预处理的几种方法:标准化、数据最大最小缩放处理、正则化、特征二值化和数据缺失值处理。
知识回顾:

p-范数:先算绝对值的p次方,再求和,再开p次方。
数据标准化:尽量将数据转化为均值为0,方差为1的数据,形如标准正态分布(高斯分布)。
标准化(Standardization)
公式为:(X-X_mean)/X_std 计算时对每个属性/每列分别进行。
将数据按其属性(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1。
sklearn中preprocessing库里面的scale函数使用方法:
sklearn.preprocessing.scale(X, axis=0, with_mean=True, with_std=True, copy=True)
根据参数不同,可以沿任意轴标准化数据集。
参数:
- X:数组或者矩阵
- axis:int类型,初始值为0,axis用来计算均值和标准方差。如果是0,则单独的标准化每个特征(列),如果是1,则标准化每个观测样本(行)。
- with_mean:boolean类型,默认为True,表示将数据均值规范到0。
- with_std:boolean类型,默认为True,表示将数据方差规范到1。
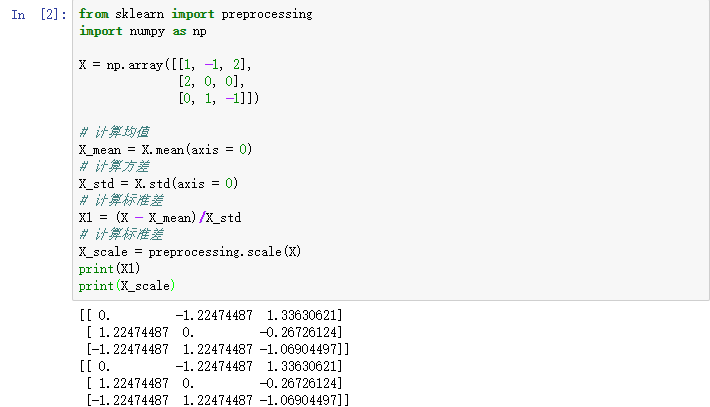
范例:假设现在构造一个数据集X,然后想要将其标准化。
方法一:使用sklearn.preprocessing.scale()函数
方法说明:
- X.mean(axis=0)用来计算数据X每个特征的均值;
- X.std(axis=0)用来计算数据X每个特征的方差;
- preprocessing.scale(X)直接标准化数据X。
方法二:sklearn.preprocessing.StandardScaler类
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
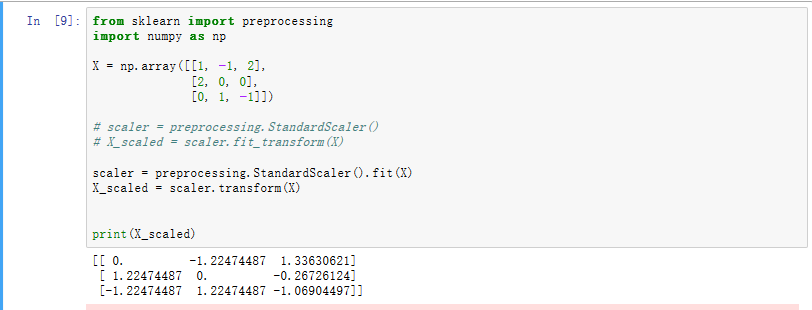
scaler = preprocessing.StandardScaler()
X_scaled = scaler.fit_transform(X)scaler = preprocessing.StandardScaler().fit(X)
X_scaled = scaler.transform(X)
上面两段代码等价。
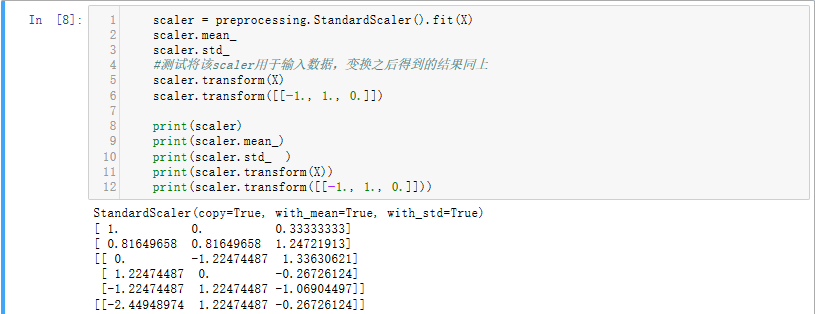
转换器(Transformer)主要有三个方法:
fit():训练算法,拟合数据
transform():标准化数据
fit_transform():先拟合数据,再标准化。