一个简单的爬虫工程
环境:
OS:Window10
python:3.7
安装一些库文件
pip install requests
pip install beautifulsoup4
pip install lxml
在安装的时候如果遇到了你的pip版本过低的错误的话,可以找到你本地的C:UsersXXXPycharmProjectsgetHtmlvenvLibsite-packages下面的pip-18.1.dist-info文件夹删除,之后在进行更新
下面是提取一个网页的图片代码
import time
import requests
import os
import threading
from bs4 import BeautifulSoup
class BeautifulPicture():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
self.web_url = "https://unsplash.com/"
self.folder_path = r'C:UserspeiqiangDesktoppython Pic'
def request(self, url):
r = requests.get(url)
return r
def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(path)
if not isExists:
print("创建名字叫做", path, "的文件夹")
os.makedirs(path)
print("创建成功!")
else:
print(path, '文件夹已经存在了,不再创建')
def save_img(self, url, name):
print('开始保存图片...')
img = self.request(url)
file_name = self.folder_path + '{}.jpg'.format(name)
print('开始保存文件')
f = open(file_name, 'ab')
f.write(img.content)
f.close()
thread_lock.release()
print(file_name, '文件保存成功!')
def get_pic(self):
print('开始网页get请求')
r = self.request(self.web_url)
print('开始获取所有img标签')
all_a = BeautifulSoup(r.text, 'lxml').find_all('img')
print('开始创建文件夹')
self.mkdir(self.folder_path)
print('开始切换文件夹')
os.chdir(self.folder_path)
i=0
for a in all_a:
i += 1
print("開始下載第{}張圖片".format(i))
thread_lock.acquire()
print("抓取圖片的URL:", a["src"])
self.save_img(a["src"], i)
thread_lock = threading.BoundedSemaphore(value=10)
beauty = BeautifulPicture()
beauty.get_pic()
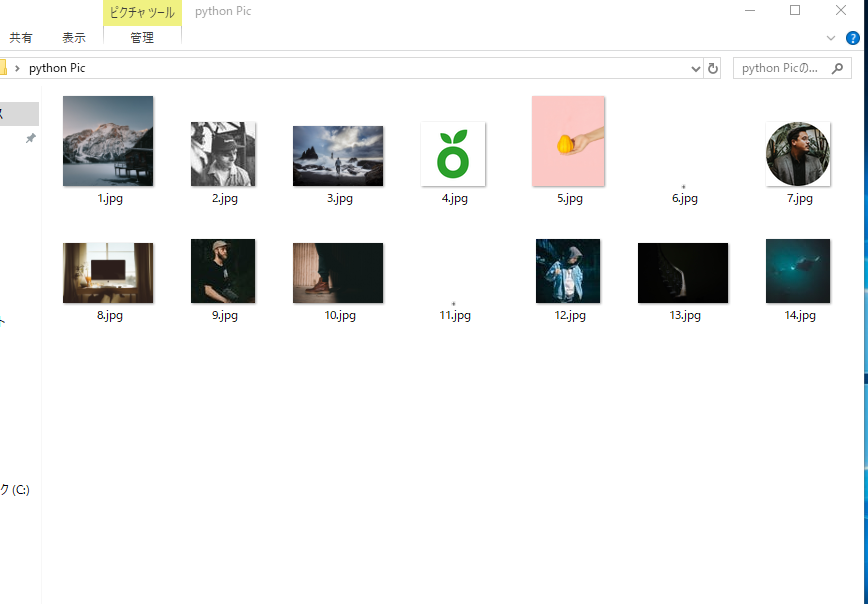
效果如下

本地的存放的路径下