网络IO
Linux 的内核将所有外部设备都看做一个文件来操作(一切皆文件),对一个文件的读写操作会调用内核提供的系统命令,返回一个file descriptor(fd,文件描述符)。而对一个socket的读写也会有响应的描述符,称为socket fd(socket文件描述符),描述符就是一个数字,指向内核中的一个结构体(文件路径,数据区等一些属性)。
I/O模型
根据UNIX网络编程对I/O模型的分类,UNIX提供了5种I/O模型。
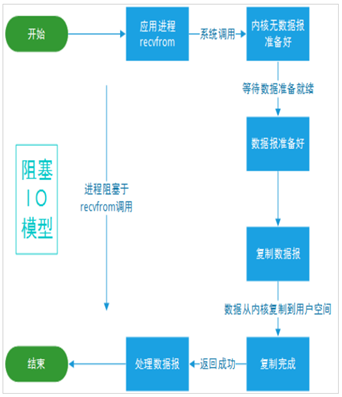
阻塞I/O模型
最常用的I/O模型,默认情况下,所有文件操作都是阻塞的。
比如I/O模型下的套接字接口:在进程空间中调用recvfrom,其系统调用直到数据包到达且被复制到应用进程的缓冲区中或者发生错误时才返回,在此期间一直等待。
进程在调用recvfrom开始到它返回的整段时间内都是被阻塞的,所以叫阻塞I/O模型。
图示:
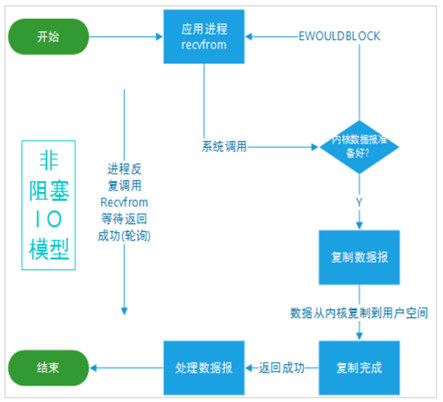
非阻塞I/O模型
recvfrom从应用层到内核的时候,就直接返回一个EWOULDBLOCK错误,一般都对非阻塞I/O模型进行轮询检查这个状态,看内核是不是有数据到来。
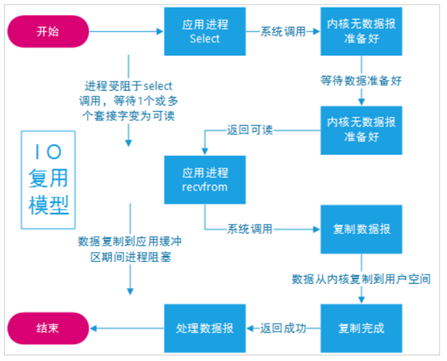
I/O复用模型
Linux提供select/poll,进程通过将一个或多个fd传递给select或poll系统调用,阻塞在select操作上,这样,select/poll可以帮我们侦测多个fd是否处于就绪状态。
select/poll是顺序扫描fd是否就绪,而且支持的fd数量有限,因此它的使用受到了一些制约。
Linux还提供一个epoll系统调用,epoll使用基于事件驱动方式代替顺序扫描,因此性能更高。当有fd就绪时,立即回调函数rollback。
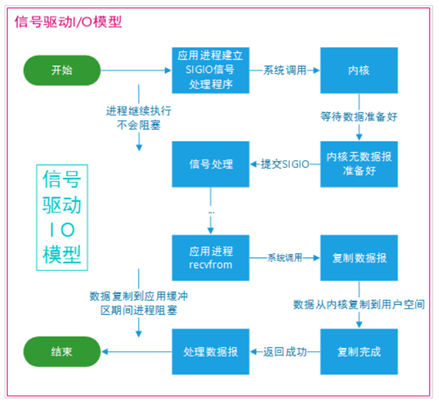
信号驱动I/O模型
首先开启套接口信号驱动I/O功能,并通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,非阻塞)。当数据准备就绪时,就为改进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知主循环函数处理树立。
异步I/O
告知内核启动某个操作,并让内核在整个操作完成后(包括数据的复制)通知进程。
信号驱动I/O模型通知的是何时可以开始一个I/O操作,异步I/O模型有内核通知I/O操作何时已经完成。
图示:

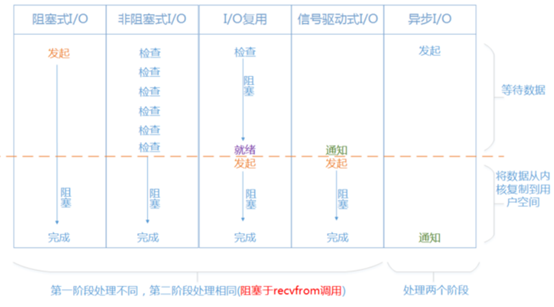 这张图可以看出阻塞式I/O、非阻塞式I/O、I/O复用、信号驱动式I/O他们的第二阶段都相同,也就是都会阻塞到recvfrom调用上面就是图中"发起"的动作。异步式I/O两个阶段都要处理。这里我们重点对比阻塞式I/O(也就是我们常说的传统的BIO)和I/O复用之间的区别。
这张图可以看出阻塞式I/O、非阻塞式I/O、I/O复用、信号驱动式I/O他们的第二阶段都相同,也就是都会阻塞到recvfrom调用上面就是图中"发起"的动作。异步式I/O两个阶段都要处理。这里我们重点对比阻塞式I/O(也就是我们常说的传统的BIO)和I/O复用之间的区别。
阻塞式I/O和I/O复用,两个阶段都阻塞,那区别在哪里呢?就在于第三节讲述的Selector,虽然第一阶段都是阻塞,但是阻塞式I/O如果要接收更多的连接,就必须创建更多的线程。I/O复用模式下在第一个阶段大量的连接统统都可以过来直接注册到Selector复用器上面,同时只要单个或者少量的线程来循环处理这些连接事件就可以了,一旦达到"就绪"的条件,就可以立即执行真正的I/O操作。这就是I/O复用与传统的阻塞式I/O最大的不同。也正是I/O复用的精髓所在。
I/O多路复用技术
I/O编程中,需要处理多个客户端接入请求时,可以利用多线程或者I/O多路复用技术进行处理。
正如前面的简介,I/O多路复用技术通过把多个I/O的阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。
与传统的多线程模型相比,I/O多路复用的最大优势就是系统开销小,系统不需要创建新的额外线程,也不需要维护这些线程的运行,降低了系统的维护工作量,节省了系统资源。
主要的应用场景:
- 服务器需要同时处理多个处于监听状态或多个连接状态的套接字。
- 服务器需要同时处理多种网络协议的套接字。
支持I/O多路复用的系统调用主要有select、pselect、poll、epoll。
而当前推荐使用的是epoll,优势如下:
- 支持一个进程打开的socket fd不受限制。
- I/O效率不会随着fd数目的增加而线性下将。
- 使用mmap加速内核与用户空间的消息传递。
- epoll拥有更加简单的API。
select/poll/epoll 都是 I/O 多路复用的具体实现,select 出现的最早,之后是 poll,再是 epoll。
select 和 poll 的功能基本相同,不过在一些实现细节上有所不同。
- select 会修改描述符,而 poll 不会;
- select 的描述符类型使用数组实现,FD_SETSIZE 大小默认为 1024,因此默认只能监听 1024 个描述符。如果要监听更多描述符的话,需要修改 FD_SETSIZE 之后重新编译;而 poll 的描述符类型使用链表实现,没有描述符数量的限制;
- poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
- 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定。
select 和 poll 速度都比较慢。
- select 和 poll 每次调用都需要将全部描述符从应用进程缓冲区复制到内核缓冲区。
- select 和 poll 的返回结果中没有声明哪些描述符已经准备好,所以如果返回值大于 0 时,应用进程都需要使用轮询的方式来找到 I/O 完成的描述符。
epoll
epoll_ctl()用于向内核注册新的描述符或者改变某个文件描述符状态。已注册的描述符在内核中会被维护在一颗红黑树上,通过回调函数内核会将I/O准备好的描述符加入到一个链表中管理,进程调用epoll_wait()便可以得到事件完成的描述符。
应用场景
很容易产生一种错觉认为只要epoll就可以了,select和poll都已经过时了,其实它们都有各自的使用场景。
select应用场景
select的timeout参数精度为1ns,因此select更加适用于实时性要求比较高的场景,比如核反应堆的控制。
select可移植性更好,几乎被所有主流平台所支持。
poll应用场景
poll没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用poll而不是select。
epoll应用场景
只需要运行在Linux平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
需要同时监控小于1000个描述符,就没有必要使用epoll。因为epoll中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过epoll_ctl()进行系统调用,频繁系统调用降低效率。并且epoll的描述符存储在内核,不容易调试。