redis笔记
下载完redis,执行make命令。
然后启动redis就进src文件夹,执行./redis-server就可以了。
再在文件夹下执行 ./redis-cli 就可以执行redis的命令了。
pipelining
一次请求发送多个命令,以提高性能。我们在使用redis时都是向它发送命令,每次都是需要和redis建立tcp连接,然后发送命令信息,redis执行命令后,客户端等待着redis的响应。这个我们当然知道,就像访问db,IO开销都是消耗资源的大头,所以redis提供了pipelining功能让它具有一次传输多个命令共同执行的能力。
expire
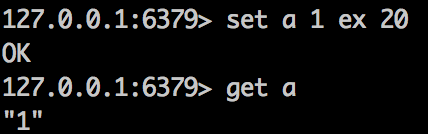
为key设置过期时间,在到期时key会被删除,可以通过PERSIST命令将key转变成永久不过期的key,RENAME命令是不改变过期时间的。
内部的实现机制是怎么样的呢?主动删除和被动删除,主动的就是当这个key在被get的时候检查是否已过期,如果过期就删除。被动的是自身会周期性的挑选出一些有需要过期的key,1秒10次进行以下操作:
1,随机挑选出20个key
2,删除这20个钟已经过期的key
3,如果删除的key超过25%就继续第一步
如此以抽样的方式假定了整个redis内存储的需要删除却没被删除的key在所有有过期机制的key中维持在25%以下。从概率的角度来讲最坏的结果也许会发生。哈哈。
Pub/Sub
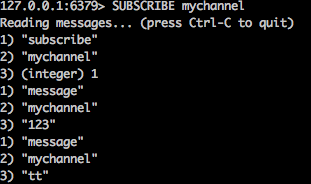
这个功能实现了发布订阅,订阅者是订阅一个channel,发布者向这个channel发送message。发布者和订阅者都可是多个。
订阅者命令:
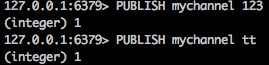
发布者命令:
而且还支持对channel的匹配方式,用PSUBSCRIBE和PUNSUBSCRIBE命令。
PSUBSCRIBE test* 或PUNSUBSCRIBEtest* 如此我们发现,发布者是匹配模式,而订阅者是正常模式,或发布者是正常模式,订阅者是匹配模式,或两个都是匹配模式。增大了灵活性。
订阅者命令:
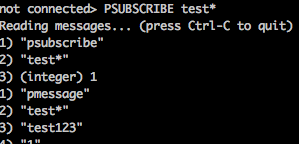 发布者命令:
发布者命令:
Transactions
事务,MULTI命令开启事务,EXEC命令提交事务,DISCARD命令取消事务。
如下操作:
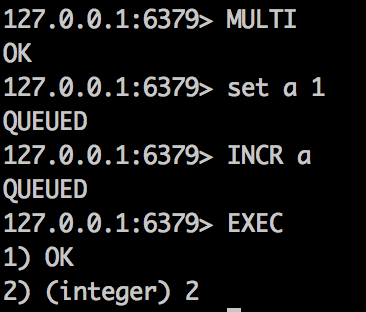
事务中异常场景:
1,在执行MULTI之后EXEC之前,操作redis出现异常的时候,如果收到QUEUED,说明已经在执行列里了,如果返回error,则需要取消事务。
2,在执行EXEC中出现异常,比如命令本身有错,那么事务在执行过程中出错命令之前的命令将不会会退,而是被提交的。这里要有特别注意。
如下操作:
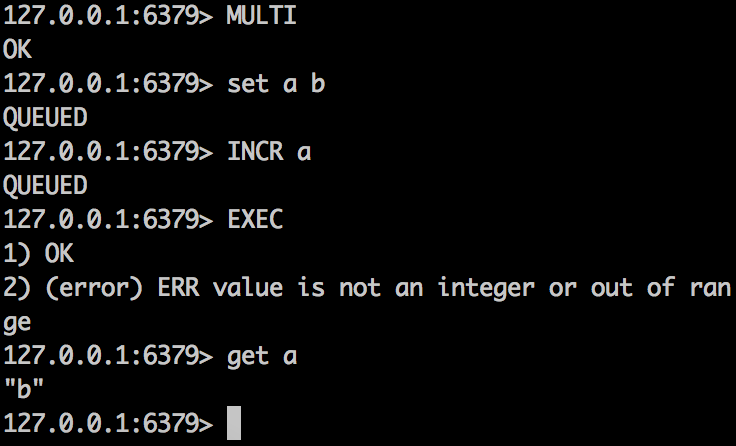
我们看见在执行INCR a 时出错,因为a的value是字符串。但是前面set命令却是提交的。
redis为什么没有回退操作呢,在官方文档中有这样的解释:
1,它认为redis 命令出错只是因为语法有问题,那么在实际场景中应该在到生产环境前已经被测试到。
2,它还认为redis足够快,所以有自信不需要什么会退操作。
竞争场景,使用WATCH来保证互斥操作。WATCH的key会被监控,如果在提交前key内容被改动那么事务会提交失败。
Distributed locks with Redis 官方有文档描述了如何实现一个他们认为可靠的分布式锁,他们称呼这种实现算法为redlock。也提供了各个语言版本的实现列表,java的话它列举的是Redisson:https://github.com/redisson/redisson
单个redis 主备场景,推荐的是放key来锁,value是client的唯一标志,在获取到已经有值时判断是否是自己client的value,类似可重入锁概念。另外在放的key上加上过期时间,防止client挂掉而导致锁不能被其他client获得。问题是master放好key,在同步给slave前挂掉了,slave成为master,却没有这个锁的内容。所以它描述了一个redlock,对应的是多个resid主节点的方式来组建起存储锁的结构,核心是在所有节点里一半以上都被获得锁才算活得锁,随之而来的要处理超时间和依次放锁时间延迟的问题等等。
Partitioning (横向扩展)
多个redis实例,连接起来提供给系统缓存服务,可以随着数据量增加,进行增加redis实例来进行扩展。文档中介绍了两种分割redis实例的办法,一种是在开始的时候规定死一个redis存的是那些key,还有一种是动态的计算key的hash,然后取模分配到redis中去。
而我们也不得不认识到这种横向扩展带来的问题是一些操作上的限制,比如多个操作事务时就无法保证,不同redis实例存储的集合不能操作并集等操作了,虽然我们可以想其他办法解决,这也算带来更大的复杂度。
作者还建议在一开始的时候就考虑切分不同redis实例,可以先在一台机子上创建很多实例,组建好集群,当需要扩大存储空间的时候,将一些节点移入到另一个机子上即可,可以实现无停机迁移。不过现实开发中似乎也不需要这样去做,在数据量不断上升的过程中是有机会配置出更多的实例的,影响其实不大。
实现方式目前有三种:
1,Redis Cluster 官方实现的推荐方案
2,Twemproxy (Twitter的开源项目)类似代理。
3,客户端一致性hash jedis上就实现了这个方案,就是在客户端发起存储数据时对key进行hash算法固定放入对应redis实例中。早前的Sharded代码分析:http://www.cnblogs.com/killbug/p/3227851.html
LRU(Least Recently Used)
maxmemory 配置项可以控制redis最大可用的内存。当存储的内容达到这个最大值时,可以配置不同的策略。
在这个策略配置中可以配置在新增存储时返回错误,或者执行删除一些key来空出空间给新增的内容。而后者删除又有一些策略,比如先删除不常用的,或者随机删除等等。
redis据说是没有实现真正的LRU算法,在实现中为了接近算法,使用了抽样多个key在这些key中选出最应该删除的进行删除。抽样的数量可以配置。事实上,LRU算法是要求最近使用的被严格保留的。而redis实现者认为严格实现的话有点消耗内存。
4.0实现了一个LFU( Least Frequently Used),LRU会带来这样一个问题:当在决策删除key的时候,偏向保留刚刚访问过的key,而如果这些key在很长一段时间都不被使用而只是在删除决策之前刚刚被访问了一下而被保留,是不够科学的。而LFU则是把访问频繁的key保留,在缓存的世界里可能更加有用一些。
说起LRU,Caffeine开源项目,传说使用现代化算法达到了超高的命中率,号称世界上最好的缓存库实现。