1. 数据缺失分为两种:行记录缺失,列记录缺失。
2. 不同的数据存储和环境对缺失值的表示也不同。例如:数据库中是Null,Python是None,Pandas或Numpy是NaN。
3. 对缺失值的处理通常4种方法:
(1). 丢弃
下面两种场景不宜采用该方法:
- 不完整数据比例较大,超过10%
- 缺失值存在明显的数据分布规律或特征
(2). 补全
常用补全方法:
- 统计法:对于数值型的数据,使用均值、加权均值、中位数等方法补足;对于分类型数据,使用类别众数最多的值补足。
- 模型法:基于已有的其他字段,将缺失字段作为目标变量进行预测,从而得到较为可能的补全值。如果带有缺失值的列是数值变量,采用回归模型补全;如果是分类变量,则采用分类模型补全。
- 专家补全:少量且具有重要意义的数据记录,专家补足也是非常重要的一种途径。
- 其他方法:随机发、特殊值法、多重填补等
(3). 真值转换法
(4). 不处理
常见能够自动处理缺失值模型包括:KNN、决策树和随机森林、神经网络和朴素贝叶斯、DBSCAN(基于密度的带有噪声的空间聚类)等。
处理思路:
- 忽略,缺失值不参与距离计算,例如:KNN。
- 将缺失值作为分布的一种状态,并参与到建模过程,例如:决策树以及变体。
- 不基于距离做计算,因此基于值得距离计算本身的影响就消除了,例如:DBSCAN。
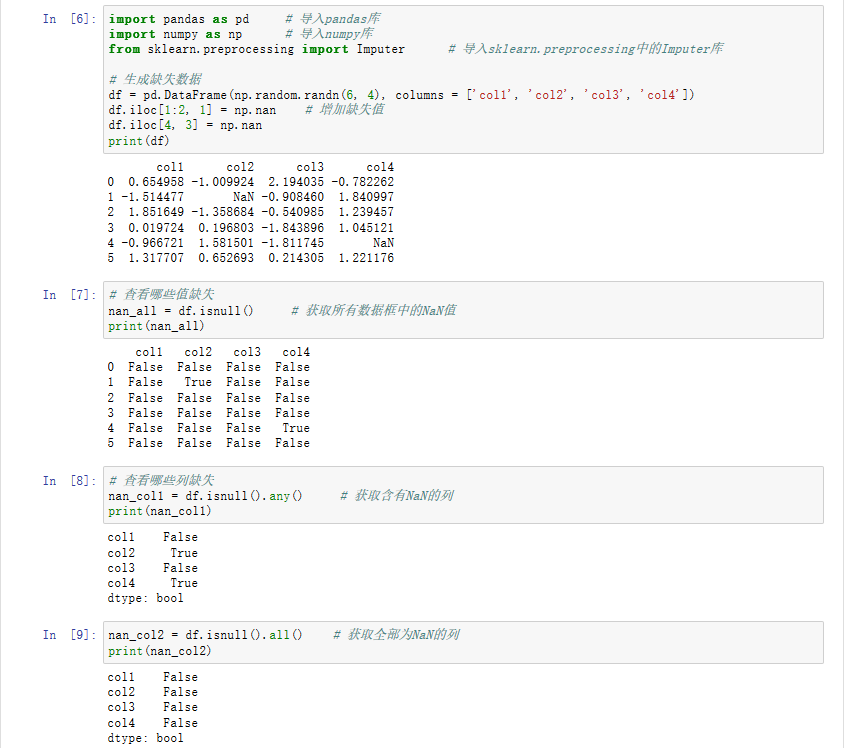
4. 对于缺失值的处理上,主要配合使用sklearn.preprocessing中的Imputer类、Pandas和Numpy。其中由于Pandas对于数据探索、分析和探查的支持较为良好,因此围绕Pandas的缺失值处理较为常用。
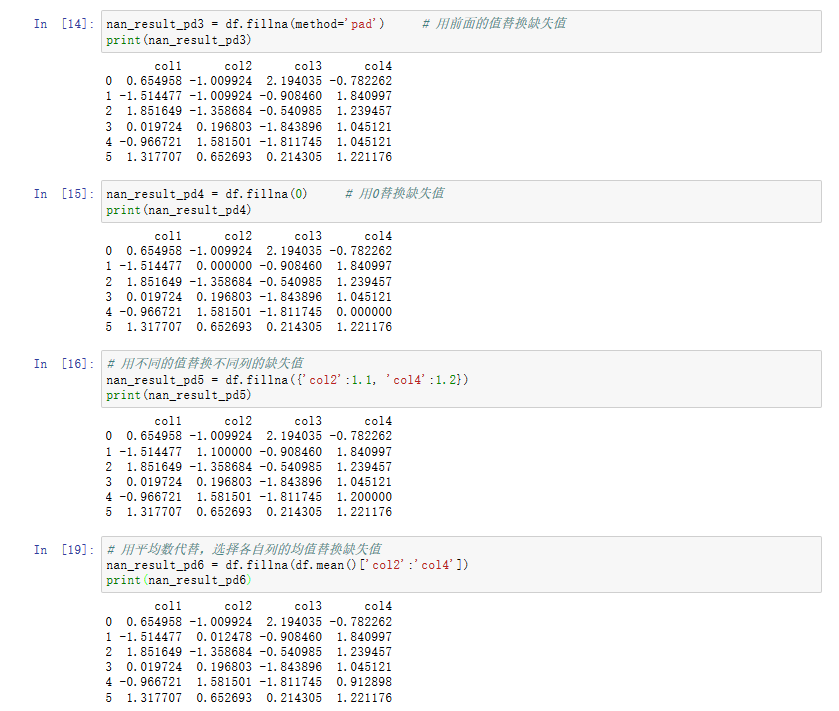
import pandas as pd # 导入pandas库 import numpy as np # 导入numpy库 from sklearn.preprocessing import Imputer # 导入sklearn.preprocessing中的Imputer库 # 生成缺失数据 df = pd.DataFrame(np.random.randn(6, 4), columns=['col1', 'col2','col3', 'col4']) # 生成一份数据 df.iloc[1:2, 1] = np.nan # 增加缺失值 df.iloc[4, 3] = np.nan # 增加缺失值 print (df) # 查看哪些值缺失 nan_all = df.isnull() # 获得所有数据框中的N值 print (nan_all) # 查看哪些列缺失 nan_col1 = df.isnull().any() # 获得含有NA的列 nan_col2 = df.isnull().all() # 获得全部为NA的列 print (nan_col1) print (nan_col2) # 缺失值审查 print('{:*^60}'.format('NA Cols:')) nan_cols = df.isnull().any(axis=0) # 查看每一列是否有缺失值 print(nan_cols) print('{:*^60}'.format('NA lines:')) nan_lines = df.isnull().any(axis=1) # 查看每一行是否有缺失值 print(nan_lines) print ('Total number of NA lines is: {0}'.format(nan_lines.sum())) # 查看具有缺失值的行总记录数 # 丢弃缺失值 df2 = df.dropna() # 直接丢弃含有NA的行记录 print (df2) # 使用sklearn将缺失值替换为特定值 nan_model = Imputer(missing_values='NaN', strategy='mean',axis=0) # 建立替换规则:将值为Nan的缺失值以均值做替换 nan_result = nan_model.fit_transform(df) # 应用模型规则 print (nan_result) # 使用pandas将缺失值替换为特定值 nan_result_pd1 = df.fillna(method='backfill') # 用后面的值替换缺失值 nan_result_pd2 = df.fillna(method='bfill', limit=1) # 用后面的值替代缺失值,限制每列只能替代一个缺失值 nan_result_pd3 = df.fillna(method='pad') # 用前面的值替换缺失值 nan_result_pd4 = df.fillna(0) # 用0替换缺失值 nan_result_pd5 = df.fillna({'col2': 1.1, 'col4': 1.2}) # 用不同值替换不同列的缺失值 nan_result_pd6 = df.fillna(df.mean()['col2':'col4']) # 用平均数代替,选择各自列的均值替换缺失值 # 打印输出 print (nan_result_pd1) print (nan_result_pd2) print (nan_result_pd3) print (nan_result_pd4) print (nan_result_pd5) print (nan_result_pd6)