先聊一个人Doug Cutting
Doug Cutting 是一位美国工程师,迷上了搜错引擎。他做了一个用于文本搜索的函数库,命名为Lucene. Lucene 是用java写的,目标是为各种中小型应用软件加入全文搜索功能。Lucene是一套信息检索工具包,并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能。因此在使用Lucenen时仍需关注搜索引擎系统,例如数据获取、解析、分词等方面的东西。
该项目早期被发布在Doug Cutting的个人网站,后来成为了Apache软件基金会jakarta项目的一个子项目。后来在Lucene的基础上开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为Nutch.
Nutch 是一个建立在Lucene核心之上的网页搜索应用程序,它在Lucene的基础上加了爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络上的搜索上。
随着时间的推移,作为互联网搜索引擎,都面临对象“体积”不断增大的问题。需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。
在2004年,Doug Cutting实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。后来他加入了雅虎,将NDFS和MapReduce进行了改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System). 这就是大名鼎鼎的大数据框架系统--Hadoop的由来,而Doug Cutting则被人称为Hadoop之父。
ElasticSearch概述
ElasticSearch,简称es,es是一个开源的高拓展的分布式全文检索引擎,它可以近乎实施的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用java开发并使用Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
谁在使用
- 维基百科,类似百度百科,全文检索,高亮,搜索推荐
- 国外新闻网站,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据,数据分析。。。
- Stack Overflow国外的程序异常讨论论坛
- GitHub(开源代码管理),搜索上千亿行代码
- 电商网站,检索商品
- 日志数据分析,logstash采集日志,ES进行复杂的数据分析,ELK技术(elasticsearch+logstash+kibana)
- 商品价格监控网站
- 商业智能系统
- 站内搜索
ES和solr的差别
ElasticSearch简介
ElasticSearch是一个实施分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用es提供全文搜索并高亮关键字,以及输入实施搜索和搜索纠错等搜索建议功能;英国公报使用es结合用户日志和社交网络数据提供给他们的编辑以实施的反馈,以便了解龚总对新发表的文章的回应。。。
es是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好、功能最全的搜索引擎库。想要使用它,必须使用java来作为开发语言并将其直接继承到你的应用中。
solr简介
Solr是Apache下的一个顶级开源项目,采用java开发,是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展、并对索引、搜索性能进行了优化。它可以独立运行,是一个独立的企业及搜索应用服务器,它对外提供类似于web-service的API接口。用户可以通过http请求,像搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
两者比较
- 当单纯的对已有数据进行搜索时,Solr更快
- 当实时建立索引是,Solr会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势
- 随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化
总结
- es基本是开箱即用,非常简单。而solr会有点复杂。
- Solr利用Zookeeper进行分布式管理,而elasticsearch自身带有分布式协调管理功能
- solr支持更多格式的数据,比如json xml csv。而es只支持json文件格式
- solr官方提供的功能更多,而elasticsearch更注重核心功能,高级功能由第三方插件提供
- solr查询快,但更新索引时慢,用于电商等查询多的应用
- es建立索引宽,即实时性查询快,用于facebook新浪等搜索
- solr较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而elasticsearch相对开发维护者较少,更新太快,学习使用成本较高
ElasticSearch安装
注:安装ElasticSearch之前必须保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。

elasticsearch.yml elastic的一些配置、jvm.options jvm虚拟机的一些配置、log4j2.properties 日志的一些配置文件
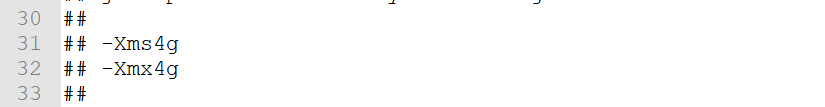
如果机器性能不是太好可以修改jvm.options来进行启动的配置。
点击elasticsearch.bat进行启动。启动成功以后会提示你访问localhost:9200,如果一下的内容。就代表启动成功了
{
"name" : "DESKTOP-HTS2NG8",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Zr-7R7lwQ06RucQN6OyfuA",
"version" : {
"number" : "7.13.4",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "c5f60e894ca0c61cdbae4f5a686d9f08bcefc942",
"build_date" : "2021-07-14T18:33:36.673943207Z",
"build_snapshot" : false,
"lucene_version" : "8.8.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
为了方便查看管理,安装一个图形界面工具elasticsearch-head-master.zip,直接在github上搜索即可,使用git下载下来。在执行npm之前需要配置一下elasticsearch的跨域,打开elasticsearch.yml,在文末加上下面的两句。
# resolve cors
http.cors.enabled: true
http.cors.allow-origin: "*"
执行npm的命令:
npm install # 如果安装不上可以试试cnpm
npm run start # 启动服务
在图形界面中创建一个索引,在初学的阶段可以把索引当作为一个数据库。而这个工具只作为数据的展示,更多的查询会使用Kibana。
Kibana的安装
Kibana的版本要与elasticsearch的版本相同,也是解压以后就可以使用的。启动bin目录下的脚本即可,启动成功后访问http://localhost:5601/。如果对Kibana的英文不适应,可以通过配置文件改为中文。修改配置文件加上如下配置即可。
i18n.locale: "zh-CN"
ES核心概念
ElasticSearch是面向文档型的数据库,一条数据在这里就是一个文档。比如:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
亦可以理解为,一切都是json。
在MySql中这样的数据存储容易想到建立一张User表,其中有一些字段,而在es中就是一个文档,文档会属于一个User类型,各种各样的类型存储于一个索引中。下表是关系型数据库和es的疏于对照表:
| 关系型数据库 | ElasticSearch |
|---|---|
| 数据库 | 索引 |
| 表 | type(已经过时了,会被弃用) |
| 行 | document |
| 列 | field |
es中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档又包含多个字段(列)。
物理设计:
elasticsearch在后台把每个索引划分成多个分片。每个分片可以在集群中的不同服务器间迁移
逻辑设计:
一个索引类型中,抱哈an多个文档,当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引-》类型-》文档id,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是一个字符串。
文档
就是我们的一条条的记录
之前说elasticsearch是面向文档的,那么就意味着索弓和搜索数据的最小单位是文档, elasticsearch中,文档有几个重要属性:
自我包含, - -篇文档同时包含字段和对应的值,也就是同时包含key:value !
可以是层次型的,-一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一 个json对象! fastjson进行自动转换!}
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定 义称为映射,比如name映射为字符串类型。我们说文档是无模式的 ,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, elasticsearch就开始猜,如果这个值是18 ,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对 ,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引
就是数据库!
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。索|存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
一个集群至少有一 个节点,而一个节点就是一个elasricsearch进程 ,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有-一个副本( replica shard ,又称复制分片)
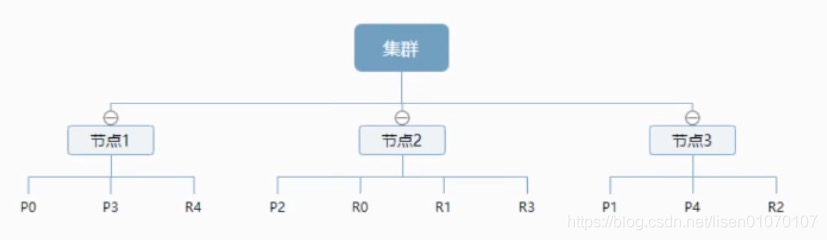
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同-个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上, 一个分片是- -个Lucene索引, -一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch使用的是一种称为倒排索引 |的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文
档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up to forever # 文 档1包含的内容
To forever, study every day,good good up # 文档2包含的内容
为为创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,然后创建一一个包含所有不重 复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | x |
| To | x | x |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | x | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | x |
| up | √ | √ |
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | x |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
| 博客文章(原始数据) | 博客文章(原始数据) | 索引列表(倒排索引) | 索引列表(倒排索引) |
|---|---|---|---|
| 博客文章ID | 标签 | 标签 | 博客文章ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux |
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中 ,索引被分为多个分片,每份分片是个Lucene的索引。所以一个elasticsearch索引是由多 个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
ik分词器
什么是IK分词器 ?
分词:即把一-段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神”会被分为"我",“爱”,“狂”,“神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
如果要使用中文,建议使用ik分词器!
IK提供了两个分词算法: ik_ smart和ik_ max_ word ,其中ik_ smart为最少切分, ik_ max_ _word为最细粒度划分!一会我们测试!
【ik_smart】测试:
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是社会主义接班人"
}
//输出
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "社会主义",
"start_offset" : 2,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "接班人",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
}
]
}
【ik_max_word】测试:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我是社会主义接班人"
}
//输出
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "社会主义",
"start_offset" : 2,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "社会",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "主义",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "接班人",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "接班",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "人",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 7
}
]
}
安装尽量对应版本号,下载解压,复制到elasticsearch中重启即可。
命令模式的使用
Rest风格说明
一种软件架构风格,而不是标准。更易于实现缓存等机制。
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
创建一个索引
PUT /索引名/类型名(高版本都不写了,都是_doc)/文档id
PUT /listen/type1/1
{
"name":"Marvin",
"age":26
}
# result
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_version" : 1, # 第一次添加
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1, # 成功
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
在http://localhost:9100/上也是可以查到数据的。
elastic中的一些类型
可以通过GET请求获得具体的信息
GET listen
#result
{
"listen" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
.......
}
最开始我们put的时候并没有设置类型,这是应为es会自动进行类型的设置。
es的一些命令
cat
GET _cat/health # 获得健康状态
GET _cat/indices?v #获取所有信息
更新操作
# 直接在原有的基础上进行了更新
PUT /listen/type1/1
{
"name":"Marvin",
"age":26,
"sex":"man"
}
# result
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_version" : 2, # 每次操作后会加1
"result" : "updated", # 最近一次的操作记录
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
# 然而上面的操作方式字段是不能有遗漏的,负责会被清空,比较稳妥的方式是在后面加上 _update
POST /listen/type1/1/_update
{
"doc":{
"name":"Marvin Guo"
}
}
# result
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Marvin Guo",
"age" : 26,
"sex" : "man"
}
}
删除操作
DELETE /listen/type1/1
简单查询
GET listen/type1/_search?q=name:Marvin # 简单的查询,name在这是text类型,如果是keyword是不会被分词的
# result
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.15965708,
"hits" : [
{
"_index" : "listen",
"_type" : "type1",
"_id" : "2",
"_score" : 0.15965708,
"_source" : {
"name" : "Marvin",
"age" : 26,
"sex" : "man"
}
},
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_score" : 0.12343237,
"_source" : {
"name" : "Marvin Guo",
"age" : 26,
"sex" : "man"
}
}
]
}
}
复杂操作搜索select(排序,分页,高亮,模糊查询,精准查询)
GET listen/type1/_search
{
"query":{
"match":{
"name":"Marvin"
}
}
}
#result
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.15965708,
"hits" : [
{
"_index" : "listen",
"_type" : "type1",
"_id" : "2",
"_score" : 0.15965708,
"_source" : {
"name" : "Marvin",
"age" : 26,
"sex" : "man"
}
},
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_score" : 0.12343237,
"_source" : {
"name" : "Marvin Guo",
"age" : 26,
"sex" : "man"
}
}
]
}
}
# 结果比上面的查询丰富
还可以进行结果过滤,就是只展示列表中某些字段
GET listen/type1/_search
{
"query":{
"match":{
"name":"Marvin"
}
},
"_source":["name","age"]
}
# result
.....
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_score" : 0.160443,
"_source" : {
"name" : "Marvin Guo",
"age" : 26
}
....
也可以忽略一些字段:
GET listen/type1/_search
{
"query":{
"match":{
"name":"Marvin"
}
},
"_source":{"excludes":["name","age"]}
}
# result
{
"_index" : "listen",
"_type" : "type1",
"_id" : "1",
"_score" : 0.160443,
"_source" : {
"sex" : "man"
}
排序与分页
GET listen/type1/_search
{
"query":{
"match":{
"name":"Marvin"
}
},
"sort":{
"age":{
"order":"asc"
}
},
"from":0,
"size":1
}
多条件查询
布尔值查询
must(and),所有的条件都要符合
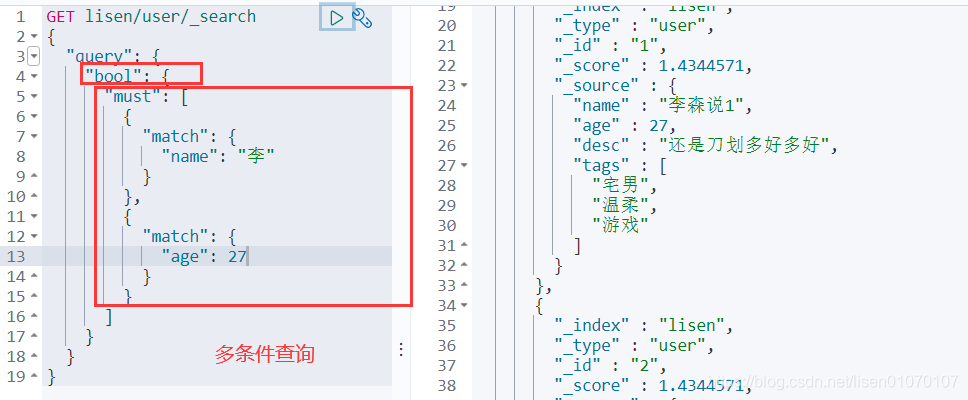
should(or)或者的 跟数据库一样
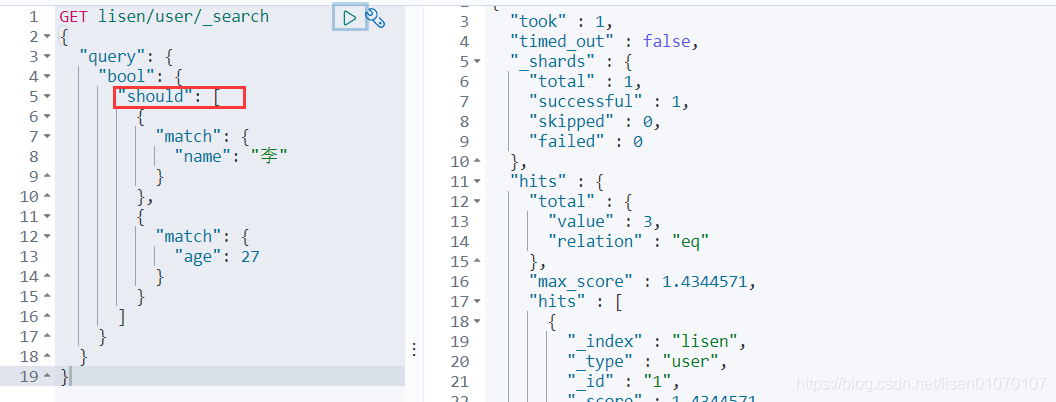
must_not(not)

条件区间
gt大于
gte大于等于
lte小于
lte小于等于
匹配多个条件(数组)

match没用倒排索引 这边改正一下
精确查找
term查询是直接通过倒排索引指定的词条进程精确查找的
关于分词
term,直接查询精确的
match,会使用分词器解析!(先分析文档,然后通过分析的文档进行查询)
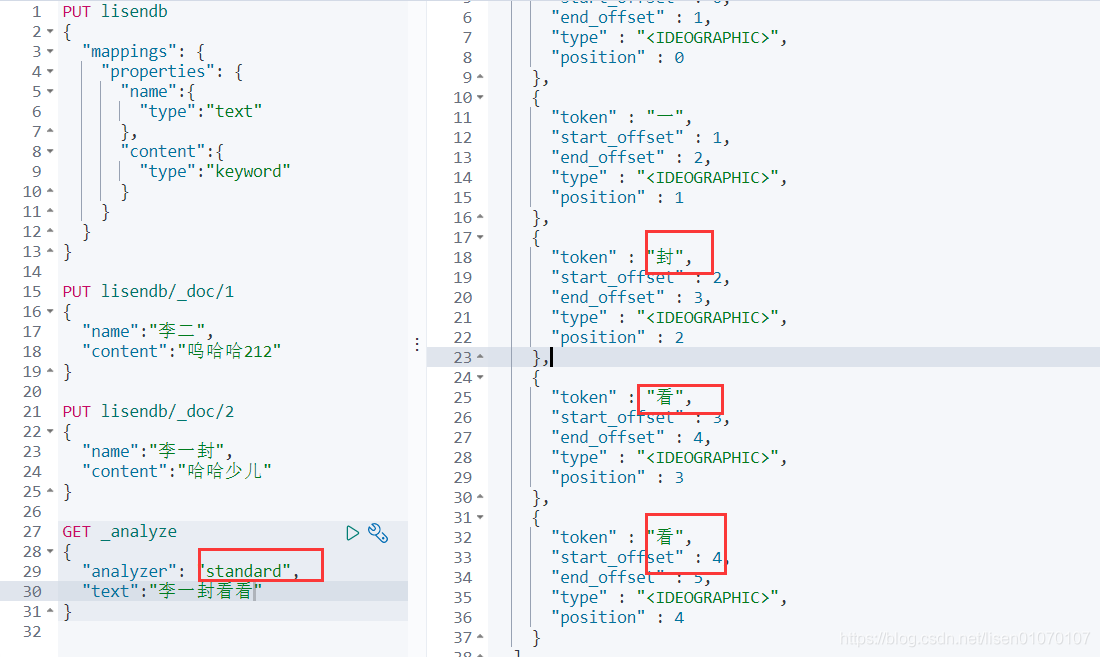
默认的是被分词了

keyword没有被分词
精确查询多个值

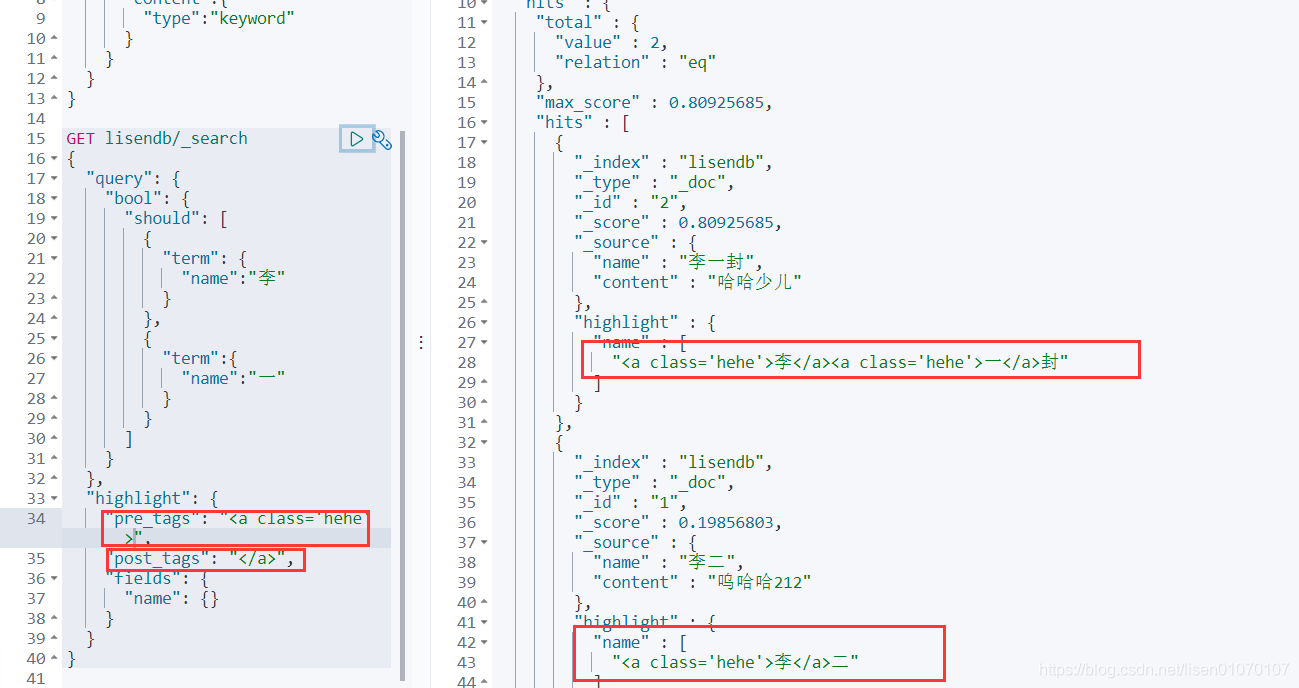
高亮
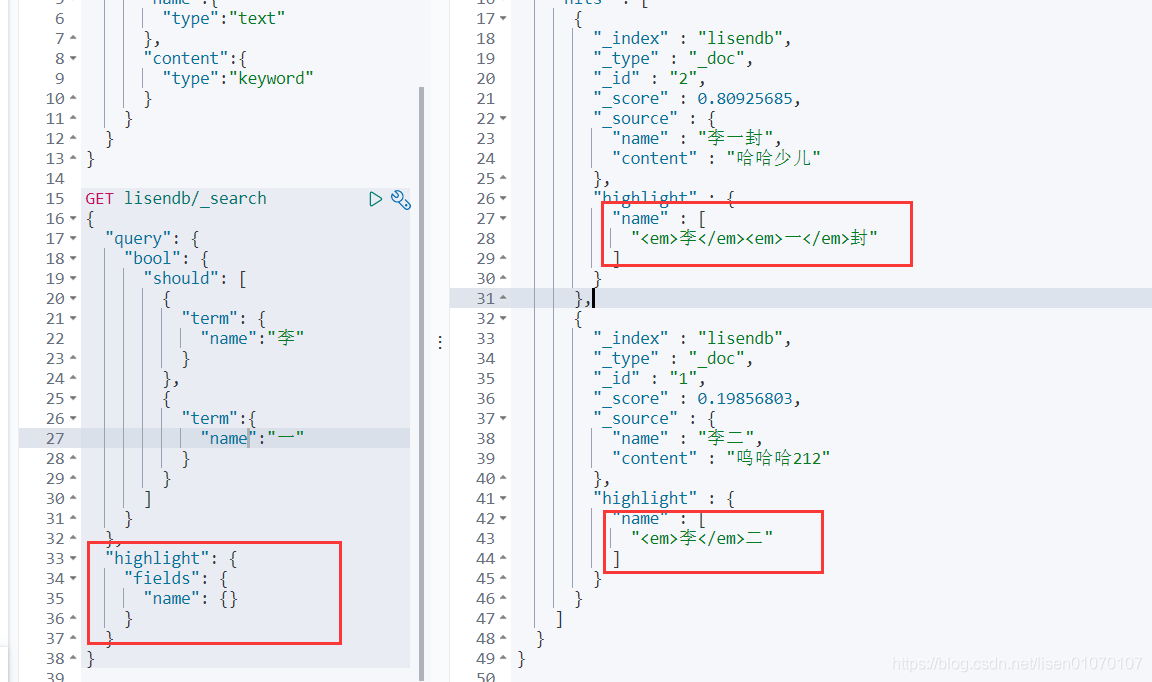
还能自定义高亮的样式
整合SpringBoot
引入依赖包
创建一个springboot的项目,直接在idea上创建即可,同时勾选上springboot-web的包以及Nosql的elasticsearch的包
如果没有就手动引入:
<!--es客户端-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<!--springboot的elasticsearch服务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
注意下spring-boot的parent包内的依赖的es的版本是不是你对应的版本
不是的话就在pom文件下写个properties的版本:
<!--这边配置下自己对应的版本-->
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.13.4</elasticsearch.version>
</properties>
注入RestHighLevelClient 客户端
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
索引的增、删、是否存在
//测试索引的创建
@Test
void testCreateIndex() throws IOException {
//1.创建索引的请求
CreateIndexRequest request = new CreateIndexRequest("lisen_index");
//2客户端执行请求,请求后获得响应
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
//测试索引是否存在
@Test
void testExistIndex() throws IOException {
//1.创建索引的请求
GetIndexRequest request = new GetIndexRequest("lisen_index");
//2客户端执行请求,请求后获得响应
boolean exist = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("测试索引是否存在-----"+exist);
}
//删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("lisen_index");
AcknowledgedResponse delete = client.indices().delete(request,RequestOptions.DEFAULT);
System.out.println("删除索引--------"+delete.isAcknowledged());
}
文档的操作
//测试添加文档
@Test
void testAddDocument() throws IOException {
User user = new User("lisen",27);
IndexRequest request = new IndexRequest("lisen_index");
request.id("1");
//设置超时时间
request.timeout("1s");
//将数据放到json字符串
request.source(JSON.toJSONString(user), XContentType.JSON);
//发送请求
IndexResponse response = client.index(request,RequestOptions.DEFAULT);
System.out.println("添加文档-------"+response.toString());
System.out.println("添加文档-------"+response.status());
// 结果
// 添加文档-------IndexResponse[index=lisen_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
// 添加文档-------CREATED
}
//测试文档是否存在
@Test
void testExistDocument() throws IOException {
//测试文档的 没有index
GetRequest request= new GetRequest("lisen_index","1");
//没有indices()了
boolean exist = client.exists(request, RequestOptions.DEFAULT);
System.out.println("测试文档是否存在-----"+exist);
}
//测试获取文档
@Test
void testGetDocument() throws IOException {
GetRequest request= new GetRequest("lisen_index","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println("测试获取文档-----"+response.getSourceAsString());
System.out.println("测试获取文档-----"+response);
// 结果
// 测试获取文档-----{"age":27,"name":"lisen"}
// 测试获取文档-----{"_index":"lisen_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"age":27,"name":"lisen"}}
}
//测试修改文档
@Test
void testUpdateDocument() throws IOException {
User user = new User("李逍遥", 55);
//修改是id为1的
UpdateRequest request= new UpdateRequest("lisen_index","1");
request.timeout("1s");
request.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println("测试修改文档-----"+response);
System.out.println("测试修改文档-----"+response.status());
// 结果
// 测试修改文档-----UpdateResponse[index=lisen_index,type=_doc,id=1,version=2,seqNo=1,primaryTerm=1,result=updated,shards=ShardInfo{total=2, successful=1, failures=[]}]
// 测试修改文档-----OK
// 被删除的
// 测试获取文档-----null
// 测试获取文档-----{"_index":"lisen_index","_type":"_doc","_id":"1","found":false}
}
//测试删除文档
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request= new DeleteRequest("lisen_index","1");
request.timeout("1s");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println("测试删除文档------"+response.status());
}
//测试批量添加文档
@Test
void testBulkAddDocument() throws IOException {
ArrayList<User> userlist=new ArrayList<User>();
userlist.add(new User("cyx1",5));
userlist.add(new User("cyx2",6));
userlist.add(new User("cyx3",40));
userlist.add(new User("cyx4",25));
userlist.add(new User("cyx5",15));
userlist.add(new User("cyx6",35));
//批量操作的Request
BulkRequest request = new BulkRequest();
request.timeout("1s");
//批量处理请求
for (int i = 0; i < userlist.size(); i++) {
request.add(
new IndexRequest("lisen_index")
.id(""+(i+1))
.source(JSON.toJSONString(userlist.get(i)),XContentType.JSON)
);
}
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
//response.hasFailures()是否是失败的
System.out.println("测试批量添加文档-----"+response.hasFailures());
// 结果:false为成功 true为失败
// 测试批量添加文档-----false
}
//测试查询文档
@Test
void testSearchDocument() throws IOException {
SearchRequest request = new SearchRequest("lisen_index");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//设置了高亮
sourceBuilder.highlighter();
//term name为cyx1的
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "cyx1");
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("测试查询文档-----"+JSON.toJSONString(response.getHits()));
System.out.println("=====================");
for (SearchHit documentFields : response.getHits().getHits()) {
System.out.println("测试查询文档--遍历参数--"+documentFields.getSourceAsMap());
}
// 测试查询文档-----{"fragment":true,"hits":[{"fields":{},"fragment":false,"highlightFields":{},"id":"1","matchedQueries":[],"primaryTerm":0,"rawSortValues":[],"score":1.8413742,"seqNo":-2,"sortValues":[],"sourceAsMap":{"name":"cyx1","age":5},"sourceAsString":"{"age":5,"name":"cyx1"}","sourceRef":{"fragment":true},"type":"_doc","version":-1}],"maxScore":1.8413742,"totalHits":{"relation":"EQUAL_TO","value":1}}
// =====================
// 测试查询文档--遍历参数--{name=cyx1, age=5}
}
模拟JD搜索的部分核心代码
ElasticSearchClientConfig
package com.huang.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
//狂神Spring两步骤
//1.找对象
//2.放到Spring中待用
//3.如果是SpringBoot就分析一波源码
//XXXAutoConfiguration XXXProperties
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
pojo
Content
package com.huang.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {
private String img;
private String price;
private String title;
}
HtmlParseUtil
package com.huang.util;
import com.alibaba.fastjson.JSON;
import com.huang.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keywords) throws IOException {
//获取请求: https://search.jd.com/Search?keyword=java&enc=utf-8&wq=java&pvid=f807c58b66dc4baab4c7ed71834c36be
//前提,联网,ajax不能获得
String url = "https://search.jd.com/Search?keyword="+keywords+"&enc=utf-8";
//解析网页。(JIsoup返 回Document就是浏览器Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
//所有你在js中可以使用的方法,这里都能用!
Element element = document.getElementById("J_goodsList");
//System.out.println(element.html());
//获取所有的Li元素
Elements elements = element.getElementsByTag("li");
//
List<Content> contents = new ArrayList<>();
//获取元素中的内容,这野l就是每一 个Li标签了!
for (Element el : elements) {
//由于图片是延迟加载
//data-lazy-img
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
/*System.out.println("===============================");
System.out.println(img);
System.out.println(price);
System.out.println(title);*/
contents.add(new Content(img,price,title));
}
return contents;
}
public static void main(String[] args) throws IOException {
new HtmlParseUtil().parseJD("耐克").forEach(System.out::println);
}
}
IndexController
package com.huang.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class IndexController {
@RequestMapping({"/","/index"})
public String index(){
return "index";
}
}
ContentController
package com.huang.controller;
import com.huang.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
//请求编写
@RestController//只返回数据
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyword) throws Exception {
return contentService.parseContent(keyword);
}
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
//return contentService.searchPage(keyword, pageNo, pageSize);searchPageHighlightBuilder
return contentService.searchPageHighlightBuilder(keyword, pageNo, pageSize);
}
}
Service
package com.huang.service;
import com.alibaba.fastjson.JSON;
import com.huang.pojo.Content;
import com.huang.util.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
//业务编写
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
// 1.解析数据放入 es索引中
public Boolean parseContent(String keywords) throws Exception {
List<Content> contents = new HtmlParseUtil().parseJD(keywords);
/*// 1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("jd_goods");
// 2、客户端执行请求 IndicesClient,请求后获得响应
System.out.println("创建开始");
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println("创建成功");*/
//把查询到的数据放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(
new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
// 2.获取这些数据实现搜索功能
public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
// 2.获取这些数据实现搜索高亮功能
public List<Map<String, Object>> searchPageHighlightBuilder(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false); //多个高亮显示
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //原来的结果!
//解析高亮的字段,将原来的字段换为我们高亮的字段即可!
if (title != null) {
Text[] fragments = title.fragments();
String n_title = "";
for (Text text : fragments) {
n_title += text;
sourceAsMap.put("title", n_title); //高亮字段替换掉原来的内容即可!
}
list.add(sourceAsMap);
}
}
return list;
}
}
具体的代码见oneNote收藏。