汽车在道路上行驶需要遵循一定的行驶规则,路面的车道则起到规范汽车行驶规则的作用。车道的种类有很多种,如单行线、双行线,虚线、网格线等,不同颜色、形状的车道线代表着不同的行驶规则,汽车和行人可以根据这些规则来使用道路,避免冲突。因此,准确检测并识别车道类型,并按照相应规则正确行驶,是汽车实现自动驾驶的基础。
优达学城的自动驾驶项目课程包含了一个车道线检测项目,其主要目的就是教给无人车如何检测并识别车道,本文档将该项目内容进行总结整理。
车道线检测方法主要分为两类:(1)基于道路特征的车道线检测;(2)基于道路模型车道线检测。基于道路特征的车道线检测作为主流检测方法之一,主要是利用车道线与道路环境的物理特征差异进行图像的分割与处理,从而突出车道线特征,以实现车道线的检测。该方法复杂度较低,实时性较高,但容易受到道路环境干扰。基于道路模型的车道线检测主要是基于不同的二维或三维道路图像模型(如直线型、抛物线型、样条曲线型、组合模型等),采用相应方法确定各模型参数,然后进行车道线拟合。该方法对特定道路的检测具有较高的准确度,但局限性强、运算量大、实时性较差。
本项目采用的是基于道路灰度特征的车道线检测方法。主要流程如下:
(1)灰度图像转换
自动驾驶车载摄像头实时拍摄的照片为RGB格式,为了能够提取其灰度特征,首先要将3通道的RGB图形转换为单通道的gray图。这里可以借助python中的opencv工具包来实现这一转换。采用的代码如下:
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
其中,image是摄像机采集的RGB原始图像(左图),image_gray是转换后的灰度图像(右图)。

(2)边缘提取
完成RGB图形和灰度图的转换之后,图片在计算机中被看作是一组由像素值组成的矩阵,像素值是介于0~255之间的数据,其中0代表图片中的纯黑色,255代表纯白色。但是,这样的数据组不能被计算机理解,接下来需要进行图形的边缘提取。
对图形进行边缘提取的目的是找出图形中的各物体的轮廓特征。本项目采用canny边缘检测技术来完成图形的边缘提取,该方法的主要流程图如下:
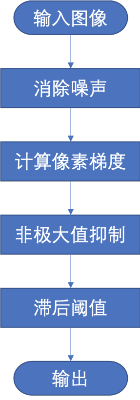
其中,消除噪声模块主要用于去除图形中的噪点,避免噪点被识别为轮廓;计算像素梯度为canny算法的核心,通过计算各处的梯度值来判读图形中颜色的变化;通过非极大值抑制则可以去除虚假的边缘点,而只保留最可能成为边缘的像素点;最后通过设置双滞后阈值来去除伪边缘,进一步增强车道检测的准确性。 下图是完成边缘提取之后的图形,可以看出图形中的物体轮廓及线条都已经被刻画出来,只保留线条的图形看上去更加简洁,也更容易被计算机识别。

(3)划定region of interest(roi)
虽然原图像中的线条及物体轮廓已经描绘出来了,但是我们始终要记得项目的目的:检测车道线!
也就是说,图形中除了车道线以外的部分都不是我们感兴趣的目标。在进行下一步之前,我们可以通过划定感兴趣领域(roi)来简化图形。
这里问题来了:划定感兴趣领域是必须的吗?答案是否定的,即使我们不进行这一步操作依然能实现最终的目标,但是通过划定roi,我们可以大大缩减图形中的线条数量,从而使接下来的计算量大大减小;此外,把无关内容抛弃掉之后,我们同样也就减小了了计算机出现错误的可能性。
另外一个问题是:如何选择roi?
这个问题其实是没有固定答案的,例如在本项目中,我们假定汽车采集图像用的摄像头是安装在汽车的正前方的,大部分情况下汽车在道路上行驶于两条相邻的车道线中间(除非需要变道行驶),因此我们可以认为只需在图形的中间选定一块区域即可。
roi的形状不是固定的,根据实际需求的不同,可以选择三角形、矩形框、圆形、椭圆形、不规则多边形等等。这里为了简单,采用了三角形。三角形在原图中的位置可以参照下图:

三角形的大小是可以调整的。
划定好roi之后,可以编写rigion_of_interest函数,将roi之外的线条去掉,只保留roi内部的线条。由于摄像头拍出来的车道线有透视效应,因此形状类似于三角形,因此可以用三角形作为roi。最终得到的过滤后的图形为:

可以看到图形得到大大精简,只保留了部分车道线,远方物体的轮廓线没有被保留。
(4)Hough变换
至此,汽车摄像机拍到的原始RGB图形已经逐步被简化为只保留车道线的图形,看上去我们的工作已经完成。这里还有一个问题需要提及,计算机可以通过比较像素值识别图形中的白色点,然后计算线条的斜率来绘制图形。然而,如果存在一条车道线与水平方向垂直,那么这时候线条的斜率趋近于无穷大,这中特殊情况计算机是无法处理的。
为了解决这一问题,需要对图片进行霍夫变换(Hough Transform)。霍夫变换的原理这里不再赘述,读者可以在网上查阅相关资料。总之,霍夫变换主要解决车道线斜率无穷大的情况。在python的霍夫变换opencv模块中,有函数可以直接完成图形的霍夫变换,函数调用代码如下:
img_hough = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength,maxLineGap)
函数的参数中,img为需要进行霍夫变换的图形;rho和theta分别为距离和角度的分辨率;阈值threshold控制将一条线判定为直线的最少点数;minLineLength为将一条线识别为直线的最低长度,即只有线条长度大于该值时才将线条标记出来;maxLineGap则为线段上两点之间的最大阈值,如果两点之间的距离大于该值,则认为两点不属于同一条直线。经过霍夫变换后,得到的图形为:

由于在本例中不存在车道线斜率无穷大的情况,因此变换前后的图形无差别。为了强行加以区分,这里把原来的白色改为了蓝色。
(5)画车道线
现在,图形中的车道线已经被识别出来,接下来只需要将车道线刻画在原图上,以便于检查识别效果即可。

可以看到,在原图中的车道线已经被识别出来,且效果非常好!
由于划定了roi,远处的车道线没有别标记出来。但是不用担心,汽车在行驶过程中,车道线是实时识别的,因此可以通过不断更新将远处的车道线识别出来。 为了进一步验证使用该方法进行车道检测的效果,我们重新选择一张图看看效果:

通过这一实例可以验证,该方法可以比较完美的检测车道线。(左右两幅图色调有所不同,这是由于图像读取函数造成的。)
**************************************** 分割线 ****************************************
>>>>>>视频检测
以上部分是对单张图片进行车道检测的方法。在实际应用中,需要在汽车行驶过程中进行实时车道检测,从而避免汽车偏离车道。此时汽车摄像机采集到的信息往往以视频的形式呈现,因此需要在视频中识别出车道线。这听上去好像有点复杂,不过我们完全不用担心,因为摄像头采集到的视频本质上就是多张图片的叠加,因此只需要对视频进行分割,将单位时间内的视频分为多张图片的叠加,然后将每张图片分别按照上述方法进行车道检测,最后将结果再重新叠加为视频即可。
当然,对于不懂视频编辑的新手来说,怎样才能将一段视频分割为图片,然后再合成视频呢?这里不得不夸一下强大的python,python已经提前准备好了VideoFileClip工具,只需按规则调用相关函数,即可完成图片的提取与视频的合成。然后采用图片车道线提取方法,对各张图片进行处理即可。下面的代码中,example1_output是在我的电脑上存储处理后视频的地址;clip1后面的地址是待处理的视频的地址。
example1_output = '.../test_videos_output/solidWhiteRight1.mp4' clip1 = VideoFileClip(".../test_videos/solidWhiteRight.mp4") print clip1 example1_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!! %time example1_clip.write_videofile(example1_output, audio=False)
>>>>>>视频检测结果展示
处理后的视频为本文件夹中的solidWhiteRight_output.mp4文件。可以看到,视频处理结果令人满意,道路左右两侧的实线和虚线均被检测出来。
**************************************** 分割线 ****************************************
本项目中还提供了另外一段由汽车前置摄像头采集到的视频,并命名为challenge.mp4(可在本文件夹中查找)。这段视频中路面存在阴影及破损的情况,给道路线检测带来干扰。采用上述方法,对该视频进行处理,处理结果可查看文件challenge——output.mp4。从视频中可以看出,在第3-6秒钟的时间区间内,道路线检测结果非常不理想,主要表现为:
(1)错误的将树枝阴影识别为道路线;
(2)将汽车前沿识别为道路线;
(3)在道路有破损的路面上,无法识别出道路线。这些问题会严重影响自动驾驶汽车的行驶,因此需要想办法加以改进。
>>>>>>改进方法
(1)增大Canny函数的阈值
python中调用Canny函数需要输入一大一小两个阈值,当某一像素点的梯度值小于较小阈值时,该像素点被剔除;当梯度值大于较大阈值时,像素点被保留;梯度值位于两个阈值之间时,另行考虑。因此,这里同时增大两个阈值的值,可以将梯度较小的像素点去除,从而排除掉树枝在地上的阴影(因为这些阴影的梯度值往往小于车道线的梯度值)。
(2)将黄线转换为白线
在道路破损部分,车道线无法识别的原因是黄色的车道线与路面颜色对比不明显,即车道线上的像素点梯度值不够大导致被剔除。为了解决该问题,这里首先通过编写函数将黄色的线转换为白色的线,来提高车道线上像素点的梯度值,从而提高像素点被识别的概率。函数代码如下:
def yellow_transform(image): image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) lower_yellow = np.array([40, 100, 20]) upper_yellow = np.array([100, 255, 255]) mask = cv2.inRange(image_hsv, lower_yellow, upper_yellow) return mask
>>>>>>结果验证
改进之后,我们在文件名文challenge.mp4的视频上进行验证,为了使效果更加明显,这里对原视频进行处理,使其更暗从而使检测出的车道线更容易在图上观察到。
最后的结果为本文件夹中命名为challenge_output1.mp4的文件。
可以看出,经过改进之后,原来被错误的识别为车道线的树枝阴影大部分被忽略。在车道破损部分,有些车道线可以被检测出来。虽然结果依然不算完美,仍然存在很多问题,但是与原来的结果相比已经产生明显提升,因此可以认为我们的改进方法是有效的。但是改进之后的程序运算量会加大,运算时间也会延长,这就需要更快的设备来完成运算。这也是改进方法的弊端。
# coding:UTF-8 # importing some useful packages import matplotlib.pyplot as plt import matplotlib.image as mpimg import numpy as np import cv2 % matplotlib inline import math def region_of_interest(img, vertices): """ Applies an image mask. Only keeps the region of the image defined by the polygon formed from `vertices`. The rest of the image is set to black. `vertices` should be a numpy array of integer points. """ # defining a blank mask to start with mask = np.zeros_like(img) # defining a 3 channel or 1 channel color to fill the mask with depending on the input image if len(img.shape) > 2: channel_count = img.shape[2] # i.e. 3 or 4 depending on your image ignore_mask_color = (255,) * channel_count else: ignore_mask_color = 255 # filling pixels inside the polygon defined by "vertices" with the fill color cv2.fillPoly(mask, vertices, ignore_mask_color) # returning the image only where mask pixels are nonzero masked_image = cv2.bitwise_and(img, mask) return masked_image def draw_lines(img,lines,color,thickness): for line in lines: for x1,y1,x2,y2 in line: cv2.line(img,(x1,y1),(x2,y2),color,thickness) # 霍夫变换函数 def hough_lines(img): """ `img` should be the output of a Canny transform. Returns an image with hough lines drawn. """ rho = 2 theta = np.pi/180 threshold = 15 min_line_len = 60 max_line_gap = 30 lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]), minLineLength=min_line_len, maxLineGap=max_line_gap) line_img = np.zeros((img.shape[0], img.shape[1], 3), dtype=np.uint8) draw_lines(line_img, lines, [255,0,0], 2) cv2.imshow('hough_image',line_img) return lines,line_img def Lane_finding(image): image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) image_blur = cv2.GaussianBlur(image_gray, (5,5), 0) low_threshold = 50 high_threshold = 150 image_canny = cv2.Canny(image_blur, low_threshold, high_threshold) cv2.imshow('image_canny', image_canny) # 图像像素行数 rows = image_canny.shape[0] # 540行 # 图像像素列数 cols = image_canny.shape[1] # 960列 left_bottom = [0, rows] # [0,540] right_bottom = [cols, rows] # [960,540] apex = [cols / 2, rows*0.6] # [480,310] vertices = np.array([[left_bottom, right_bottom, apex]], np.int32) roi_image = region_of_interest(image_canny, vertices) cv2.imshow('roi_image', roi_image) lines,hough_image = hough_lines(roi_image) # 将得到线段绘制在原始图像上 line_image = np.copy(image) draw_lines(line_image, lines, [255, 0, 0], 2) # line_image = cv2.addWeighted(line_image, 0.8, hough_image, 1, 0) cv2.imshow('src', line_image) cv2.waitKey(0) return hough_image image = mpimg.imread("/Users/zhangzheng/Desktop/lane_lines_finding/test_images/solidYellowLeft.jpg") if __name__ == '__main__': Lane_finding(image)