urlencode()的作用
urlencode()是request.GET的一种方法,那他的功能是什么,我们先来测试一下。
这里以一个crm项目的一个功能为例进行测试。
首先,在URL地址中输入想要携带的参数,并发送请求给后台,如下:
![]()
后台我们首先看一下request.GET的类型以及调用urlencode()方法
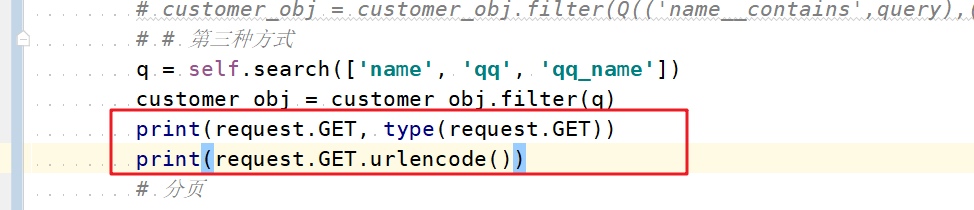
输出结果:

从输出的结果中我们能看到:request.GET是一个queryDict,关于这个queryDict我们后面详细了解,先来看request.GET.urlencode()方法的调用结果,它将url上的参数完整的‘截取’了下来。那么这个方法的工作原理是什么呢?我们来看queryDict的源码。
首先,导入queryDict,然后点进去
from django.http.request import QueryDict

找到urlencode方法
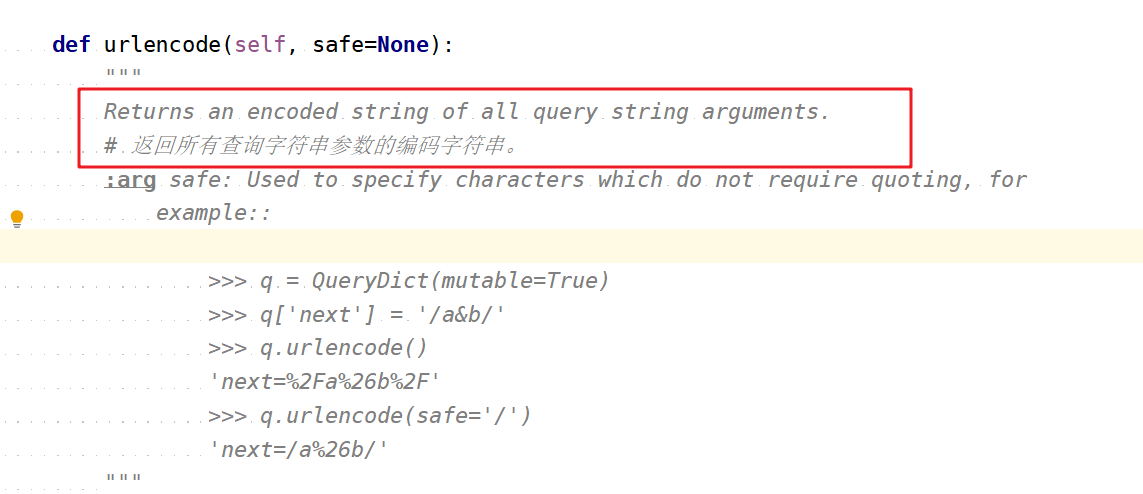
根据方法的注释我们能知道,它是用来将查询参数编码成字符串后返回的方法,也就是说它request.GET中的查询参数的一个个键值对,编码成字符串然后返回。关于上图中的example说的是关于对url上参数等于某个路径的参数的编码,可以看一下。
接下来我们大概的看一下源码:
def urlencode(self, safe=None): """ Returns an encoded string of all query string arguments. # 返回所有查询字符串参数的编码字符串。 :arg safe: Used to specify characters which do not require quoting, for example:: >>> q = QueryDict(mutable=True) >>> q['next'] = '/a&b/' >>> q.urlencode() 'next=%2Fa%26b%2F' >>> q.urlencode(safe='/') 'next=/a%26b/' """ output = [] if safe: # 大概看了一下force_bytes函数,发现他对safe参数进行encode编码,且字符集为utf-8,并返回bytes类型,默认safe为False,先不管。 safe = force_bytes(safe, self.encoding) def encode(k, v): return '%s=%s' % ((quote(k, safe), quote(v, safe))) else: def encode(k, v):# 定义了一个encode()方法,并且返回了urlencode({k:v}),这里属于自己调用自己,但属于定义阶段暂时不调用 return urlencode({k: v}) # print('***', self.lists) # 我在这里打印了一下self.lists(),看看它到底是个什么东西 # 结果:*** <bound method MultiValueDict._iterlists of <QueryDict: {'query': ['1'], 'page': ['2']}>> # 很明显它是一个queryDict字典,由此说明 下面的for循环中的k是这个字典的键,list_是键对应的值(列表) for k, list_ in self.lists(): # 对k进行了utf-8编码,且返回bytes类型的k k = force_bytes(k, self.encoding) output.extend(encode(k, force_bytes(v, self.encoding)) for v in list_) # 结合例子,转化一下 # output.extend(encode(b'query',b'1'),encode(b'page',b'2')) # output.extend(urlencode({'query': '1'}),urlencode({'page': '2'})) # 这里进行了自调用,且经过研究发现urlencode({'query': '1'})是一个生成器,具体原理,看了一会,em.....没搞明白, # 但者不妨碍我们知道它的功能:对参数进行了拼接,如:output.extend(['query=1'],['page=2']) # 最终output列表应为:['query=1','page=2'] return '&'.join(output) # 最终的返回结果应为:query=1&page=2
从上述分析中我们知道,urlencode方法主要是对查询的参数进行了特定形式的拼接。如:query=1&page=2
既然知道知道了作用,我们来进行实战一下
例子:CRM项目在客户展示页,进行分页时一并保留查询条件。
urls.py
from django.conf.urls import url, include from new_crm import views urlpatterns = [ url(r'^customer/', views.Customers.as_view(), name='customer'), ]
视图函数:


class Customers(View): def get(self, request): if request.path_info == reverse('major:my_customer'): customer_obj = Customer.objects.filter(consultant=request.user_obj) # 私户 else: customer_obj = Customer.objects.filter(consultant=None) # 公户 # 搜索 query = request.GET.get('query', '') # # 第一种方式 # customer_obj = customer_obj.filter(Q(name__contains=query) | Q(qq__contains=query) | Q(qq_name__contains=query)) # # 第二种方式 # customer_obj = customer_obj.filter(Q(('name__contains',query),('qq__contains',query),('qq_name__contains',query))) # # 第三种方式 q = self.search(['name', 'qq', 'qq_name']) customer_obj = customer_obj.filter(q) # urlencode 这里进行urlencode() # 分页 page = request.GET.get('page', 1) pag_obj = pagination.Pagination(page=page, page_count=customer_obj.count(), per_num=3, max_show=10) customer_obj = customer_obj[pag_obj.start:pag_obj.end] return render(request, 'customer.html', locals()) def post(self, request): pk_list = request.POST.getlist('pk') obj = Customer.objects.filter(id__in=pk_list) if request.POST.get('action') == 'multi_private': """公户转私户""" obj.update(consultant=request.user_obj) elif request.POST.get('action') == 'multi_public': """私户转公户""" obj.update(consultant=None) return redirect('major:my_customer') def search(self, field_name): """ 模糊查询,有chioce的字段另做判断 :param field_name: 字段列表 :return: """ query = self.request.GET.get('query', '') q = Q() q.connector = 'OR' for field in field_name: q.children.append(Q(('{}__contains'.format(field), query))) return q
模板:
{% extends 'master.html' %} {% block content %} <div class="pull-left btn-sm" style="margin: 0 0;padding: 0 0"><a class="btn btn-primary form-control" href="{% url 'major:add_customer' %}">新增</a> </div> <form action="" class="form-inline pull-right"> <input class="form-control" type="text" name="query"> <button class="btn btn-primary">搜索</button> </form> <form action="" method="post" name="" class="form-inline"> {% csrf_token %} <div class="pull-right"> <select name="action" class="form-control"> <option value="multi_private">公户转私户</option> <option value="multi_public">私户转公户</option> </select> <button class="btn btn-primary btn-sm">提交</button> </div> <table class="table table-bordered table-hover " style="margin-bottom: 0 "> <thead> <tr> <th>选择</th> <th>序号</th> <th>姓名</th> <th>QQ</th> <th>性别</th> <th>手机号</th> <th>出生日期</th> <th>最后跟进日期</th> <th>预计再次跟进日期</th> <th>销售</th> <th>状态</th> <th>已报班级</th> <th>操作</th> </tr> </thead> <tbody> {% for obj in customer_obj %} <tr> <td><input type="checkbox" name="pk" value="{{ obj.pk }}"></td> <td>{{ forloop.counter }}</td> <td>{{ obj.name }}</td> <td>{{ obj.qq }}</td> <td>{{ obj.get_sex_display }}</td> <td>{{ obj.phone }}</td> <td>{{ obj.birthday }}</td> <td>{{ obj.last_consult_date }}</td> <td>{{ obj.next_date }}</td> <td>{{ obj.consultant }}</td> <td>{{ obj.get_status_display }}</td> <td>{% for class in obj.class_list.all %} {% if forloop.last %} {{ class }} {% else %} {{ class }}、 {% endif %} {% endfor %} </td> <td> <button><a href="{% url 'major:edit_customer' obj.pk %}">编辑</a></button> <button>删除</button> </td> </tr> {% endfor %} </tbody> </table> {{ pag_obj.page_html|safe }} </form> {% endblock %}
前面我们说到request.GET是一个queryDict,且里面保存的是GET请求的参数,那我们是不是也可以对里面的参数进行修改呢?
先来尝试一下:
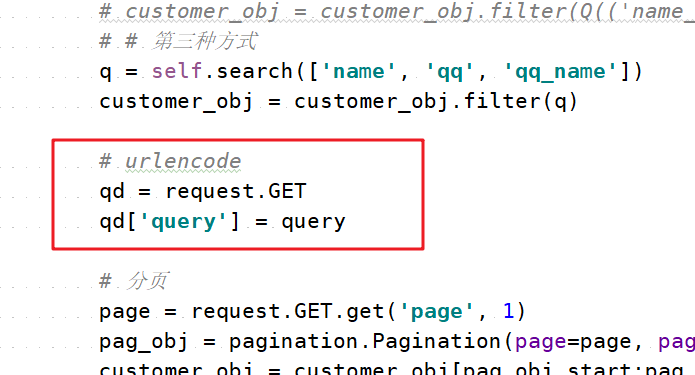
通过浏览器发送请求,结果如下:

查看后台报错:

查看抛出异常的代码

修改一下__mutable参数

再次访问:
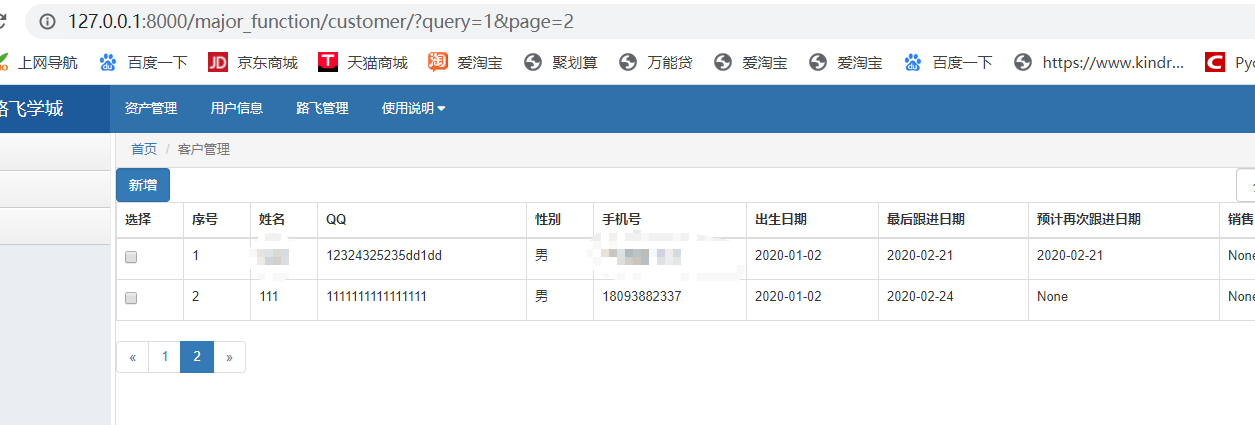
页面是访问正常了,但我们这里的分页跳转的时候,还是并未将query查询参数加进去,接下来我要进行对自定义的分页器进行修改,自定义分页器文章链接:https://www.cnblogs.com/kindvampire/p/12342484.html
理一下思路:目前我们要达到的效果是:当前端加入了查询参数时,后端将查询的数据返回,并且进行分页,分页的页码跳转链接上面拥有前面输入的查询参数query。
如何做:将查询参数自动添加到页码跳转链接中。
先附上之前写的自定义分页器代码:
class Pagination(object): def __init__(self, page, page_count, per_num=10, max_show=10): """ :param page:前端传入的页码 :param page_count: 分页的数据总条数 :param per_num: 每页显示的数据条数 :param max_show: 每页显示的最大页码数 """ self.page = page self.page_count = page_count self.per_num = per_num self.max_show = max_show try: self.page = int(self.page) if self.page <= 0: self.page = 1 except Exception: self.page = 1 """ 索引切片 page 起始 终止 0 10 10 20 20 30 """ # 数据切片起始值 self.start = (self.page - 1) * self.per_num # 数据切片终止值 self.end = self.page * self.per_num # 总页码数 self.sum_page, more = divmod(self.page_count, self.per_num) if more: self.sum_page += 1 # 前端循环的a标签的值 self.num = [i for i in range(1, self.sum_page + 1)] # 页码限制 # 页码的切片的起始值 self.page_start = 0 # 页码切片的终止值 self.page_end = self.max_show # 页码的偏移量 half_page = self.max_show // 2 if self.page < self.max_show: """ 如果page在第一页,什么都不做,即page_start=0,page_end=max_show """ pass if self.page > self.sum_page: """ 如果page参数大于总页码数,跳转到最后一页,针对于url上面手动输入page参数 """ # 终止值为最后一页 self.page_end = self.sum_page # 起始值向前偏移half_page self.page_start = self.page_end - half_page # 数据部分也需要设定,不然显示为空 self.start = (self.sum_page - 1) * self.per_num self.end = self.sum_page * self.per_num # 当page大于总页码时,让page等于最大的页码,为了给最后一页添加激活样式 self.page = self.sum_page else: """ page当前页码即不在第一页,也不在最后一页(或超过最后一页),起始值向前偏移half_page,向后偏移half_page """ self.page_start = self.page - half_page self.page_end = self.page + half_page # 当总页码数小于每页最大展示页码数量时,无论在那一页都展示全部的页码 if self.max_show > self.sum_page: self.page_start = 0 self.page_end = self.sum_page # 当传入的总数据量小于等于0时(主要是等于零),会报错,通过下面的判断来解决这个问题 if page_count <= 0: self.start = 0 self.end = 0 def page_html(self): num = self.num[self.page_start:self.page_end] html_list = [] # 页码样式的头 html_list.append( '<div class="pull-left form-group col-sm-7" style="padding-left:0"><nav aria-label="Page navigation"><ul class="pagination">') # 当前页为1时,添加上一页禁用样式disabled if self.page == 1: html_list.append( '<li class="disabled"><a aria-label="Previous"><span aria-hidden="true">«</span></a></li>') else: html_list.append( '<li ><a href="?page={}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format( self.page - 1)) for n in num: if self.page == n: html_list.append('<li class="active"><a>{}</a></li>'.format(n)) else: html_list.append('<li><a href="?page={}">{}</a></li>'.format(n, n)) # 当前页为最后一页时,添加下一页禁用样式disabled if self.page == self.sum_page: html_list.append( '<li class="disabled"><a aria-label="Next"><span aria-hidden="true">»</span></a></li>') else: html_list.append( '<li><a href="?page={}" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format( self.page + 1)) # 页码样式的尾 html_list.append('</ul></nav></div>') # 将列表中的html代码拼接起来 html_list = "".join(html_list) return html_list
下面进行操作:
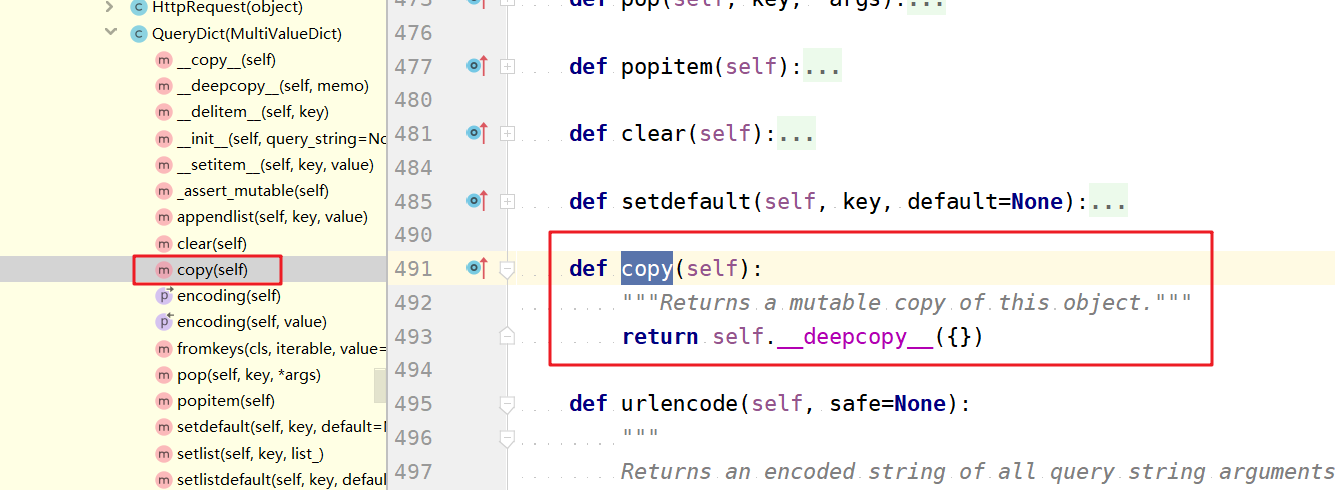
第一步:将request.GET传入到分页器中,为了避免出现分页其中修改request.GET而影响到后续代码的结果,我们需要深拷贝一份request.GET,然后传入分页器(我们需要注意的是:分页器需要的是request.GET里面的信息,并不需要对原request.GET里的参数进行修改)
注意点:QueryDict中自己定义了copy()方法(深拷贝),且mutable参数设置为True,不需要我们去设置,所以直接调用即可。
视图函数:

分页器:
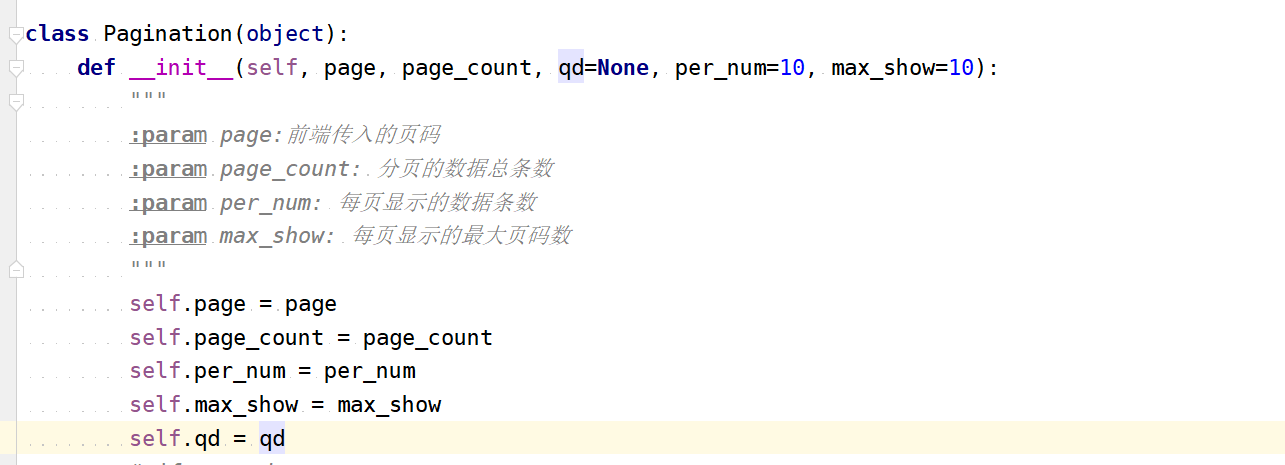
第二步:自动生成页码链接(先手动修改页码,然后在页码链接部分上调用urlencode方法,自动生成页码链接参数。)
代码修改如下:
# -*- coding: utf-8 -*- # __author__ = "maple" from django.http.request import QueryDict class Pagination(object): def __init__(self, page, page_count, qd=None, per_num=10, max_show=10): ...... def page_html(self): num = self.num[self.page_start:self.page_end] html_list = [] # 页码样式的头 html_list.append( '<div class="pull-left form-group col-sm-7" style="padding-left:0"><nav aria-label="Page navigation"><ul class="pagination">') # 当前页为1时,添加上一页禁用样式disabled if self.page == 1: self.qd['page'] = 1 html_list.append( '<li class="disabled"><a href="?{}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format( self.qd.urlencode())) else: self.qd['page'] = self.page -1 html_list.append( '<li ><a href="?{}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format( self.qd.urlencode())) for n in num: self.qd['page'] = n if self.page == n: html_list.append('<li class="active"><a>{}</a></li>'.format(n)) else: html_list.append('<li><a href="?{}">{}</a></li>'.format(self.qd.urlencode(), n)) # 当前页为最后一页时,添加下一页禁用样式disabled if self.page == self.sum_page: self.qd['page'] = self.sum_page html_list.append( '<li class="disabled"><a href="?{}" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format( self.qd.urlencode())) else: self.qd['page'] = self.page + 1 html_list.append( '<li><a href="?{}" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format( self.qd.urlencode())) # 页码样式的尾 html_list.append('</ul></nav></div>') # 将列表中的html代码拼接起来 html_list = "".join(html_list) return html_list
到这里基本就完成了分页保留查询参数的功能。你可能到这里就有点迷糊了,在分页器中调用urlencode的时候没有添加查询参数啊,它是怎么上去的?注意:我们在发送请求的时候,直接就将query参数添加进去了,所以每一次urlencode进行参数拼接时会将query查询参数拼接进去并自动生成a标签的链接地址,当然,当query为空的时候,它也是不会添加进去的。
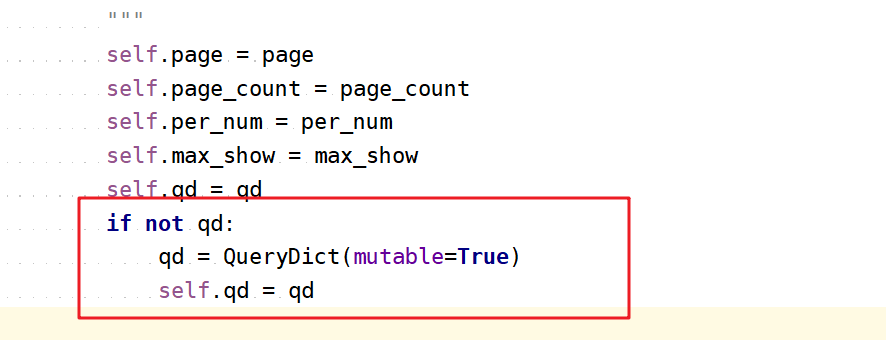
注意:这里有一点bug,当我们不想传入request.GET.copy()的时候是会报错的因为qd默认是None,所不能调用urlencode,我们要避免出现这个bug,就需要手动生成一个QueryDict,并设置mutable为True。操作如下:
附:自定义分页器代码及使用
# -*- coding: utf-8 -*- # __author__ = "maple" from django.http.request import QueryDict class Pagination(object): def __init__(self, page, page_count, qd=None, per_num=10, max_show=10): """ :param page:前端传入的页码 :param page_count: 分页的数据总条数 :param per_num: 每页显示的数据条数 :param max_show: 每页显示的最大页码数 """ self.page = page self.page_count = page_count self.per_num = per_num self.max_show = max_show self.qd = qd if not qd: qd = QueryDict(mutable=True) self.qd = qd try: self.page = int(self.page) if self.page <= 0: self.page = 1 except Exception: self.page = 1 """ 索引切片 page 起始 终止 1 0 10 2 10 20 3 20 30 """ # 数据切片起始值 self.start = (self.page - 1) * self.per_num # 数据切片终止值 self.end = self.page * self.per_num # 总页码数 self.sum_page, more = divmod(self.page_count, self.per_num) if more: self.sum_page += 1 # 前端循环的a标签的值 self.num = [i for i in range(1, self.sum_page + 1)] # 页码限制 # 页码的切片的起始值 self.page_start = 0 # 页码切片的终止值 self.page_end = self.max_show # 页码的偏移量 half_page = self.max_show // 2 if self.page < self.max_show: """ 如果page在第一页,什么都不做,即page_start=0,page_end=max_show """ pass if self.page > self.sum_page: """ 如果page参数大于总页码数,跳转到最后一页,针对于url上面手动输入page参数 """ # 终止值为最后一页 self.page_end = self.sum_page # 起始值向前偏移half_page self.page_start = self.page_end - half_page # 数据部分也需要设定,不然显示为空 self.start = (self.sum_page - 1) * self.per_num self.end = self.sum_page * self.per_num # 当page大于总页码时,让page等于最大的页码,为了给最后一页添加激活样式 self.page = self.sum_page else: """ page当前页码即不在第一页,也不在最后一页(或超过最后一页),起始值向前偏移half_page,向后偏移half_page """ self.page_start = self.page - half_page self.page_end = self.page + half_page # 当总页码数小于每页最大展示页码数量时,无论在那一页都展示全部的页码 if self.max_show > self.sum_page: self.page_start = 0 self.page_end = self.sum_page # 当传入的总数据量小于等于0时(主要是等于零),会报错,通过下面的判断来解决这个问题 if page_count <= 0: self.start = 0 self.end = 0 def page_html(self): num = self.num[self.page_start:self.page_end] html_list = [] # 页码样式的头 html_list.append( '<div class="pull-left form-group col-sm-7" style="padding-left:0"><nav aria-label="Page navigation"><ul class="pagination">') # 当前页为1时,添加上一页禁用样式disabled if self.page == 1: self.qd['page'] = 1 html_list.append( '<li class="disabled"><a href="?{}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format( self.qd.urlencode())) else: self.qd['page'] = self.page -1 html_list.append( '<li ><a href="?{}" aria-label="Previous"><span aria-hidden="true">«</span></a></li>'.format( self.qd.urlencode())) for n in num: self.qd['page'] = n if self.page == n: html_list.append('<li class="active"><a>{}</a></li>'.format(n)) else: html_list.append('<li><a href="?{}">{}</a></li>'.format(self.qd.urlencode(), n)) # 当前页为最后一页时,添加下一页禁用样式disabled if self.page == self.sum_page: self.qd['page'] = self.sum_page html_list.append( '<li class="disabled"><a href="?{}" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format( self.qd.urlencode())) else: self.qd['page'] = self.page + 1 html_list.append( '<li><a href="?{}" aria-label="Next"><span aria-hidden="true">»</span></a></li>'.format( self.qd.urlencode())) # 页码样式的尾 html_list.append('</ul></nav></div>') # 将列表中的html代码拼接起来 html_list = "".join(html_list) return html_list
使用:
from utils import pagination # 导入自定义分页器 page = request.GET.get('page', 1) #获取当前页码参数 pag_obj = pagination.Pagination(page=page, page_count=customer_obj.count(),qd=request.GET.copy(), per_num=3, max_show=10) #实例化分页器对象 customer_obj = customer_obj[pag_obj.start:pag_obj.end] # 对queryset对象进行分页