原文转自:http://qa.taobao.com/blogs/qa?bid=10514
这是本人看到过的关于hadoop的比较容易理解的入门文章,在此转载过来,方便广大像我这样的初级码农。 原文如下:
Hadoop的架构
先抛开Hadoop,简单地想想看,假设我们需要读一个10TB的数据集,怎么办?在传统的系统上,这需要很长时间,因为硬盘的传输速度是受限的。一个简单的办法是将数据存储在多个磁盘上,同时从多个磁盘并行读取数据,这将大大减少读取时间。
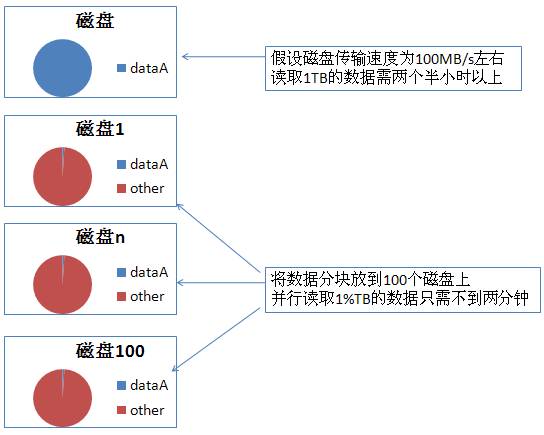
上面的方案需要解决两个主要问题,一个是硬件故障,要保证其中一个硬件坏了但数据仍然完整,Hadoop的文件系统HDFS(Hadoop Distributed Filesystem)提供了一种解决方式。另外一个问题是如何并行读取数据并合并保证正确性,通过MapReduce的编程模型可以简化这个问题。简而言之,Hadoop提供了一个稳定的共享存储和分析系统,存储由HDFS实现,分析由MapReduce实现,这两者构成了Hadoop的核心功能。
HDFS
HDFS集群有两种节点,以管理者-工作者模式运行,即1个名称节点(NameNode)和N个数据节点(DataNode)。其底层实现是将文件切割成块,然后将这些块存储在不同的DataNode上。为了容错容灾,每个块还被复制多份存储在不同的DataNode上。NameNode管理文件系统的命名空间,记录每个文件被切割成了多少块,这些块可以从哪些DataNode上获得,以及各个DataNode的状态信息等。下图是Hadoop集群的简化视图
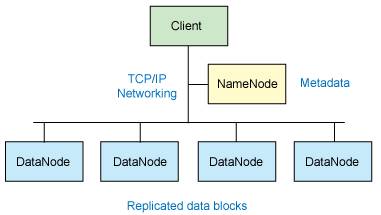
HDFS内部通信都是基于标准的TCP/IP协议,NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。更多HDFS的架构和设计请阅读http://hadoop.apache.org/common/docs/current/cn/hdfs_design.html
MapReduce
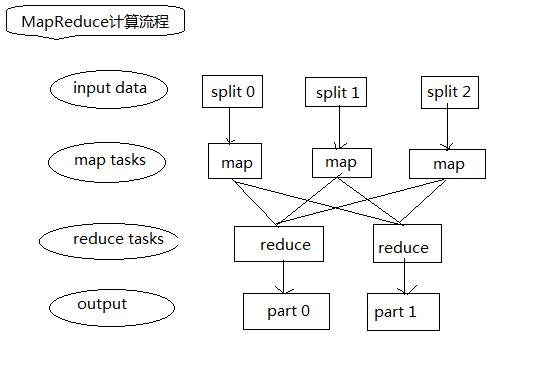
上图说明了用 MapReduce 来处理大数据集的过程, 这个 MapReduce 的计算过程简而言之,就是将大数据集分解为成若干个小数据集,每个(或若干个)数据集分别由集群中的一个结点(一般就是一台普通的计算机)进行处理并生成中间结果,然后这些中间结果又由大量的结点进行合并, 形成最终结果。
计算模型的核心是 Map 和 Reduce 两个函数,这两个函数由用户负责实现,功能是按一定的映射规则将输入的 对转换成另一个或一批 对输出。下图是一个简单的MapReduce示例,实现字数统计功能。

分布式并行运算
Hadoop 的分布式并行运算有一个作为主控的JobTracker,用于调度和管理其它的 TaskTracker, JobTracker 可以运行于集群中任一台计算机上。TaskTracker负责执行任务,必须运行于 DataNode 上,即 DataNode 既是数据存储结点,也是计算结点,这样可以减少数据在网络上的传输,降低对网络带宽的需求。 JobTracker 将 Map 任务和 Reduce 任务分发给空闲的 TaskTracker, 让这些任务并行运行,并负责监控任务的运行情况。如果某一个 TaskTracker 出故障了,JobTracker 会将其负责的任务转交给另一个空闲的 TaskTracker 重新运行。
Hadoop的其他子项目
上面介绍的MapReduce、HDFS、分布式并行运算是Hadoop最核心的功能。还有一些子项目提供补充性服务。如hive(提供基于sql的查询语言查询存储在HDFS中的数据)、Hbase(一种分布式、列存储数据库,适用于需要实时读写、随机访问超大数据集的场景)、Zookeeper(一个分布式、高可用性的协调服务,提供分布式锁之类的基本服务)、pig(一种数据流语言和运行环境,用以检索非常大的数据集,使程序员能专注于数据而不是执行本质)等。
小结
如果你坚持看到这里,或许会觉得失望,介绍了一堆的概念和名词,貌似对你的帮助不大,不要沮丧,第一次接触分布式知识的人大都如此,至少你跟开发又多了些共同语言,下次那个哥们冲你说pig(猪)时,你可以认为他说的是pig(一种数据流语言和运行环境,用以检索非常大的数据集,使程序员能专注于数据而不是执行本质)。