过sed直接修改/取代的功能,甚至不需要使用vim去修订了!
----------------------------------------------------------------------------------------------------------------------
以下是经常用到的一些sed操作
[root@www ~]# sed -e 's/123/1234/' a.txt
将a.txt文件中所有行中的123用1234替换(-e表示命令以命令行的方式执行;参数s,表示执行替换操作)
[root@www ~]# sed -e '3,5 a4' a.txt
将a.txt文件中的3行到5行之间所有行的后面添加一行内容为4的行(参数a,表示添加行,参数a后面指定添加的内容)
[root@www ~]# sed -e '1s/12/45/' a.txt
把第一行的12替换成45(-e参数表示输出结果到当前终端下,即只在输出的结果中替换,其实文件里并没有真实生效;要使文件中的替换生效,需使用-i参数)
[root@www ~]# sed -i "s/oldstring/newstring/g" `grep oldstring -rl yourdir`
批量处理通过grep搜索出来的所有文档,将这些文档中所有的oldstring用newstring替换(-i参数表示直接对目标文件操作)
[root@www ~]# sed -n 's/^test/mytest/p' example.file
(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。(^这是正则表达式中表示开头,该符号后面跟的就是开头的字符串)(参数p表示打印行)
[root@www ~]# sed 's/^wangpan/&19850715/' example.file
表示被替换换字符串被找到后,被替换的字符串通过&符号连接给出的字符串组成新字符传替换被替换的字符串,所有以wangpan开头的行都会被替换成它自已加19850715,变成wangpan19850715
[root@www ~]# sed -n 's/(love)able/1rs/p' example.file
love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。需要将这条命令分解,s/是表示替换操作,(love)表示选中love字符串,(love)able/表示包含loveable的行,(love)able/l表示love字符串标记为1,表示在替换过程中不变。rs/表示替换的目标字符串。这条命令的操作含义:只打印替换了的行
[root@www ~]# sed 's[root@www ~]#10[root@www ~]#100[root@www ~]#g' example.file
不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“[root@www ~]#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
[root@www ~]# sed -n '/love/,/unlove/p' example.file
只打印包含love字符串行到包含unlove字符串行之间的所有行(确定行的范围就是通过逗号实现的)
[root@www ~]# sed -n '5,/^wang/p' example
只打印从第五行开始到第一个包含以wang开始的行之间的所有行
[root@www ~]# sed '/love/,/unlove/s/[root@www ~]#/wangpan/' example.file
对于包含love字符串的行到包含unlove字符串之间的行,每行的末尾用字符串wangpan替换。
字符串[root@www ~]#/表示以字符串结尾的行,[root@www ~]#/表示每一行的结尾,s/[root@www ~]#/wangpan/表示每一行的结尾添加wangpan字符串
[root@www ~]# sed -e '11,53d' -e 's/wang/pan/' example.file
(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除11至53行,第二条命令用pan替换wang。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。(参数d,表示删除指定的行)
[root@www ~]# sed --expression='s/wang/pan/' --expression='/love/d' example.file
一个比-e更好的命令是--expression。它能给sed表达式赋值。
[root@www ~]# sed '/wangpan/r file' example.file
file里的内容被读进来,显示在与wangpan匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。参数r,表示读出文件,后面空格紧跟文件名称
[root@www ~]# sed -n '/test/w file' example.file
在example.file中所有包含test的行都被写入file里。参数w,表示将匹配的行写入到指定的文件file中
[root@www ~]# sed '/^test/aoh! My god!' example.file
'oh! My god!'被追加到以test开头的行的后面,sed要求参数a后面有一个反斜杠。
[root@www ~]# sed '/test/ioh! My god!' example.file
'oh! My god!'被追加到包含test字符串行的前面,参数i表示添加指定内容到匹配行的前面,sed要求参数i后面有一个反斜杠
[root@www ~]# sed '/test/{ n; s/aa/bb/; }' example.file
如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb。参数n,表示读取匹配行的下一个输入行,用下一个命令处理新的行而不是匹配行。Sed要求参数n后跟分号
[root@www ~]# sed '1,10y/abcde/ABCDE/' example.file
把1—10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。参数y,表示把一个字符翻译为另外的字符(但是不用于正则表达式)
[root@www ~]# sed -i 's/now/right now/g' test_sed_command.txt
表示直接操作文件test_sed_command.txt,将文件test_sed_command.txt中所有的now用right now替换。参数-i,表示直接操作修改文件,不输出。
[root@www ~]# sed '2q' test_sed_command.txt
在打印完第2行后,就直接退出sed。参数q,表示退出
[root@www ~]# sed -e '/old/h' -e '/girl-friend/G' test_sed_command.txt
首先了解参数h,拷贝匹配成功行的内容到内存中的缓冲区。在了解参数G,获得内存缓冲区的内容,并追加到当前模板块文本的后面。上面命令行的含义:将包含old字符串的行的内容保存在缓冲区中,然后将缓冲区的内容拿出来添加到包含girl-friend字符串行的后面。隐含要求搜集到缓冲区的匹配行在需要添加行的前面。
[root@www ~]# sed -e '/test/h' -e '/wangpan/x' example.file
将包含test字符串的行的内容保存在缓冲区中,然后再将缓冲区的内容替换包含wangpan字符串的行。参数x,表示行替换操作。隐含要求搜集到缓冲区的匹配行在需要被替换行的前面。
如果sed在打印时不加-n参数,那么打印多少行,其实就是在多少行下面打印这行内容,如下:
[root@www ~]# cat pets.txt
1111
222
3333
aaaa
bbb
vvvv
[root@www ~]# sed '3p' pets.txt
1111
222
3333
3333
aaaa
bbb
vvvv
[root@www ~]# sed '3p;5p' pets.txt
1111
222
3333
3333
aaaa
bbb
bbb
vvvv
把其中的my字符串替换成Hao Chen’s
注意:如果你要使用单引号,那么你没办法通过’这样来转义,就有双引号就可以了,在双引号内可以用”来转义。
[root@www ~]# sed "s/my/Hao Chen's/g" pets.txt
再注意:上面的sed并没有对文件的内容改变,只是把处理过后的内容输出,如果你要写回文件,你可以使用重定向,如:
[root@www ~]# sed "s/my/Hao Chen's/g" pets.txt > pets.txt
或使用 -i 参数直接修改文件内容:
[root@www ~]# sed -i "s/my/Hao Chen's/g" pets.txt
在每一行最前面加点东西,比如在每一行的前面添加#号或wang字符
[root@www ~]# sed 's/^/#/g' pets.txt
[root@www ~]# sed 's/^/wang/g' pets.txt
[root@www ~]# sed -i 's/^/wang/g' pets.txt //直接在文件中生效
在每一行最后面加点东西,比如在每一行的后面添加 --- 或者done字符
[root@www ~]# sed 's/$/ --- /g' pets.txt
[root@www ~]# sed 's/$/done/g' pets.txt
顺便介绍一下正则表达式的一些最基本的东西:
^ 表示一行的开头。如:/^#/ 以#开头的匹配。
[root@www ~]# 表示一行的结尾。如:/}[root@www ~]#/ 以}结尾的匹配
< 表示词首。 如 表示词尾。 如 abc> 表示以 abc 結尾的詞.
. 表示任何单个字符。
* 表示某个字符出现了0次或多次。
[ ] 字符集合。 如:[abc]表示匹配a或b或c,还有[a-zA-Z]表示匹配所有的26个字符。如果其中有^表示反,如[^a]表示非a的字符
正规则表达式是一些很神奇的事,比如要去掉a.html文件中的tags:
[root@www ~]# cat a.html
<b>This</b> is what <span style="text-decoration: underline;">I</span> meant. Understand?
如果这样搞的话,就会有问题
[root@www ~]# sed 's/<.*>//g' a.html
meant. Understand?
要解决上面的那个问题,就得像下面这样。
其中的'[^>]' 指定了除了>的字符重复0次或多次。
[root@www ~]# sed 's/<[^>]*>//g' a.html
This is what I meant. Understand?
只替换每一行的第一个s:
[root@www ~]# sed 's/s/S/1' my.txt
只替换每一行的第二个s:
[root@www ~]# sed 's/s/S/2' my.txt
只替换第一行的第3个以后的s:
[root@www ~]# sed 's/s/S/3g' my.txt
多个匹配
如果我们需要一次替换多个模式,可参看下面的示例:(第一个模式把第一行到第三行的my替换成your,第二个则把第3行以后的This替换成了That)
[root@www ~]# sed '1,3s/my/your/g; 3,[root@www ~]#s/This/That/g' my.txt
上面的命令等价于:(注:下面使用的是sed的-e命令行参数)
[root@www ~]# sed -e '1,3s/my/your/g' -e '3,[root@www ~]#s/This/That/g' my.txt
可以使用&来当做被匹配的变量,然后可以在基本左右加点东西。如下所示:
[root@www ~]# cat b.txt
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
[root@www ~]# sed 's/my/[&]/g' b.txt
This is [my] cat, [my] cat's name is betty
This is [my] dog, [my] dog's name is frank
This is [my] fish, [my] fish's name is george
This is [my] goat, [my] goat's name is adam
圆括号匹配
使用圆括号匹配的示例:(圆括号括起来的正则表达式所匹配的字符串会可以当成变量来使用,sed中使用的是1,2…)
[root@www ~]# sed 's/This is my ([^,]*),.*is (.*)/1:2/g' b.txt
cat:betty
dog:frank
fish:george
goat:adam
上面这个例子中的正则表达式有点复杂,解开如下(去掉转义字符):
正则为:This is my ([^,]*),.*is (.*)
匹配为:This is my (cat),……….is (betty)
然后:1就是cat,2就是betty
N命令:把下一行的内容纳入当成缓冲区做匹配。
下面的的示例会把原文本中的偶数行纳入奇数行匹配,而s只匹配并替换一次,所以,就成了下面的结果:
即匹配奇数行的替换,偶数行的不匹配:
[root@www ~]# vim a.txt
[root@www ~]# cat a.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
[root@wutao ~]# sed 'N;s/my/your/' a.txt
This is your cat
my cat's name is betty
This is your dog
my dog's name is frank
This is your fish
my fish's name is george
This is your goat
my goat's name is adam
也就是说,原来的文件成了:
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
这样一来,下面的例子你就明白了,
[root@www ~]# sed 'N;s/
/,/' a.txt
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
a命令和i命令
a命令就是append, i命令就是insert,它们是用来添加行的。
其中的1i表明,其要在第1行前插入一行(insert)
[root@www ~]# cat a.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
[root@www ~]# sed "1 i This is my monkey, my monkey's name is wukong" a.txt
This is my monkey, my monkey's name is wukong
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
其中的1a表明,其要在最后一行后追加一行(append)
[root@www ~]# sed "$ a This is my monkey, my monkey's name is wukong" a.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
This is my monkey, my monkey's name is wukong
可以运用匹配来添加文本:
注意其中的/fish/a,这意思是匹配到/fish/后就追加一行
[root@www~]# sed "/fish/a This is my monkey, my monkey's name is wukong" a.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
This is my monkey, my monkey's name is wukong
my fish's name is george
This is my monkey, my monkey's name is wukong
This is my goat
my goat's name is adam
下面这个例子是对每一行都挺插入:
[root@www ~]# sed "/my/a ----" a.txt
This is my cat
----
my cat's name is betty
----
This is my dog
----
my dog's name is frank
----
This is my fish
----
my fish's name is george
----
This is my goat
----
my goat's name is adam
----
c命令
c 命令是替换匹配行
[root@www ~]# sed "2 c This is my monkey, my monkey's name is wukong" a.txt
This is my cat
This is my monkey, my monkey's name is wukong
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
[root@www ~]# sed "/fish/c This is my monkey, my monkey's name is wukong" a.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my monkey, my monkey's name is wukong
This is my monkey, my monkey's name is wukong
This is my goat
my goat's name is adam
d命令
删除匹配行
从一个模式到另一个模式
[root@www ~]# sed -n '/dog/,/fish/p' my.txt
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
从第一行打印到匹配fish成功的那一行
[root@www ~]# sed -n '1,/fish/p' my.txt
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
sed的Address
第一个是关于address,几乎上述所有的命令都是这样的(注:其中的!表示匹配成功后是否执行命令)
[address[,address]][!]{cmd}
address可以是一个数字,也可以是一个模式,你可以通过逗号要分隔两个address 表示两个address的区间,参执行命令cmd,伪代码如下:
[root@wutao ~]# cat b.txt
This is my cat, my cat's name is betty
This is my dog, my dog's name is frank
This is my fish, my fish's name is george
This is my goat, my goat's name is adam
其中的+3表示后面连续3行
[root@wutao ~]# sed '/dog/,+3s/^/# /g' b.txt
This is my cat, my cat's name is betty
# This is my dog, my dog's name is frank
# This is my fish, my fish's name is george
# This is my goat, my goat's name is adam
sed命令打包
第二个是cmd可以是多个,它们可以用分号分开,可以用大括号括起来作为嵌套命令。下面是几个例子:
[root@wutao ~]# cat d.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
This is my fish
my fish's name is george
This is my goat
my goat's name is adam
对3行到第6行,执行命令/This/d
[root@wutao ~]# sed '3,6 {/This/d}' d.txt
This is my cat
my cat's name is betty
my dog's name is frank
my fish's name is george
This is my goat
my goat's name is adam
对3行到第6行,匹配/This/成功后,再匹配/fish/,成功后执行d命令
[root@wutao ~]# sed '3,6 {/This/{/fish/d}}' d.txt
This is my cat
my cat's name is betty
This is my dog
my dog's name is frank
my fish's name is george
This is my goat
my goat's name is adam
从第一行到最后一行,如果匹配到This,则删除之;如果前面有空格,则去除空格
[root@wutao ~]# sed '1,${/This/d;s/^ *//g}' d.txt
my cat's name is betty
my dog's name is frank
my fish's name is george
my goat's name is adam
sed的Hold Space
需要先了解一下Hold Space的概念,先来看四个命令:
g:将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
G:将hold space中的内容append到pattern space
后
h:将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
H:将pattern space中的内容append到hold space
后
x:交换pattern space和hold space的内容
反序了一个文件的行(可以直接用tac命令反序)
[root@www ~]# cat c.txt
11111
22222
33333
aaaaa
bbbbb
ccccc
[root@www ~]# sed '1!G;h;$!d' c.txt
ccccc
bbbbb
aaaaa
33333
22222
11111
其中的 ’1!G;h;$!d’ 可拆解为三个命令:
1!G —— 只有第一行不执行G命令,将hold space中的内容append回到pattern space
h —— 第一行都执行h命令,将pattern space中的内容拷贝到hold space中
$!d —— 除了最后一行不执行d命令,其它行都执行d命令,删除当前行
[root@www ~]# tac c.txt
ccccc
bbbbb
aaaaa
33333
22222
11111
找到以north开头的行并在其后添加很多wang和huan,
表示换行
[root@www ~]# cat e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@www ~]# sed '/^north/aFUCK FUCK FUCK FUCK
kcuf kcuf kcuf kcuf' e.txt
northwest NW Charles Main 3.0 .98 3 34
FUCK FUCK FUCK FUCK
kcuf kcuf kcuf kcuf
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
FUCK FUCK FUCK FUCK
kcuf kcuf kcuf kcuf
north NO Margot Weber 4.5 .89 5 9
FUCK FUCK FUCK FUCK
kcuf kcuf kcuf kcuf
central CT Ann Stephens 5.7 .94 5 13
--------------------------------------------------------------------------------------------------------
发现在bash中只能像上面那样输入且a后的可有可无 ; 并不像书上说的那样,不知是不是跟SHELL有关系
一般,a后是要带的,有时还要带两个。如果要添加的文本不止一行的话,除了最后一行每一行的结尾都要跟。以上只是在控制台输入,在脚本中输入的情况还是和书上说的一样的。
--------------------------------------------------------------------------------------------------------
在以central开头的行前分行插入FUCK
[root@www ~]# sed '/central/iF
U
C
K' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
F
U
C
K
central CT Ann Stephens 5.7 .94 5 13
--------------------------------------------------------------------------------------------------------
一般,如果要添加的文本不止一行的话,除了最后一行每一行的结尾都要跟。但在我这里好像有点不一样,在终端直接输入时。
--------------------------------------------------------------------------------------------------------
把有sourth的行全部用FUCK取代
[root@www ~]# sed '/south/cFUCK' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
FUCK
FUCK
FUCK
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
用FUCK替换所有以south开头的行中的south.
[root@www ~]# sed '/^south/s/south/FUCK/g' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
FUCKwest SW Lewis Dalsass 2.7 .8 2 18
FUCKern SO Suan Chin 5.1 .95 4 15
FUCKeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
寻找大于1少于10的一位小数并用FUCK+&替代。这里的&保存了前面的小数
[root@www ~]# sed 's/[0-9].[0-9]/FUCK&/' e.txt
northwest NW Charles Main FUCK3.0 .98 3 34
western WE Sharon Gray FUCK5.3 .97 5 23
southwest SW Lewis Dalsass FUCK2.7 .8 2 18
southern SO Suan Chin FUCK5.1 .95 4 15
southeast SE Patricia Hemenway FUCK4.0 .7 4 17
eastern EA TB Savage FUCK4.4 .84 5 20
northeast NE AM Main Jr. FUCK5.1 .94 3 13
north NO Margot Weber FUCK4.5 .89 5 9
central CT Ann Stephens FUCK5.7 .94 5 13
p也会把匹配的行打印两次。也就是说不使用-n选项的话,p会打印出匹配两次
[root@www ~]# sed '/north/p' e.txt
northwest NW Charles Main 3.0 .98 3 34
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
P--多行打印:在执行完所有命令后模式空间的内容会自动输出,在下面的例子中可以看到匹配的行输出了两次,但是-n选项会抑制这个动作。只有在与D,N配合使用时才会输出模式空间里的第一行,此时不用-n选项。
[root@www ~]# sed '/north/P' e.txt
northwest NW Charles Main 3.0 .98 3 34
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
多行删除:选项看到d与D的不同之处了么?其中空行分别为1,2,3,4行。
[root@www ~]# cat g.txt
this is a test line
this is a test line
this is a test line
this is a test line
this ia a test line
[root@www ~]# sed -e '/^$/N' -e '/^
$/d' g.txt
this is a test line
this is a test line
this is a test line
this is a test line
this ia a test line
[root@www ~]# sed -e '/^$/N' -e '/^
$/D' g.txt
this is a test line
this is a test line
this is a test line
this is a test line
this ia a test line
--------------------------------------------------------------------------------------------------------
可以看到,与N配合的情况下:
使用d,若有偶数个空行将会全被删除,若有奇数个空行将会保留一行。这是因为d删除的是整个模式空间的内容。一旦遇到第一个空行就马上读入下一行,然后两行都删除。如果第三行为空且下一行不为空则命令不执行,空行被输出。
使用D,当遇到两个空行时D会删除两个空行中的第一个,然后再读入下一行,如果是空行则删除第一行,如果空行后有文本则模式空间可以正常输出。
--------------------------------------------------------------------------------------------------------
r--从文件中读取:从test中读取相关的内容添加到e.txt中所有匹配的行的后面。
[root@www ~]# cat test
sssss
11111
[root@www ~]# cat e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@www ~]# sed '/^south/r test' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
sssss
11111
southern SO Suan Chin 5.1 .95 4 15
sssss
11111
southeast SE Patricia Hemenway 4.0 .7 4 17
sssss
11111
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
w--写入文件:把e.txt中所有匹配的行写入到test文件中
[root@www ~]# sed '/^south/w test' e.txt|cat test
sssss
11111
[root@www ~]# cat test
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
n--next:如果有能匹配western行,则n命令使得sed读取下一行,然后执行相应命令
[root@www ~]# cat e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@www ~]# sed -e '/western/n' -e 's/SW/FUCK/' e.txt|head -n 4
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest FUCK Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
y--变换:
[root@www ~]# sed '3,5y/s/S/' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
SouthweSt SW LewiS DalSaSS 2.7 .8 2 18
Southern SO Suan Chin 5.1 .95 4 15
SoutheaSt SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@www ~]# sed '1y/3/9/' e.txt
northwest NW Charles Main 9.0 .98 9 94
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
--------------------------------------------------------------------------------------------------------
替换的类型要一致,数字与字母之间不能相互替换。
且对正则表达式的元字符不起作用。
--------------------------------------------------------------------------------------------------------
q--退出:
打印三行后退出
[root@www ~]# sed '3q' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
用相应的字符做出替换后退出
[root@www ~]# sed -e 'y/northwest/ABCDEFGHI/' -e q e.txt
ABCDEFGHD NW CEaClGH MaiA 3.0 .98 3 34
或者
[root@www ~]# sed '{ y/northwest/ABCDEFGHI/; q;}' e.txt
ABCDEFGHD NW CEaClGH MaiA 3.0 .98 3 34
多个命令写在一行时可以用-e选项,也可以用花括号把所有命令括起来并用分号隔开且最后一个分号可有可无。
H/h/G/g--保存和取得
[root@www ~]# sed -e '/northeast/h' -e '$g' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
northeast NE AM Main Jr. 5.1 .94 3 13
[root@www ~]# sed -e '/northeast/h' -e '$G' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
northeast NE AM Main Jr. 5.1 .94 3 13
[root@www ~]# sed -e '/northeast/H' -e '$g' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
northeast NE AM Main Jr. 5.1 .94 3 13
[root@www ~]# sed -e '/northeast/H' -e '$G' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
northeast NE AM Main Jr. 5.1 .94 3 13
H/G在相应空间的内容之后放置一个换行符,且后面紧跟模式空间的内容;而g/h的呢都是取代相应空间的内容,所以就有上面的不同结果。
x--交换模式/保持空间内容
首先匹配第一个包含north的行放入保持缓存,然后匹配第一个包含south的行放入模式空间,最后把两者的内容交换。
[root@www ~]# sed -e '/north/h' -e '/south/x' e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
northwest NW Charles Main 3.0 .98 3 34
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
--------------------------------sed脚本用法----------------------------------
[root@www ~]# cat e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@www ~]# cat sedscripts
/central/a
------This is a test--------
/northeast/i
------This is a test too------
[root@www ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
------This is a test too------
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
------This is a test--------
可以在里面添加注释,以#开头的行被认为是注释
如有多行,则每行都要以结尾,除了最后一行。
如下面的脚本是可以正常执行的。
[root@www ~]# cat sedscripts
#This script is a test for sed commands list
/central/a
------This is a test too--------
------Hi am here----------------
#now ,the second test
/northeast/i
------This is a test ------
[root@www ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
------This is a test ------
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
------This is a test too--------
------Hi am here----------------
--------------------------------高级流控制命令--------------------------------
b 分支 :无条件转移
t 测试 :有条件的转移
它们将脚本中的控制转移到包含特殊标签的行;如果没有标签则直接转移到脚本的末尾。只有当替换命令改变当前行时才会被执行。
标签:任意的字符组合且长度不大于7,它本身占据一行且以冒号开头
:mylabel
冒号和标签之间不能有空格,标签后的空格会被当做标签的一部分。
标签和命令之间允许有空格。
b 分支:[address] b [label]
b --> branch,在脚本中将控制权转到另一行,通过它你可以跳到你想去的地方,是不是有点像c中的goto呀?
它可以将一组命令当做一个过程来执行且这个过程在脚本中可以重复执行,只要条件满足。
b--分支
匹配以north加空格开头的行,若匹配则转到:label后面的命令,在以s开头的行前插入FFFFFFFFFFFFFFUCK ;
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
:label
/^s/i
FFFFFFFFFFFFFFUCK
/^north / b label
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
FFFFFFFFFFFFFFUCK
southwest SW Lewis Dalsass 2.7 .8 2 18
FFFFFFFFFFFFFFUCK
southern SO Suan Chin 5.1 .95 4 15
FFFFFFFFFFFFFFUCK
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
其实这也是个循环,反复执行两个标签间的命令,直到模式不匹配。但是,如上,不管匹配与否两个标签间的内容至少会被执行一次。
也就是说,正常情况下上面的命令都会被执行一次。看下面的例子:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
:label
/^n/d
/^A/b label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
看到了吧!虽然模式不匹配,但还是执行了两个标签间的内容,嘿嘿!再看看上面,和do-while语句有什么异同?
如果匹配,什么都不做,否则执行后的命令向以cent开头的行后添加一些内容
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
:label
/^A/b label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
另一种循环模式
command1
/pattern/b label
command2
label:
command3
首先执行command1,然后看模式是否匹配,若匹配则执行command3,否则执行command2,command3
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^n/d
/^A/b label
s/south/SSSSSS/
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
western WE Sharon Gray 5.3 .97 5 23
SSSSSSwest SW Lewis Dalsass 2.7 .8 2 18
SSSSSSern SO Suan Chin 5.1 .95 4 15
SSSSSSeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
模式不匹配,顺序执行各命令,下面来看匹配的情况:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^w/d
#north后有一个空格
/^north /b label
s/south/SSSSSS/
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
SSSSSSwest SW Lewis Dalsass 2.7 .8 2 18
SSSSSSern SO Suan Chin 5.1 .95 4 15
SSSSSSeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
很显然,这里并没有跳过第二个命令,但是理论上只模式空间匹配的话就会直接转到:label后的命令的呀!这到底是为什么呢?来看下一个脚本,只对上个脚本做一点点修改:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^w/d
#north后有一个空格
/^north /b label
s/north /SSSSSS/
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
这次结果正常啦,它找到了以north加空格开头的行,并跳过了第二个命令。
再来看两个例子:
在第二个命令后再添加一个命令s/south/NNNNNN看会有怎样的结果:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^w/d
/^north /b label
s/north /SSSSSS/
s/south/NNNNNN/
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
NNNNNNwest SW Lewis Dalsass 2.7 .8 2 18
NNNNNNern SO Suan Chin 5.1 .95 4 15
NNNNNNeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
显然,s/north /SSSSSS/ 没有被执行而s/south/NNNNNN/ 被执行啦
又一个例子:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^w/d
/^north/b label
p
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
southwest SW Lewis Dalsass 2.7 .8 2 18
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
可以看到p应用到了除以north开头的所有行!再来一个例子:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^w/d
/^north/b label
p
l
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW Charles Main 3.0 .98 3 34
southwest SW Lewis Dalsass 2.7 .8 2 18
southwest SW Lewis Dalsass 2.7 .8 2 18$
southwest SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southern SO Suan Chin 5.1 .95 4 15$
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
southeast SE Patricia Hemenway 4.0 .7 4 17$
southeast SE Patricia Hemenway 4.0 .7 4 17
eastern EA TB Savage 4.4 .84 5 20
eastern EA TB Savage 4.4 .84 5 20$
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
central CT Ann Stephens 5.7 .94 5 13$
central CT Ann Stephens 5.7 .94 5 13
--FUCK!!!
Just a test!
Take it easy!!!
看到了么?P,l都只应用到了除以north开头的所有行上!!!
从上面的一堆例子中,可以得到:在
command1
/pattern/b label
command2
label:
command3
模式中 只有 针对 匹配pattern的行 的操作才会被跳过!
如何指定执行上例中的command2或command3中的一个
commmand1
/pattern/b label
command2
b
:label
command3
首先执行command1,然后执行/pattern/b label,如果模式匹配则直接跳到command3并执行相关命令,否则跳到command2在执行完相关命令后遇到分支b,分支b将控制转到脚本的结尾,绕过了command3.
下面看一个简单的例子:
[root@wutao ~]# cat sedscripts
#This script is a test for sed commands
/^e/d
/^DDD/b label
s/west/SSSSSS/
b
:label
/^cent/a
--FUCK!!!
Just a test!
Take it easy!!!
[root@wutao ~]# sed -f sedscripts e.txt
northSSSSSS NW Charles Main 3.0 .98 3 34
SSSSSSern WE Sharon Gray 5.3 .97 5 23
southSSSSSS SW Lewis Dalsass 2.7 .8 2 18
southern SO Suan Chin 5.1 .95 4 15
southeast SE Patricia Hemenway 4.0 .7 4 17
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
果然当模式不匹配时只执行command2而:label后的命令没有被执行
t: [address] t [label]
t-->test,如果在当前匹配的行上成功地进行了替换,那么t命令就转到标签处或脚本末尾(未给定标签默认指向脚本末尾)。
t要单独成行
下面来一个简单的例子:
[root@wutao ~]# cat sedscripts
/^s/d
/^west/s/west/QQQ/
t label1
/^n/y/nort/FUCK/
t label
:label
/^F/y/FUCK/nort/
:label1
/^QQQ/s/QQQ/west/
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW rharles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13
[root@wutao ~]# cat sedscripts
/^s/d
/^west/y/Q/a/
t label1
/^n/y/nort/FUCK/
t label
:label
/^F/y/FUCK/nort/
:label1
/^n/y/FUCK/nort/
[root@wutao ~]# sed -f sedscripts e.txt
northwest NW rharles Main 3.0 .98 3 34
western WE Sharon Gray 5.3 .97 5 23
eastern EA TB Savage 4.4 .84 5 20
northeast NE AM Main Jr. 5.1 .94 3 13
north NO Margot Weber 4.5 .89 5 9
central CT Ann Stephens 5.7 .94 5 13