0 集群的背景知识
详细见《数据密集型应用系统设计》第6章
0-1 分布式数据库系统特点
- 扩展性:当数据量或者读写负载巨大,严重超出了单台机器的处理上限,需要将负载分散
到多台机器上(负载均衡) - 容错与高可用性:当单台机器(或者多台,以及网络甚至整个数据中心)出现故障,还希望应用系
统可以继续工作,这时需要采用多台机器提供冗余。这样某些组件失效之后,冗余组件可以迅速接管。 - 延迟考虑:如果客户遍布世界各地,通常需要考虑在全球范围内部署服务,以方便用户就近
访问最近数据中心所提供的服务,从而避免数据请求跨越了半个地球才能到达目
标。
分布式数据库的2个特征:1)有无共享结构 2)数据复制与分区(分片)的实现机制。
- 分区的目标:将数据和查询负载均匀分布在所有节点上(扩展性)
- 复制的目标:延迟考虑,容错性,高性能
1)使数据在地理位置上更接近用户,从而降低访问延迟
2)当部分组件出现位障,系统依然可以继续工作,从而提高可用性。
3)扩展至多台机器以同时提供数据访问服务,从而提高读吞吐量。
Redis集群:1)采用无共享架构(水平扩展)2)官方的集群实现通过slots实现了数据分片。
- 数据的复制与分区是多节点情况下数据分布的二种机制,通常配合使用。
0-2 redis集群模式的必要性说明
redis单实例通过主从复制机制(replication)和哨兵(sentinel)系统提供的故障转移机制能够实现系统的高可用性,单个实例在海量用户的场景下仍然存在存储有限,流量压力上限的问题。(单个的master-slave存储有限,扩展性不够,必须提供横向扩展的机制实现)
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,对数据进行分片,也就是说每台 Redis 节点上存储不同的内容;
因此需要实现一种机制,能够:
- 保证数据分区
- 数据在各个主Master节点间不能混乱,当然最好还能支持在线数据热迁移的特性
0-3 分布式键-值数据库的数据分区方式
问题:数据分片不均匀会带来哪些问题?
数据分片不均匀会引发数据倾斜问题,倾斜会导致分区效率严重下降,在极端情况下,所有的负载可能会集中在一个分区节点上,系统的瓶颈在最繁忙的那个
节点上 。这种节点也被称之为系统热点。
- 避免热点最简单的方法是将记录随机分配给所有节点上。这种方法的缺点是当试图读取特定的数据时,无法知道数据保存
在哪个节点上,所以不得不并行查询所有节点,查询开销大。
方式1:基于关键字区间(key区间)的分区
基本思想:为每个分区(节点)分配一段连续的关键字或者关键字区间范围 ,根据每个节点分配的区间关键字的上下限,确定当前关键字是否在这个节点。
- 关键字的区间段不一定非要均匀分布,应该按照数据的分布,确保每个区间分配的数据规模接近。
- 每个分区内可以按照关键字排序保存 (对于一个保存网络传感器数据的应用系统,选择测量的时间戳(年月日时分秒)作为关键字,此时区间查询会
非常有用,它可以快速获得某个月份内的所有数据。 )
比如如果构建对英文单词按照首字母(key)进行分区,那么各个首字母开头的单词数量之间必定存在差异,此时可以为了让每个区间的单词数量相接近,区间段必定是不均匀。
采用这种分区策略的系统:Bigtable, Bigtable的开源版本HBase, RethinkDB和2.4版本之前MongoDB
基于关键字的区间分区的缺点: 某些访问模式会导致系统热点的出现,即数据倾斜问题
实例:例如每天一个分区。然而,当测量数据从传感器写入数据库时,所有的写入操作都集中在同一个分区(即当天的分区),这会导致该分
区在写入时负载过高,而其他分区始终处于空闲状态。
解决策略:为了避免上述问题,需要使用时间戳以外的其他内容作为关键字的第一项。例如,可以在时间戳前面加上传感器名称作为前缀,这样首先由传感器名称,然后按时间进行
分区。假设同时有许多传感器处于活动状态,则写入负载最终会比较均匀地分布在多个节点上。接下来,当需要获取一个时间范围内、多个传感器的数据时,可以根据传
感器名称,各自执行区间查询。
方式2:基于关键字hash值分区
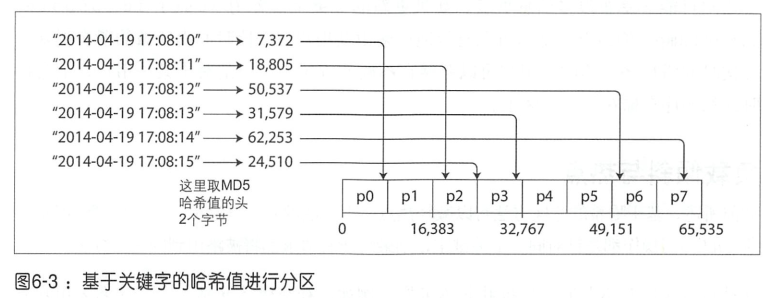
定义:利用关键字的hash值确定数据value存放的位置。
由于基于关键字区间的分区容易导致数据倾斜问题的发生,很多分布式系统采用基于关键字哈希函数的方式来分区
基于关键字进行数据分区的注意点:
- 这种方式hash函数的设计是非常关键的。好的哈希函数可以处理数据倾斜并使其均匀分布
例如一个处理字符串的32位哈希函数,当输入某个字符串,它会返回-个0和2^32~ l 之间近似随机分布的数值。即使输入的字符串非常相似,返回的哈希值也会在上述数字范围内均匀分布。
-
用于为关键字生成hash值的哈希函数不需要在加密方面很强,Cassandra和MongoDB使用MD5(MD5本质上就是一个产生128bit hash值的hash函数)
-
编程语言也有内置的简单哈希函数(主要用于哈希表),但是要注意这些内置的哈希函数不适合分区,例如Java的 Object.hashCode,原因在于同一个键在不 同的进程中可能返回不同的哈希值。
基于关键字的hash进行数据分区的优点: 能够较好的将关键字均匀地分配到多个分区中。分区边界可以是均匀间隔,也可以是伪随机选择(在这种情况下,该技术有时被称为一致性哈希 )
基于关键字的hash值进行数据分区的两个缺点:
- 通过关键字的hash值进行分区,相比较基于关键字区间分区的方式丧失了良好的区间查询特性。即使关键字相
邻,但经过哈希之后会分散在不同的分区中,区间查询就失去了原有关键字相邻的特性。
解决策略:在MongoDB中,如果启用了基于关键字hash值的数据分区,则区间查询会发送到所有的数据分区上,部分数据库如果启用基于关键字hash值的数据方式则直接不支持区间查询。
- 基于关键字hash值的的分区方法可以减轻系统热点问题,但无住做到完全避免。 一个极端情况是,所有的读/写操作都是针对同一个关键字,则最终所有请求都将被路由到同一个分区。
实例:社交媒体网站上,一些名人用户有数百万的粉丝,当其发布一些热点事件时可能会引发一场访问风暴[ 1 4],出现大量的
对相同关键字的写操作(其中关键字可能是名人的用户 ID ,或者人们正在评论的事件ID),此时,哈希起不到任何帮助作用,因为两个相同 ID 的哈希值仍然相同
解决策略:----只能通过应用层来减轻倾斜程度---。例如,如果某个关键字被确认为热点, 一个简单的技术就是在关键字的开头或结尾处添加一个随机数。只需一个两位数的十进制随机数就可以将关键字的写操作分布到 100个不同的关键字上,从而分配到不同的分区上。但是,随之而来的问题是,之后的任何读取都需要些额外的工作,必须从所有100个关键字中读取数据然后进行合井。因此通常只对少量的热点关键字附加随机数才有意义;而对于写入吞吐量低的绝大多数关键宇,这些都意味着不必要的开销。此外,还
需要额外的元数据来标记哪些关键字进行了特殊处理 。
知识点:关于加密算法与信息摘要算法的区分?
信息摘要算法(Message-Digest Algorithm):
The MD5 message-digest algorithm is a widely used hash function producing a 128-bit hash value. Although MD5 was initially designed to be used as a cryptographic hash function(加密hash函数), it has been found to suffer from extensive vulnerabilities.
应用:
1)It can still be used as a checksum to verify data integrity, but only against unintentional corruption.
2)It remains suitable for other non-cryptographic purposes, for example for determining the partition for a particular key in a partitioned database.[3]
知识点:数据分区使用的一致性hash算法(Consistent hashing)
Consistent hashing的定义:一致性hash是一种特殊的hash,与传统的hash表最大的区别在于hash表大小调整时,需要再散列的关键字数量要少很多。
-
传统的hash表(比如取模操作,分布位置直接依赖于表的大小):hash表的大小的调整,可能会造成大量的关键字需要再散列。
-
一致性hash表:重新调整大小(resize)的时候,增加/减少一个服务器需要重新 再散列的关键字平均数量 = 关键字数量/槽位的数量,关键字的分布并不直接依赖于表的大小
- distribution scheme which does not directly depend on the number of servers.
一致性hash的设计目标:在分布式系统中,添加与删除服务器不需要大量的改变数据在服务器中的分布(代价太大)
一致性hash的基本思想(重要):
关键:整个哈希空间的取值范围为0~2^32-1。整个空间按顺时针方向组织,根据hash值的位置沿圆环顺时针查找,第一台遇到的服务器就是所对应的处理请求服务器。
- 可以直观的理解为将hash值放在一个可以环形查找的数组中,特定的hash值位置放服务器,比如现在的数据计算的hash值为a,那么直接定位数组中a位置,然后确定a位置后面的一个服务器,那么就去这个服务查找或者写入,
一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间的取值范围为0~2^32-1。整个空间按顺时针方向组织。0~2^32-1在零点中方向重合。接下来使用如下算法对服务请求进行映射,将服务请求使用哈希算法算出对应的hash值,然后根据hash值的位置沿圆环顺时针查找,第一台遇到的服务器就是所对应的处理请求服务器。当增加一台新的服务器,受影响的数据仅仅是新添加的服务器到其环空间中前一台的服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他都不会受到影响。综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展
一致性hash的实例:
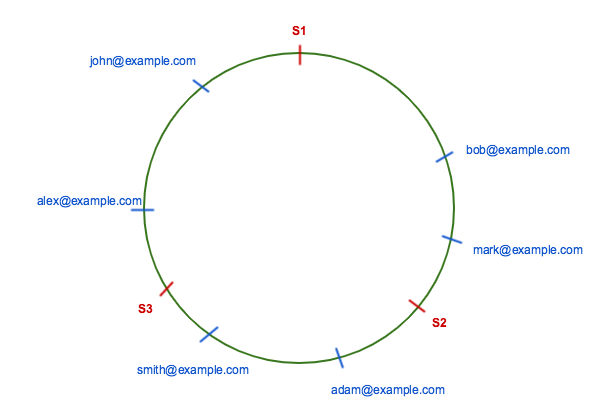
上图中key的分布:
server1: alex@example.com and john@example.com
server2: bob@example.com and mark@example.com
server3: smith@example.com and adam@example.com
移除server 3
服务器3中存储的key会被relocate到服务器1(if server S3 is removed then, all keys from server S3 will be moved to server S1)
--沿着原始hash值的位置查找,找到的第一个服务器不是server3而是server1
问题:全部移动到服务器1会造成单台服务器的热点问题,该如何解决?
基本思想:为每个服务器创建虚拟节点均匀分布在环上,这样就能使得rehash,需要重新散列的关键字均匀的分配到各个服务器。
- To evenly distribute the load among servers when a server is added or removed,it creates a fixed number of replicas ( known as virtual nodes) of each server and distributed it along the circle. So instead of server labels S1, S2 and S3, we will have S10 S11…S19, S20 S21…S29 and S30 S31…S39. The factor for a number of replicas is also known as weight, depends on the situation.
- All keys which are mapped to replicas Sij are stored on server Si. To find a key we do the same thing, find the position of the key on the circle and then move forward until you find a server replica. If server replica is Sij then the key is stored in server Si.Suppose server S3 is removed, then all S3 replicas with labels S30 S31 … S39 must be removed. Now the objects keys adjacent to S3X labels will be automatically re-assigned to S1X and S2X. All keys originally assigned to S1 and S2 will not be moved.
- Similar things happen if we add a server. Suppose we want to add a server S4 as a replacement of S3 then we need to add labels S40 S41 … S49. In the ideal case, one-third of keys from S1 and S2 will be reassigned to S4.
- In general, only the K/N number of keys are needed to remapped when a server is added or removed. K is the number of keys and N is the number of servers ( to be specific, maximum of the initial and final number of servers)
N是增加/减少前服务器的数量
增加1台服务器: 重新rehash的数量 K/(N+1)
减少1台服务器: 重新rehash的数量 K/N*x
详细内容见下面链接
System desing blog:Consistent Hashing
1 redis集群基础
1-1 redis集群总览
1-1-1 集群实现的功能
总的目标:提供高并发,高性能,高可用的服务。
Redis集群(cluster)定义:redis cluster是redis提供的分布式数据库方案,redis集群为数据的访问提供了两类支持(自动数据切分与容错性):
- 通过多个节点自动的进行数据的切分(分散访问压力与存储压力,实现负载均衡以及可扩展)
automatically split your dataset among multiple nodes
- 提供一定的容错性即部分节点宕机的时候,数据的访问不受影响
continue operations when a subset of the nodes are experiencing failures or are unable to communicate with the rest of the cluster.
1-1-2 redis4.0源码中cluster相关的代码实现
三个关键的结构体定义:
| 结构体名称 | 备注 |
|---|---|
| clusterNode | 当前服务器作为redis的节点信息维护 |
| clusterState | 集群状态信息维护 |
| clusterLink | clusterLink encapsulates everything needed to talk with a remote node(包含远程通信所需的一切信息) |
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* CLUSTER_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node. Note that it
may be NULL even if the node is a slave
if we don't have the master node in our
tables. */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
mstime_t orphaned_time; /* Starting time of orphaned master condition */
long long repl_offset; /* Last known repl offset for this node. */
char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known clients port of this node */
int cport; /* Latest known cluster port of this node. */
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
typedef struct clusterState {
clusterNode *myself; /* This node */
uint64_t currentEpoch;
int state; /* CLUSTER_OK, CLUSTER_FAIL, ... */
int size; /* Num of master nodes with at least one slot */
dict *nodes; /* Hash table of name -> clusterNode structures */
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
clusterNode *importing_slots_from[CLUSTER_SLOTS];
clusterNode *slots[CLUSTER_SLOTS];
uint64_t slots_keys_count[CLUSTER_SLOTS];
rax *slots_to_keys;
/* The following fields are used to take the slave state on elections. */
mstime_t failover_auth_time; /* Time of previous or next election. */
int failover_auth_count; /* Number of votes received so far. */
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
/* Manual failover state in common. */
mstime_t mf_end; /* Manual failover time limit (ms unixtime).
It is zero if there is no MF in progress. */
/* Manual failover state of master. */
clusterNode *mf_slave; /* Slave performing the manual failover. */
/* Manual failover state of slave. */
long long mf_master_offset; /* Master offset the slave needs to start MF
or zero if stil not received. */
int mf_can_start; /* If non-zero signal that the manual failover
can start requesting masters vote. */
/* The followign fields are used by masters to take state on elections. */
uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */
int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */
/* Messages received and sent by type. */
long long stats_bus_messages_sent[CLUSTERMSG_TYPE_COUNT];
long long stats_bus_messages_received[CLUSTERMSG_TYPE_COUNT];
long long stats_pfail_nodes; /* Number of nodes in PFAIL status,
excluding nodes without address. */
} clusterState;
/* clusterLink encapsulates everything needed to talk with a remote node. */
typedef struct clusterLink {
mstime_t ctime; /* Link creation time */
int fd; /* TCP socket file descriptor */
sds sndbuf; /* Packet send buffer */
sds rcvbuf; /* Packet reception buffer */
struct clusterNode *node; /* Node related to this link if any, or NULL */
} clusterLink;
1-1-3 redis集群预备知识:gossip协议
通信端口与服务端口
- 注意端口可以修改
redis cluster架构下的每个redis都要开放两个端口号,比如一个是6379,另一个就是加1w的端口号16379。
6379端口:就edis服务器入口。
16379端口:用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用的是一种叫gossip 协议的二进制协议,用于节点间高效的数据交换,占用更少的网络带宽和处理时间。
集群元数据的维护有两种方式:集中式、Gossip 协议。
1. 集中式(实时性好,存储压力大)
将集群元数据集中存储在一个节点上。典型代表是大数据领域的 storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper对所有元数据进行存储维护。
2 分布式(数据同步存在延迟,存储压力小)
redis 维护集群元数据采用的是gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。
gossip 协议的基础命令
| 常用命令 | 作用 |
|---|---|
| meet | 通知新节点去加入集群 |
| ping | 元数据交换 |
| pong | ping 和 meet消息的返回响应,包含状态和其它信息,也用于信息广播和更新 |
| fail | 某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说这个节点已宕机。 |
redis cluster的hash slot算法和一致性 hash 算法、普通hash算法的介绍
1-2 redis集群设计要点概述
要点1:数据的固定分片机制(固定大小hash槽)
基本思想:官方redis集群并没有采用一致性hash对关键字空间进行分区。而是将数据库分为固定大小的16384个槽,数据库中每个key都属于16384个槽中的一个,集群为每个节点分配一定数量的槽,槽的数量为[0,16384]。
注意点:这里的槽位可以理解为一份存储空间,redis根据槽号确定当前的数据在哪一个redis节点。
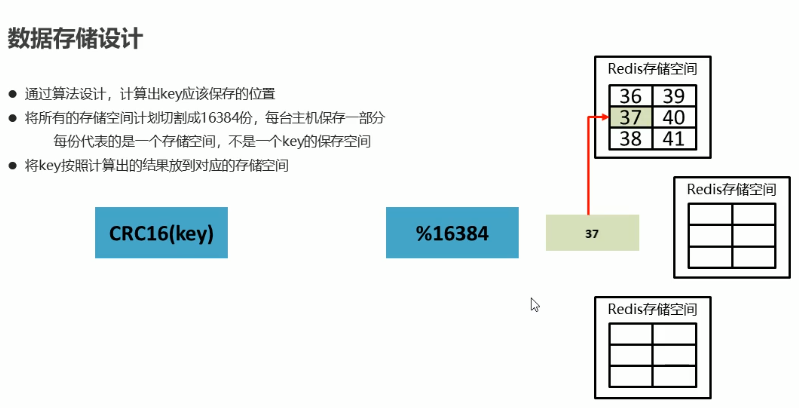
槽号的计算流程:Key通过CRC16得到2个字节的校验码,然后对总的槽位数量(166384)取模得到这个key对应的槽号。
- 循环冗余校验(Cyclic Redundancy Check, CRC)是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种信道编码技术,主要用来检测或校验数据传输或者保存后可能出现的错误。它是利用除法及余数的原理来作错误侦测的。
问题:加机器与减少机器,槽位分配方法?
- 加机器则是在每个节点上分出槽给新的机器,减机器则是将多出的槽分配给其他机器
要点2:节点之间的通讯设计
1)各个数据库相互通信,保存各个库中槽的编号数据(每个节点都要知道当前的槽的分配情况)
2)一次命中,直接返回
3)一次未命中,告知具体位置
问题:为什么redid的槽位大小是16384(2kb,是一个bit数组)?
- 注意:槽指派是一个master为单位的,多个master形成集群,每个master可以带有多个从服务器
总结:
1、消息大小考虑:尽管crc16能得到65535个值,但redis选择16384个slot,是因为16384的消息只占用了2k,而65535则需要8k。
2、集群规模设计考虑:集群设计最多支持1000个分片,16384是相对比较好的选择,需要保证在最大集群规模下,slot均匀分布场景下,每个分片平均分到的slot不至于太小。
需要注意2个问题:
1、为什么要传全量的slot状态?
因为分布式场景,基于状态的设计更合理,状态的传播具有幂等性
2、为什么不考虑压缩?
集群规模较小的场景下,每个分片负责大量的slot,很难压缩。
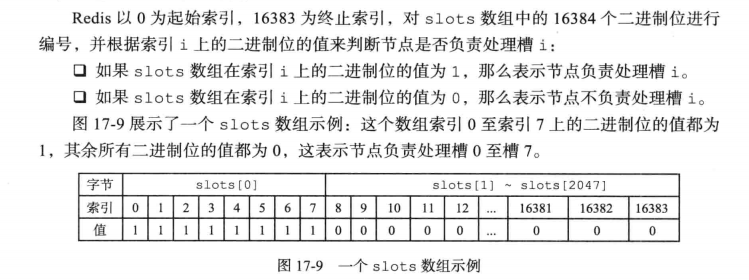
1-3 Redis集群槽的相关流程
1-3-1 初始槽位分配流程
step1:集群中服务器连接的建立
使用命令:cluster meet <ip> <port> :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子
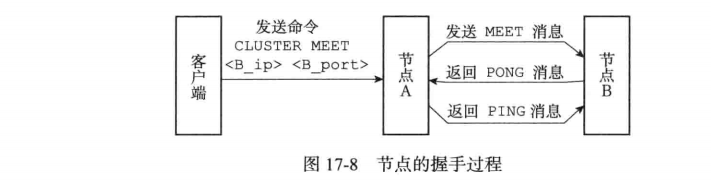
假设当前集群的存在一个节点A,该节点A现在通过cluster meet命令让节点B加入集群,加入流程:
1)节点A向节点B发送meet命令
2)节点B成功接受节点A的命令,则创建对应的clusterNode结构将A节点加入,并返回pong消息
3)节点A收到PONG消息,则知道B节点已经收到meet命令,然后发送ping消息进行确认,节点B收到确认的PING消息,则A,B节点连接建立完成
4)A,B节点建立完成,A节点会通过gossip协议将B节点信息广播到集群中其他节点,其他节点收到该信息,重复1~3)与节点B建立连接。
step2:所有节点建立连接后,分配hash槽
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* CLUSTER_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
/*每个redis节点都会有槽指派的信息,是一个2个字节的bit数组*/
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
int numslaves; /* Number of slave nodes, if this is a master */
struct clusterNode **slaves; /* pointers to slave nodes */
struct clusterNode *slaveof; /* pointer to the master node. Note that it
may be NULL even if the node is a slave
if we don't have the master node in our
tables. */
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
mstime_t orphaned_time; /* Starting time of orphaned master condition */
long long repl_offset; /* Last known repl offset for this node. */
char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known clients port of this node */
int cport; /* Latest known cluster port of this node. */
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
槽指派信息信息的传播
1个节点除了将自己负责处理的槽记录在slots数组中,还会将slots数组信息传递给集群中其他节点,因此每个节点都能够获取整个集权的槽的分配信息。
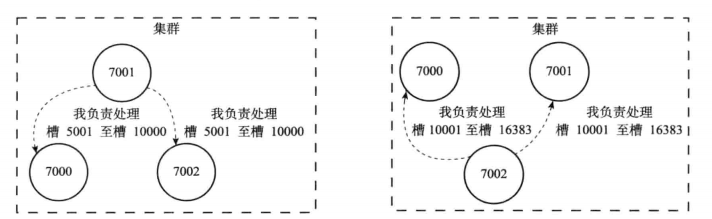
注意:集群中每个节点都会知道数据库中的16384个槽被指派给集群中哪些节点。
问题:为什么每个节点除了维护全局信息外还要单独维护单个节点的槽指派信息?

step3:当所有hash槽分配完毕,集群就会进入上线阶段,此时redis客户端可以访问
1-3-2 根据key获取槽位置的流程
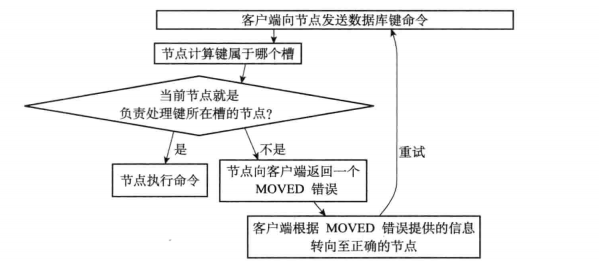
场景:客户端向某个节点发出set命令
step1: 使用CRC16算法,CRC16(key)得到0-16383之间的整数作为槽号
step2: 判断当前槽号是否为当前节点负责,不是则根据clusterState.slots[i]所指向的clusterNode结构中记录的
IP和端口号,向客户端返回moved错误
step3:客户端根据moved错误提供的信息转向正确的节点。
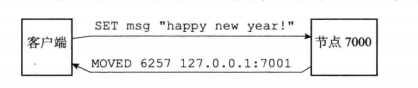
- 上图就是moved命令的格式,是IP+端口号
1-3-3 redis中重新分片的流程(扩容与缩容的流程)
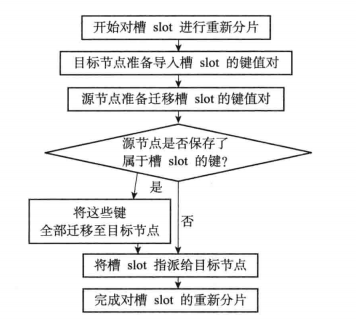
1)目标节点导入新分配的槽号
2)从源点分离出的槽号所关联的信息都会被迁移到目标节点。
问题:分片的过程中,数据的访问该如何处理?
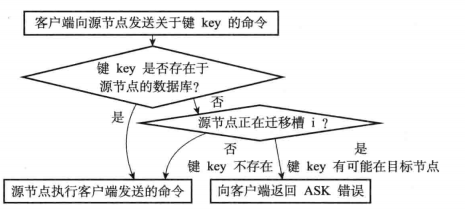
明确,节点槽指派信息会在重新分片后更新。因此在分片完成前:
1)如果是访问数据库,则是先查找当前槽位的集群中是否有数据,有直接返回,没有则表明数据已经迁移到新的槽位拥有者,此时会返回ASK错误,该信息会让客户端访问新的槽位拥有者。
2)如果是设置的话,则直接让其去新的槽位拥有者操作。
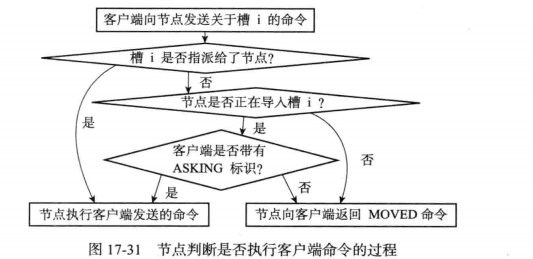
注意:在导入槽的过程中的数据访问时,客户端必须先获取ASKING标识
问题:ASK错误与MOVE错误的区别(永久与临时)?

1-4 redis的集群的高可用实现
基本思想:redis将16384个hash槽分给主节点,而每个主节点通常会有从服务器。
从服务器的职责:
1)监控主服务器,当主节点挂了,向集权广播自己这里的主节点挂了的信息
2)复制主节点的内容。
故障转移流程

问题:集群模式下,如何选举出替代原先主节点的从节点?
基本思想:与哨兵原理类型,都是基于Raft领头选取算法
1)哨兵节点在哨兵之间选出leader负责故障转移
2)集群模式下是由其他主节点进行选举从节点作为新的主节点,当某个从节点的票数N/2+1时,就是新的主节点
3 redis的集群的实际操作
3-0 redis cluster相关的命令
# 集群
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
# 节点
cluster meet <ip> <port> :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
# 槽(slot)
cluster addslots <slot> [slot ...] :将一个或多个槽( slot)指派( assign)给当前节点。
cluster delslots <slot> [slot ...] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot <slot> node <node_id> :将槽 slot 指派给 node_id 指定的节点,槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot <slot> migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot <slot> importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot <slot> stable :取消对槽 slot 的导入( import)或者迁移( migrate)。
# 键
cluster keyslot <key> :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot <slot> :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot <slot> <count> :返回 count 个 slot 槽中的键
3-1 redis单机版集群的搭建
目标:搭建一个集群,集群中横向扩展3套主从结构的redis实例,每套主从结构包括一个master实例以及一个slave实例。
- 集群中合计有6个节点
redis集群节点实例配置:redis-6379.conf
port 6379
daemonize no
dir /home/god/redis-4.0.0/log_info
appendonly yes
appendfsync everysec
cluster-enabled yes # 开启cluster mode
cluster-config-file nodes-6379.conf # 集群的配置文件名称
cluster-node-timeout 10000 # 集群下线超时时间10s
6个节点启动后
(base) god@god-MS-7C83:~/redis-4.0.0/conf$ ps -ef | grep redis
god 2723 1114 0 16:03 pts/5 00:00:00 redis-server *:6379 [cluster]
god 2734 1297 0 16:04 pts/6 00:00:00 redis-server *:6380 [cluster]
god 2760 1458 0 16:09 pts/7 00:00:00 redis-server *:6381 [cluster]
god 2764 1721 0 16:09 pts/8 00:00:00 redis-server *:6382 [cluster]
god 2768 1877 0 16:09 pts/9 00:00:00 redis-server *:6383 [cluster]
god 2772 2048 0 16:09 pts/10 00:00:00 redis-server *:6384 [cluster]
god 2777 2410 0 16:10 pts/11 00:00:00 grep --color=auto redis
cluster建立命令
- --replicas表示每个master带动1个slave
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
执行结果
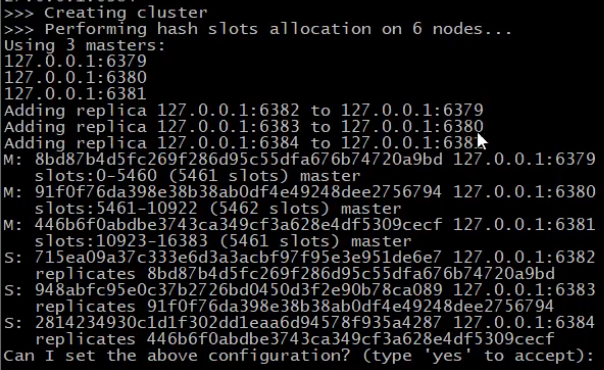
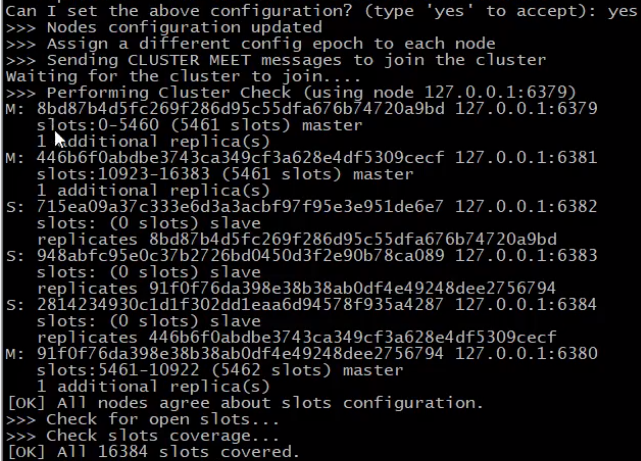
- 上面的命令反馈信息显示创建了3个master,每个master有一个slave
- 可以看到总共有16384个slots,平均分配给3个master,分别是5461,5461,5462个slots(5461+5461+5462=16384)
建立命令执行后系统将集群信息写入nodes-6379.conf 文件
- 可以看到配置文件中除了记录myself的信息,还记录其他所有cluster节点的信息

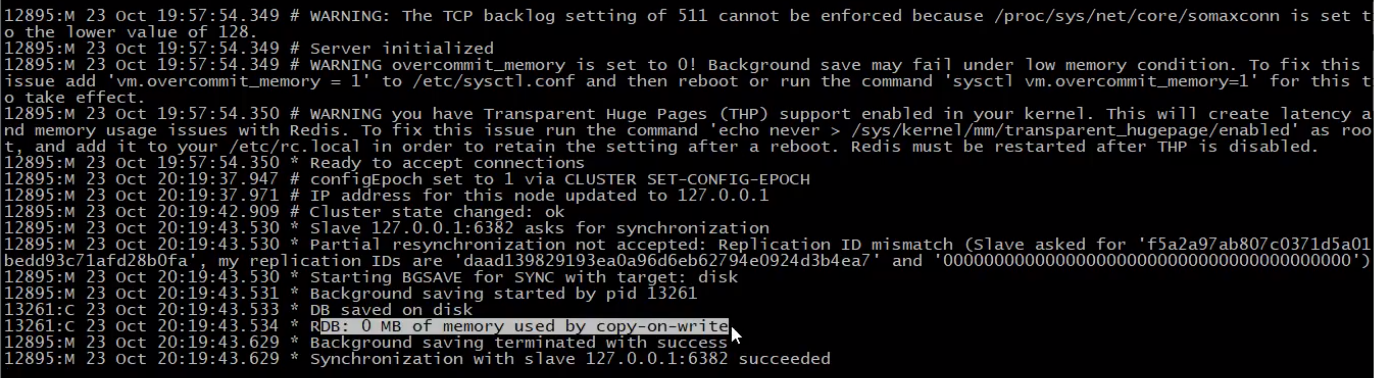
集群建立后master打印的日志信息
集群建立后slave打印的日志信息
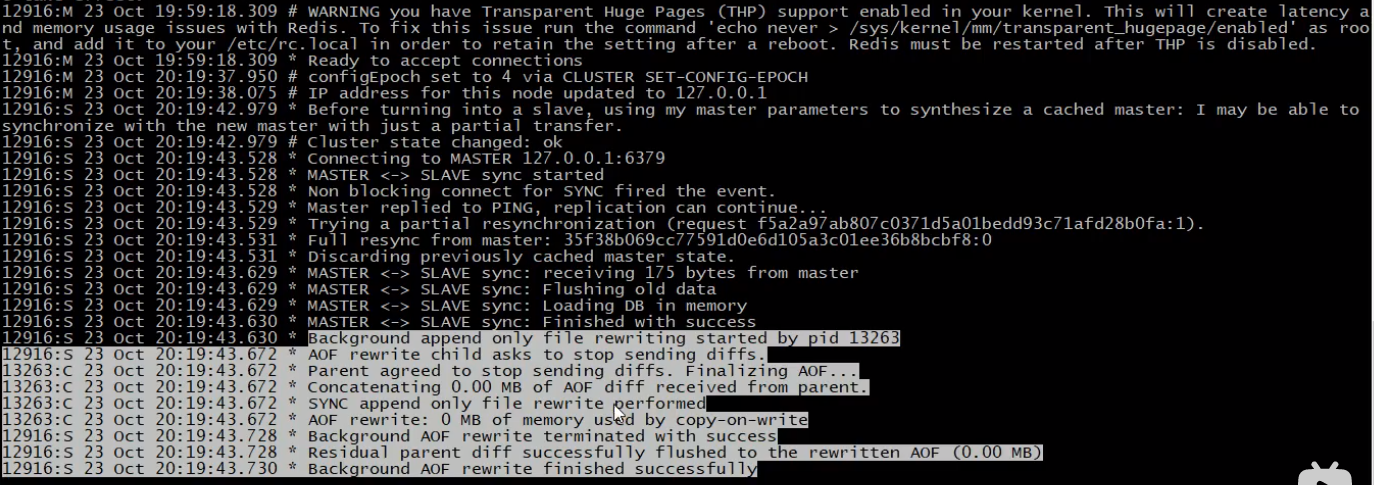
可以看到master与slave在建立cluster进行了同步。
3-2 集群数据获取流程
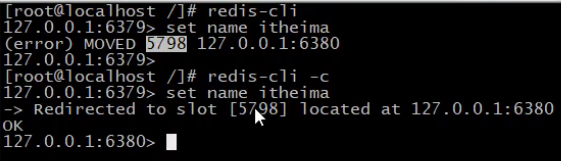
- 图中key是“name",其对应的slot是5789,而槽5789位于端口号为6380的机器。
注意:通过客户端访问集群中数据必须加上-c选项。
redis-cli -c : Enable cluster mode (follow -ASK and -MOVED redirections).
3-3 集群的主从下线以及主从切换
说明:redis集群中的节点分为主节点和从节点,其中主节点用于处理槽,而从节点用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点处理命令。
情况1:从节点下线
从节点所属主节点日志信息

上图说明:当从服务器下线,该节点所属从节点会监测到该服务器下线,此时会将该服务所属节点(runid)标记为failing (quorum reached),并将这个信息通过FAIL message广播出去。
其他主节点信息日志信息

上图说明:可以看到其他主节点收到FAIL message也知道了具体的下线的从节点信息。
当下线的从节点又上线的话,主节点会恢复与从节点的数据同步,并告知其他主节点这个节点又恢复了,其他节点则清除之前的不能用标记。
情况2:主节点下线
下线主节点的从属节点日志信息
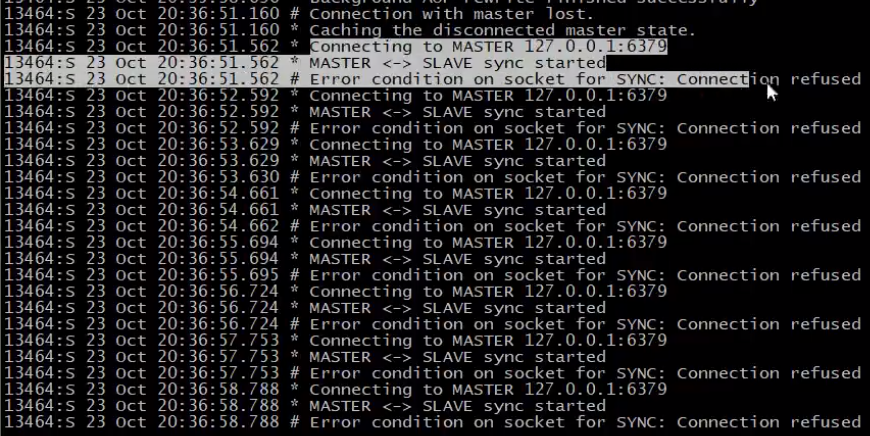
上图说明:当从节点发现主节点下线,在配置文件中超时时间内,从节点会不断尝试与主节点建立连接。上图中超时时间是10s,每1s都会尝试一次,所以上图中尝试了10次。
集群节点中超时相关的配置文件中配置项:
cluster-node-timeout 10000 # 集群下线超时时间10s

上图说明:当超过超时时间,所属从节点会进行故障转移

下线的主节点如果又上线则会变为从节点:


3-4 redis集群常用的配置选项以及命令
Cluster配置
cluster-enabled yes|no // 添加节点
cluster-config-file <filename> // cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-node-timeout <milliseconds> // 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点,实际通常设置为30s左右
cluster-migration-barrier <count> // master连接的slave最小数量
Cluster节点操作命令
cluster nodes // 查看集群节点信息
cluster replicate <master-id> // 进入一个从节点 redis,切换其主节点
cluster meet ip:port // 发现一个新节点,新增主节点
cluster forget <id> // 忽略一个没有solt的节点
cluster failover // 手动故障转移
redis-trib命令
redis-trib.rb是官方提供的Redis Cluster的管理工具,无需额外下载,默认位于源码包的src目录下,但因该工具是用ruby开发的,所以需要准备相关的依赖环境。
redis-trib.rb add-node // 添加节点
redis-trib.rb del-node // 删除节点
redis-trib.rb reshard // 重新分片