对于Elasticsearch的学习,需要清楚的明白它的每个核心概念,由浅入深的了解,才能更好的掌握这门技术。下面先简单罗列下Elasticsearch的核心概念:

一、Elasticsearch数据组织
1. 逻辑组织
如下图所示,Elasticsearch使用index和doc_type来组织数据。doc_type中的每条数据称为一个document,是一个JSON Object,相关的schema信息通过mapping来定义。mapping不仅仅包括数据类型的定义,还有很多其他元信息的设置,它们共同决定了数据如何被存储和索引。这四个概念实现了Elasticsearch的逻辑数据组织,假设有一批结构化或半结构化数据需要存储,我们会先对数据进行分类,设计相应的index与doc_type,再为每个doc_type设置相关的mapping信息。如果不指定mapping,Elasticsearch会使用默认值,并自动为你推导每个字段的类型,即支持schema free的特性。但是,这种灵活性也会带来一些问题,一方面会失去对数据的控制,即会越来越不清楚你的数据结构,另一方面,自动推导出来数据类型可能不是预期的,会带来写入和查询问题。所以,笔者建议,尽最大可能对schema加以约束。

通常情况下,我们都会拿Elasticsearch的这些概念跟关系型数据库Mysql来做对比以便更好的理解,比如index等价于database,doc_type等价于table,mapping等价于db schema。但是需要注意的是:对于关系型数据库而言,table与table之间是完全独立的,不同table的schema是完全隔离的,而Elasticsearch中的doc_type则不是。同一个index下不同doc_type中的字段在底层是合并在一起存储的,意味着假设两个doc_type中都有一个叫name的字段,那么这两个字段的mapping必须一样。基于这个原因,Elasticsearch官方从6.0开始淡化doc_type的概念,推荐一个index只拥有一个doc_type,并计划在8.x完全废弃doc_type。因此,在当前的index设计中,最好能遵循这个规则。
2. 物理组织
Elasticsearch是一个分布式系统,其数据会分散存储到不同的节点上。为了实现这一点,需要将每个index中的数据划分到不同的块中,然后将这些数据块分配到不同的节点上存储。这里的数据块,就是shard。通过"分"的思想,可以突破单机在存储空间和处理性能上的限制,这是分布式系统的核心目的。而对于分布式存储而言,还有一个重要特性是"冗余",因为分布式的前提是:接受系统中某个节点因为某些故障退出。为了保证在故障节点退出后数据不丢失,同一份数据需要拷贝多份存在不同节点上。因此,shard从角色上划分为primary shard和replica shard两种,数据会首先写入primary shard,然后同步到replica shard中。

shard是Elasticsearch中最小的数据分配单位,即一个shard总是作为一个整体被分配到某个节点,而不会只分配其中一部分。那么,shard中的数据又是如何组织的?答案是segment。一个shard包含一组segment,segment是最小的数据单元,Elasticsearch每隔一段时间产生一个新的segment,里面包含了新写入的数据。segment是immutable的,即不可改变,这样设计的考量是:一方面,不支持修改就不用对读写操作加锁,省去了相关开销;另一方面,因为文件内容不会修改,可以更好的利用filesystem cache进行缓存,提高查询性能。但是,任何设计都不是完美的,伴随而来的问题是:如果segment不可修改,怎么实现数据的更新与删除呢?这个问题将在Elasticsearch的"数据写入"内容中说到。
二、Elasticsearch数据分布
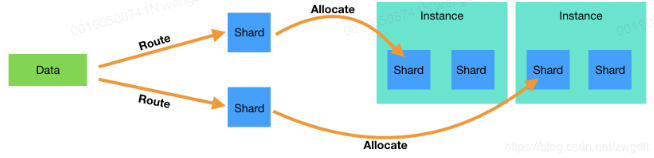
上面说到Elasticsearch将每个index中的数据划分到不同的shard中,然后将shard分配到不同的节点上,实现分布式存储。这里面涉及到两个概念:一个是数据到shard的映射(route),另一个是shard到节点的映射(shard allocate)。一方面:插入一条数据时,Elasticsearch会根据指定的key来计算应该落到哪个shard上。默认key是自动分配的id,可以自定义,比如在业务中采用CompanyID作为key。因为primary shard的个数是不允许改变的,所以同一个key每次算出来的shard是一样的,从而保证了准确定位。
shard_num = hash(_routing) % num_primary_shards
另一方面:master节点会为每个shard分配相应的data节点进行存储,并维护相关元信息。通过route计算出来的shard序号,在元信息中找到对应的存储节点,便可完成数据分布。shard allocate的映射关系并不是完全不变的,当检测到数据分布不均匀、有新节点加入或者有节点挂掉等情况时就会进行调整,称为relocate。
三、Elasticsearch集群角色
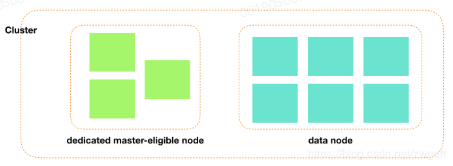
一个分布式系统,是由多个节点各司其职、相互协作完成整体服务的,从架构上可以分为有中心管理节点和无中心管理节点两种,Elasticsearch属于前者。中心管理节点负责维护整个系统的状态和元信息,为了保证高可用性,通常是从一组候选节点中选举出来的,而非直接指定。按照职责,Elasticsearch将节点分为三种:master-eligible节点、data节点、ingest节点。master-eligible节点就是中心节点的候选人,通过选举算法从这些候选人中推选出大家公认的中心节点。data节点负责数据存储、查询,也是整个系统中负载最重的部分。ingest节点是针对Elasticsearch一个特定功能而设定的,Elasticsearch支持在数据写入前对数据进行相关的转换、处理,而这类节点就是负责这样的工作,从笔者遇到的实践来看,使用这类节点的并不多。
这三种角色是通过配置来设定的,可以同时设置到同一个节点上,即一个节点可以同时具备这三种功能。但是这种做法只适用于数据量小、业务较轻的场景,因为不同角色承担的功能所带来的负载是不同的,很可能因为数据写入/查询负载较重导致master节点通信受到影响,从而导致系统不稳定。所以,推荐将不同角色分离开,某个节点只负责其中一个功能,通常会设置dedicated master-eligible节点、data/ingest节点。前者负载很轻,只需要分配较低配置的机器,而后者对CPU、IO、Memory要求较高,需要配置更好的机器,实践中根据性能测试结果来调整。
前面说到,中心节点(master)是从一组候选人(master-eligible)中选举出来的,那设置多少个候选人是合理的?原则是要保证任何时候系统只有一个确定的master节点。考虑到一致性,只有被半数以上候选节点都认可的节点才能成为master节点,否则就会出现多主的情况。只有1个候选节点显然不能保证高可用;有2个时,半数以上(n/2+1)的个数也是2,任何一个出现故障就无法继续工作了;有3个时,半数以上的值仍然是2,恰好可以保证master故障或网络故障时系统可以继续工作。因此,3个dedicated master-eligible节点是最小配置,也是目前业界标配。
Elasticsearch以REST API形式对外提供服务,数据写入与查询都会发送HTTP(S)请求到服务端,由负载均衡将请求分发到集群中的某个节点上(任何非dedicated master-eligible节点)。如下图所示,节点1收到请求后,会根据相关的元信息将请求分发到shard所在的节点(2和3)上进行处理,处理完成后,节点2和3会将结果返回给节点1,由节点1合并整理后返回给客户端。这里的节点1扮演着协调者的角色,称为coordinate节点,任何节点在收到请求后就开始发挥协调者的角色,直到请求结束。在实际使用中,可以根据需要增加一些专用的coordinate节点,用于性能调优。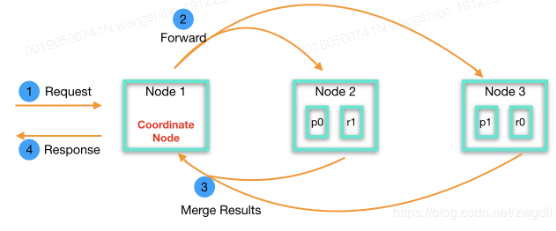
四、Elasticsearch数据写入
通过上面的整理可知,Elasticsearch数据写入的大致过程为:当有数据写入时,请求会先到达集群中的某个节点上,由该节点根据routing信息和元信息将相应的数据分发到对应的shard所在的节点上,可能是一个也可能是多个节点,取决于写入的数据。这些节点在收到分发出来的请求后,会经过一系列过程,最终将数据以segment的形式落地到磁盘上。
Elasticsearch数据写入过程包含同步与异步两个过程,如下图所示:
同步过程:是指在请求返回前做的事情,即包含在一个HTTP请求的过程中,客户端需要等其做完才能拿到结果。简单来看,这个过程需要完成三件事:第一,将操作记录写入到translog中,我们后面再来谈它的作用;第二,根据数据生成相应的数据结构,并写入到in-memory buffer,注意是写入到一个内存buffer中,不是磁盘;第三,将数据同步到所有replica shard中。完成这些之后,就会生成相应的结果返回给coordinate节点了。
异步过程:一般来说,写磁盘很慢,且非常耗费CPU与IO,在同步过程中,为了让请求尽快返回,并没有将数据直接落盘。Elasticsearch的最小数据单元是segment,而此时数据还在in-memory buffer中,因此这部分数据是不能被查询请求访问到的。只有当发生refresh动作,才会产生一个新的segment,将内存buffer中的数据写入到里面,同时清空buffer。默认refresh的时间间隔是1秒,可以配置,需要在实时性与性能之间进行权衡。此时虽然已经生成了新的segment文件,但是只是停留在filesystem cache中,并没有真正的落到磁盘中。这些动作的目的都是为了将"写磁盘"这件事尽可能的延后并变得低频,但是数据一直留在内存中始终是不安全的,很容易因为断电等原因导致数据丢失,因此每隔一段时间,Elasticsearch会真正做一次磁盘flush,完成数据的持久化。从写入请求过来到数据最终落盘,中间很长一段时间数据是停留在内存中的,那么如果在此期间机器断电岂不是会丢失数据?为了解决这个问题,就要用到上面所述的translog了。在请求返回前,必须要将操作记录写入到translog中并落盘,保证机器重启后可以恢复数据。显然这件事本身是会消耗性能的,但这也是保证数据不丢失的一个牺牲了,必须要做的。
segment是由refresh动作产生的,因此随着时间推移,会产生很多小segment,而每个segment都需要占用一定的资源,比如文件句柄、缓存等等,过多的segment势必会导致性能下降。因此每隔一段时间,Elasticsearch会做一次segment merge,将多个小的segment合并成一个大的segment。
最后再来看下前面提到的一个问题:因为segment是不可改变的,如何实现数据更新与删除?以删除为例,Elasticsearch将要删除的数据记录到一个叫.del文件中,每次查询时会将匹配到的数据跟这个文件中的数据做一次对比,去掉被删除的数据。直到segment merge时,会将.del文件和相应的segment文件一起加载进行合并,这时才真正删除了数据。

五、Elasticsearch存储结构
在介绍Elasticsearch存储结构之前,先来看看两种常见的查询需求:一种是精确匹配,比如查找作者姓名为"Bruce"的信息;另一种是全文检索,比如从1000个文章的标题中搜索出包含"分布式"的文章。对于第一个需求,只需要将每个名字作为一个term即可,"是"或"不是";对于第二个,如果想知道标题中是否包含"分布式",就需要提前将每个标题分解为多个term,比如"浅谈分布式存储系统",可能会产生"浅谈"、"分布式"、"存储"、"系统"等多个term,具体取决于使用了哪一种分析器。
不管哪种情况,最后都是产生一组term,问题是用一个什么样的存储结构可以实现快速检索。这就是Elasticsearch的核心:inverted index。inverted index是一个二维结构,如下所示,包含一组排好序的term,每个term都关联有一些信息,这些信息指出哪些document包含了这个term。当需要查询包含关键词"分布式"的数据时,系统会先从inverted index中找出对应的term,获取到其对应的document id,然后就可以根据document id找出其信息了。
sample data:
1. {"author": "Bruce", "title": "浅谈分布式存储系统"}
2. {"author": "Bruce", "title": "常见的分布式系统"}
3. {"author": "David", "title": "分布式存储原理"}
inverted index for field "author":
-------------------------------
term | doc id
-------------------------------
Bruce | 1, 2
David | 3
-------------------------------
inverted index for field "title":
-------------------------------
term | doc id
-------------------------------
常见 | 3
存储 | 1, 3
分布式 | 1, 2, 3
浅谈 | 1
系统 | 1, 2
原理 | 3
-------------------------------
通过inverted index,就可以根据关键词快速搜索出相关的document。除了这种查询,还有一种常见的需求是求聚合,即关系型数据库中的GROUP BY功能。比如查看写"分布式"相关的文章最多的10位作者,首先根据上述方法通过inverted index找到与"分布式"相关的所有document,然后需要对这些document的作者进行归类并计数,最后再排序取出TOP10。在"归类"时,我们需要知道每个document的作者名字,但是通过inverted index是无法直接查找到的,因为他是term-to-doc_id形式的,而我们这里需要的是doc_id-to-term形式的数据,只有通过循环迭代才能知道某个document的作者姓名是什么,这样做的效率无疑是很低的。
为了解决聚合的效率问题,Elasticsearch建立了一个与inverted index反向的数据结构:doc values,如下所示:
------------------------------- doc id | terms ------------------------------- 1 | Bruce 2 | Bruce 3 | David -------------------------------
inverted index和doc values都是在数据写入时建立的,即上述的同步过程第二步中完成的。它们都是针对per segment而言的,数据最终以文件的形式存储,并且是immutable不可改变的。数据查询时,如果每次都去读取磁盘文件,其效率显然是无法接受的,Elasticsearch将这些文件内容映射到内存中,通过充分利用文件系统缓存来提高查询性能,因此在实践中建议保留足够的memory给系统。
六、Elasticsearch重要配置说明
elasticsearch的基础配置信息在elasticsearch.yml中,下面列出一些重要的配置:
1. 集群名称
默认情况下elasticsearch的集群名称是elasticsearch,在实际应用中应该设置一个有意义的集群名称:
cluster.name: elasticsearch-cluster-demo
2. 节点信息
elasticsearch节点是elasticsearch集群中的某一个节点,可由基本的三个信息描述,节点名称(node.name),是否为主节点(node.master),是否为数据节点(node.data)。默认情况下,节点名称在每次启动的时候会随机生成,所以应该为节点设置一个有意义的名称,以方便排查问题。而节点又分为主节点、数据节点、客户端节点、部落节点,下面是一个节点(只为主节点)的配置样例:
node.name: node-master-one node.master: true node.data: false
3. 数据存储路径/日志路径
默认情况下,elasticsearch数据和日志的存储路径是在安装目录下,为了防止被误删掉,应该重新设置路径。配置样例如下:
# Path to directory where to store the data (separate multiple locations by comma): # es data 存储路径(多个路径可用','隔开) path.data: /data/elasticsearch-cluster/elasticsearch-master-one/data # # Path to log files: # log存储路径 path.logs: /data/elasticsearch-cluster/elasticsearch-master-one/logs
4. 网络绑定监听
在搭建elasticsearch的时候,也应该去修改其监听的主机IP,至于端口可以用默认的:
# Set the bind address to a specific IP (IPv4 or IPv6): # 网路监听 network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300
5. 最小主节点数
如果是搭建elasticsearch集群,那么应该设置最小主节点这个设置,以便防止脑裂现象:多个主节点同时存在与一个集群(一个集群只允许有一个主节点)。集群的主节点是集群的最高统治者,控制着索引的创建和分片的移动策略等;如果一个集群出现多个主节点,那么就好比一个团队出现两个leader一样,原本的一个整体被划分,对于elasticsearch集群来讲就是原本的分片(数据)被分开,这样数据就可能出现不完整性。
集群的主节点是靠所有有资格竞选主节点的节点(即节点信息设置node.master为true)投票选举出来的,所以现在获得的投票数量应该大于总票数半。所以在elasticsearch中,是设定当候选的master节点达到设定的法定个数的时候才进行主节点选举:法定个数 = master-eligible nodes / 2 + 1
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # 最小主节点个数 discovery.zen.minimum_master_nodes: 2
因为elasticsearch节点是可以动态删除和添加的,所以这个设置是可以通过API动态设置的。
6. 集群恢复
elasticsearch集群在启动的时候,会做数据平衡操作。比如,一个10个节点5/1分片策略(5个分片,5个副本分片)的集群,平衡下来是每个节点一个分片,如果集群在重启的时候,有5个节点因为网络原因一段时间内未启动成功,可能会出现一种情况:启动的5个节点中有3个主分片,2个副分片。这时候就会出现主分片数据不完整和不均匀分布,此时集群会自动做数据的平衡操作。若一段时间后,另外的5个节点重新上线了,发现本身的数据在集群中已存在,则又会做平衡操作。这样,两次数据平衡移动操作,会占用磁盘和带宽,若数据量大则影响可想而知。所以可以做如下控制,来保障集群重启时数据恢复花费时间尽可能短:
1)设置集群可提供服务的条件:最小上线节点数
gateway.recover_after_nodes: 8
2)设置集群数据恢复条件:等待多少分钟,或这有多少个节点上线(具体取决与条件的先达性)
gateway.expected_nodes: 10 gateway.recover_after_time: 5m
7. 集群节点发现
使用单播方式,为节点提供其应该去尝试连接的节点列表,连接成功,得到集群的状态信息,便加入集群。节点列表中可以不是全部节点,只要能保障能进入集群即可(可以选用部分候选主节点)。
# Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # 候选主节点ip:port discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"]
8. 推迟分片分配
elasticsearch集群在运行的时候,当有节点加入或离开的时候,会进行分片均衡操作,这个过程有些像集群重启时的数据恢复过程,可能会导致出现多次分片在均衡的过程,所以需要设置延迟分片分配,以尽量避免该情形出现。
# 延迟5min delayed_timeout: 5m
该设置同样可以通过API的形式动态设置。
9. 禁止内存交换
内存交换会影响性能,elasticsearch官方推荐允许JVM锁住内存,禁止出现内存交换的情况:
bootstrap.mlockall: true
10. 其他配置
1)Elasticsearch JVM内存
elasticsearch默认的安装内存是1g,这个可以根据需要来设置,在elasticsearch的config目录中的jvm.options中:
# Xms represents the initial size of total heap space # Xmx represents the maximum size of total heap space -Xms1g -Xmx1g
当然,这个内存不是随便设置的,推荐的是最大值和最小值一样,以避免堆内存改变时浪费系统资源。其次是即便硬件资源足购大,也不要分配超过32G(具体原因可参考Elasticsearch权威指南:不要超过32GB),可以多给底层lucenen多分点。
2)文件描述符和MMap内存映射
elasticsearch在节点在通信时会产生大量套接字,以及elasticsearch底层的lucene使用了大量文件,所以需要足够的文件描述符,而linux中一般都是做有限制的,所以应该修改为大一点的值。可以修改文件/etc/security/limits.conf,添加如下配置,配置值设为需要的值即可:
#<domain> <type> <item> <value> #四个元素的意义在该文件中均有详细描述 elasticsearch soft nofile 65536 elasticsearch hard nofile 65536
elasticsearch对文件混合使用了NioFs(非阻塞文件系统)和 MMapFs ( 内存映射文件系统),所以要保障有足够的虚拟内存用于映射。可以直接修改/etc/sysctl.conf文件添加如下配置,配置值设为需要的值。下面内容添加到sysctl.conf文件中后,执行"sysctl -p"命令使配置生效即可。
vm.max_map_count=655360
这两项如果在启动elasticsearch之前不进行设置的话,在启动elasticsearch的时候也可能会直接报相关的error以致无法启动成功。
3)GC配置和线程池
这两个配置,es官方强烈建议不要做修改,具体原因可参考:Elasticsearch权威指南:不要触碰这些配置
七、Elasticsearch集群异常分析
随着业务的增长与发展,不同的Elasticsearch集群承担着多厚多样的功能需求。尤其是当集群规模增长、业务庞大时,需要耗费大量的精力运维集群。最坏的情况,Elasticsearch集群崩溃,无法正常承担各项业务。导致ES集群崩溃的大多数原因是master节点、数据节点的宕机。下面总结节点:
1. 节点负载过高,导致节点失联
以Elasticsearch集群的数据节点与master节点为例,当有任何一个节点负载过高,都可能导致单节点宕机从而挑战集群的可用性。master节点负载高会严重影响到集群稳定性,可能发生master漂移,节点上下线,分片丢失,负载增高,甚至阻塞读写等。
应对措施:可以确认下是否有大量频繁的修改,创建,删除索引操作,并尽量避免这种行为。可以考虑使用更高配置的节点用增加系统高稳定性。因此,我们需要检测过去一段时间内Elasticsearch节点负载情况(脚本方式等),提前获知并拯救集群于崩溃边缘。
2. 索引副本丢失,数据可靠性受损
索引的副本一方面是保证数据的可靠性,保证在数据丢失的状态下依旧可以恢复如初;一方面副本数的增加可提高查询的性能。在存储空间占用过满时,极有可能导致索引副本丢失。因此检查副本的存在状态,可帮助提高数据的可靠性。在Elasticsearch集群重启的过程中,只有在副本数量完整时才能保证服务的持续进行。
应对措施:监控Elasticsearch集群基本颜色状态,检查shard分片是否丢失。颜色不正常的索引会影响数据读写。索引副本丢失(YELLOW)会影响到数据的可靠性和读写性能;索引主分片丢失(RED)会导致数据丢失。所以要极度重视和关注Elasticsearch集群颜色状态的监控,遇到异常,及时处理!
3. 数据写入失败,集群压力过大
在写操作进行的过程中,可能会因Elasticsearch集群压力,导致读写任务堆积过多。如果在此情况下继续增加写入,则可能会引起集群的崩溃。检查集群写数据是否有堆积,如果写入存在堆积,则会造成RulkReject异常,可能会导致数据丢失,且会造成系统资源消耗严重。
应对措施:通过调用线程池查看实际成功、失败任务情况,使用分批写入的方式解决写入堆积困境,给集群减压。可以通过ES_API查看队列情况,GET _cat/thread_pool/bulk?v,建议增加更多的数据解读或降低bulk写入频率和大小。
八、Elasticsearch集群性能提升
如何在固定配置的情况下更大程度发挥集群可用性能,是我们最关心的问题。从Elasticsearch内部逻辑与架构,数据节点是任务载体与执行依托,shard是索引与搜索的主要承担者,副本是提升性能的重要抓手,分批写入与防止稀疏是必备方式。如何提升集群性能,下面从数据节点负载、shard合理性两方面简单做下说明。
1. 数据节点抓偏离,防止单节点瓶颈
在各数据节点负载均衡的条件下,性能会趋向于最优的实践。如果发生单节点负载过高,与其他节点产生较大差异,则高负载节点可能成为"拖油瓶",拉低整体集群数据节点任务执行,甚至存在脱离集群的风险。监控Elasticsearch集群当天的节点负载偏差是否过大,节点间负载不一致会使得某个节点成为系统瓶颈,影响集群稳定性。应尝试调整shard分片数或数据节点数,尽可能保证两者均衡。
2. shard、segment合理性评估,升性能调负载
不同的Elasticsearch集群应用场景对性能承载着不同的需求。索引的载体就是shard,搜索结果的返回也是多个shard共同的返回结果。Shard数与节点间的负载均衡、查询性能和存储空间利用均有着非常重要的关系。shard数和大小不合理会极大的影响索引读写性能,shatd过少会影响索引读写性能,shard过多会占用较多系统资源。通过读取索引shard、节点shard,检查判断是否因索引segment过多导致碎片化,引发离线数据写入过慢,从而在适当的时间执行段合并操作,即调整部分索引的shard数,提升离线数据的写入速度,均衡负责,提升性能,节省空间。