计算机视觉基本问题:
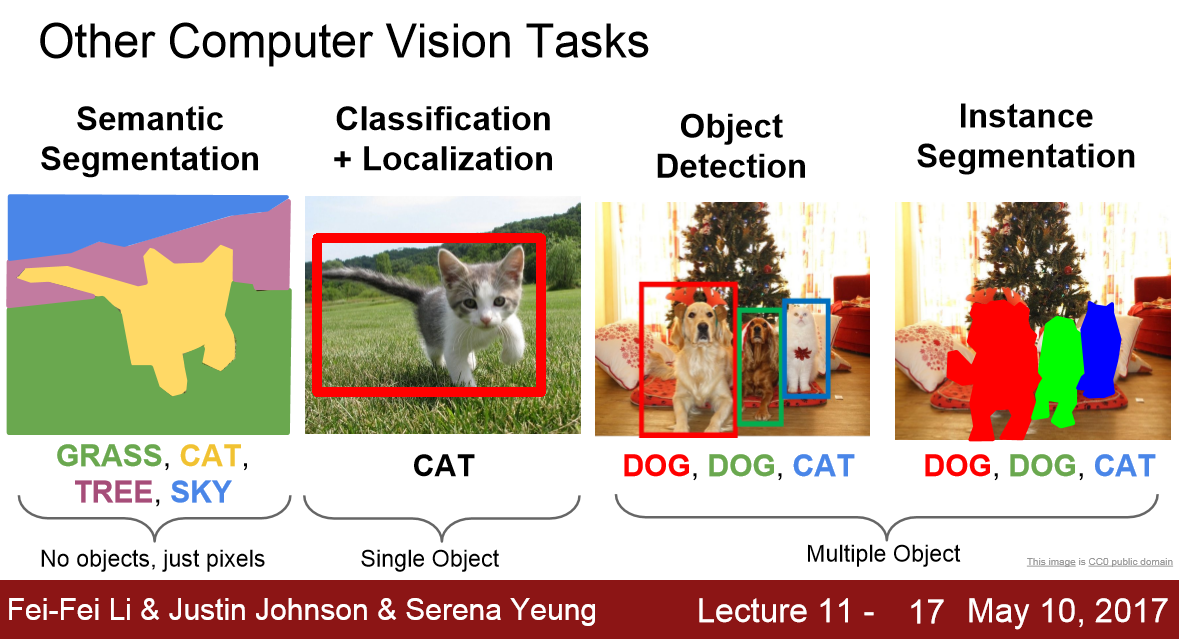
分类问题-classification:
解决是什么的问题,给定一张图片或者一段视频判断里面包含什么类别的目标
定位-Localization:
给定包含一个主体内容的图像,要解决主体内容在哪里的问题,定位出目标的位置。
物体(目标)检测(object detection):
同时解决是什么以及在哪里的问题,定位出目标的位置并且知道目标物是什么。
找出图像中所有感兴趣的目标,确定他们的位置和大小,生成bounding box框出来对应的物体
是CV最具有挑战性的问题
图像分割问题(segmentation:沿着轮廓把物体切出来)
解决“每一个像素分别属于哪个目标或者场景”的问题。可以分为instance-level(实例分割)的分割和scene-level的分割(场景分割)
目标检测相关算法
DPM:
在DCNN出现之前,DPM一直是目标检测领域最优秀的算法,通过提取DPM人工特征,再用latentSVM来进行分类。
DPM的局限性:特征计算复杂,速度慢;人工特征对于旋转,拉伸,视角变化的物体检测效果很差
OverFeat:
alexNet大获成功后,人们开始使用神经网络应用到目标检测任务中,其中OverFeat的主要思想:
1. 采用共享卷积层用于多任务的学习;全卷积网络的思想;3.在特征层进行滑窗操作避免大量重复计算
基于DCNN的目标检测算法发展路线图
R(Region)-CNN:
R-CNN是深度学习进行目标检测的里程碑之作,其过程为:
1.使用selective search算法提取2000个左右的区域候选框;
2.把所有候选框缩成固定大小;
3.用D-CNN提取候选框的特征,得到固定长度的特征向量;
4.把特征向量送入SVM进行分类得到类别信息,送入全连接网络回归得到对应位置坐标信息
主要缺点:
1. 重复计算;2.训练测试不简洁,不是一次做完,须分步实施;3.速度慢;4.输入的图片得到候选框后必须强制缩放成固定大小(227x227)会导致图片信息失真
SPPNet
相比于R-CNN,他将提取候选框特征向量的操作转移到卷积后的特征图上进行,将RCNN中的多次卷积变为一次卷积,大大降低计算量(参考了OverFeat)
1.sppnet针对输入图片先经过大的卷积网络形成feature map图片,
2.生成候选框
3.随后引入金字塔pooling的方式采样候选框图片获得固定大小尺寸的输出
4.进入全连接
5.再进入SVM进行分类
FastRCNN
1.通过ROI Pooling,将不同大小候选框的卷积特征图统一采样成固定大小的特征。
2.实现了多任务的task
FasterRCNN
产出候选框这个工作也由神经网络来做了Region Proposal Network(候选框生成网络)
R-FCN
沿用FasterRCNN架构,在其基础上引入位置敏感得分图,用的比较少
Mask R-CNN
由于Fasetr RCNN在做下采样和ROI Pooling时对特征图大小会做取整操作,因此会引入误差,虽然对于分类任务基本没有影响,但是对于像素级别的检测和分割任务则影响严重,为此,引入"双线性差值填补非整数位置的像素,从而避免精度问题",这样的好处是下游特征图向上游映射时没有位置误差,提升了目标检测的效果,同时使得算法能够满足语义分割任务的精度要求。
生成模型 vs 判别模型
判别模型
判别模型有两种情形
1.针对条件概率建模$p(y|x)$(LR,DNN,RNN,条件随机场),其目标函数一般为$max_ heta frac{1}{n} sum_{i=1}^{n}log p(y_i|x_i; heta)$
2.针对非概率建模$f(x; heta):x ightarrow {0,1}$(SVM, K-NN, DecisionTree),其目标函数一般为$max_ heta frac{1}{n} sum_{i=1}^{n}mathbb{I}(f(x_i; heta)=y_i)$
生成模型
生成模型同样有两种情况:
1. 针对联合概率建模$p(x,y; heta)$,其目标函数为 $max_ heta frac{1}{n} sum_{i=1}^{n}log p(x_i,y_i; heta)$.
一个用于理解的例子,比如电商网站的评价分析,对于判别模型,目标就是给定一条评价预测是正面还是负面的评价;而对于生成模型,则不仅要完成这个条件概率预测,还要建模句子本身出现的概率。因为有很多评价本身就是灌水的,而非有用的评价
2. 非概率的模型: GAN
G和D依次地迭代更新,就像两个玩家,D越来越强,G也要越来越强,左右互博,使得D只能随机判别真伪。
博弈论的纳什均衡(最大最小理论)理论,在均衡时刻,假设判别器什么都不做,你的生成器也不可能变得更好了,同样地,假设生成器什么都不做,你的判别器也不可能做的更好了。