D8 文件操作
1. 文件操作
f.read(n):
1. 文件打开方式为文本模式时,代表读取n个字符
2. 文件打开方式为b模式时,代表读取n个字节
f.seek(n):
按字节调整光标的位置
seek(n)光标移动到n位置,注意: 移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
通常我们使用seek都是移动到开头或者结尾
移动到开头:seek(0)
移动到结尾:seek(0,2)
seek的第二个参数表示的是从哪个位置进行偏移,默认是0,表示开头,1表示当前位置,2表示结尾
f.tell():
按字节告诉我们当前光标在什么位置
f.truncate(n)
按字节截取部分文件
Python 文件 truncate() 方法用于截断文件并返回截断的字节长度。
指定长度的话,就从文件的开头开始截断指定长度,其余内容删除;不指定长度的话,就从文件开头开始截断到当前位置,其余内容删除。
with open('t1',encoding='utf-8') as f1,
open('Test', encoding='utf-8', mode = 'w') as f2:
f1.read()
f2.write('老男孩老男孩')
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,
都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,
再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
1 import os 2 3 with open('a.txt') as read_f, open('.a.txt.swap', 'w') as write_f: 4 for line in read_f: 5 line = line.replace('alex', 'SB') 6 write_f.write(line) 7 os.remove('a.txt') 8 os.rename('.a.txt.swap', 'a.txt')
D9 函数
1 a = 6 2 def demo(): 3 a += 1 # 若要修改全局变量,则需用global声明。 4 print(a) 5 return 6 demo() # 报错。 7 8 a = [1] 9 def demo(): 10 a.append(2) 11 print(a) 12 return 13 demo() # 打印 [1, 2]
总结:
○ 如果在函数中修改全局变量,那么就需要使用global进行声明,否则出错
○ 在函数中不使用global声明全局变量时不能修改全局变量的本质是不能修改全局变量的指向,即不能将全局变量指向新的数据。
○ 对于不可变类型的全局变量来说,因其指向的数据不能修改,所以不使用global时无法修改全局变量。
○ 对于可变类型的全局变量来说,因其指向的数据可以修改,所以不使用global时也可修改全局变量。
D 10
解包在英文里叫做 Unpacking

如果列表中有3个元素,那么刚好可以分配给3个变量。除了列表对象可以解包之外,任何可迭代对象都支持解包

字符串解包

字典解包
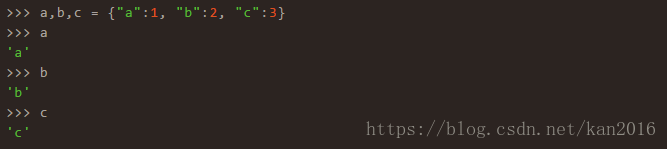
字典解包后,只会把字典的 key 取出来,value 则丢掉了。
你可能见过多变量赋值操作,例如:

本质上也是自动解包过程,等号右边其实是一个元组对象 (1, 2),有时候我们代码不小心多了一个逗号 ,,就变成了元组对象

所以写代码的时候需要特别注意。在 Python 中,交换两个变量非常方便,本质上也是自动解包过程。

如果在解包过程中,遇到左边变量个数小于右边可迭代对象中元素的个数时该怎么办?
在 Python2 中,如果等号左边变量的个数不等于右边可迭代对象中元素的个数,是不允许解包的。
但在 Python3 可以这么做了。这个特性可以在 PEP 3132 中看到。

*星号语法 ; 右分 左合 传递参数是解包、拆包 接收参数是组包、合包 *星号表示是包语法,*b 中 b就是包对象
这种语法就是在某个变量面前加一个星号,而且这个星号可以放在任意变量前面
别的每个变量都分配一个元素后,剩下的元素都分配给这个带星号的变量

这种语法有什么好处呢?它使得你的代码写起来更简洁,比如上面例子,在 Python2 中该怎么操作呢?思考3秒钟,再看答案。

以上是表达式解包的一些操作,接下来介绍函数调用时的解包操作。
函数调用时,有时你可能会用到两个符号:星号*和 双星号**。

func 函数定义了三个位置参数 a,b,c,调用该函数必须传入三个参数,除此之外,你也可以传入包含有3个元素的可迭代对象,
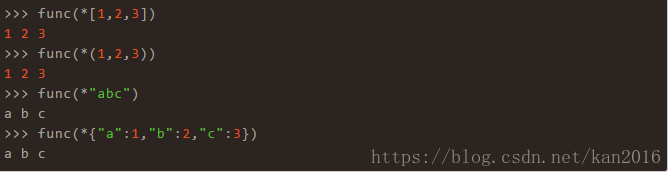
函数被调用的时候,使用星号 * 解包一个可迭代对象作为函数的参数。
字典对象,可以使用两个星号,解包之后将作为关键字参数传递给函数

看到了吗?和上面例子的区别是多了一个星号,结果完全不一样,原因是什么?
答案是** 符号作用的对象是字典对象,它会自动解包成关键字参数 key=value 的格式:
总结一下,一个星号可作用于所有的可迭代对象,称为迭代器解包操作,作为位置参数传递给函数,
两个星号只能作用于字典对象,称之为字典解包操作,作为关键字参数传递给函数。
使用 *和 ** 解包的好处是能节省代码量,使得代码看起来更优雅,不然你得这样写:

在 3.5 之前的版本,函数调用时,一个函数中解包操作只允许一个* 和 一个**。从 3.5 开始,在函数调用中,可以有任意多个解包操作,例如:

再来看看 python3.5以上版本

从 3.5 开始可以接受多个解包,于此同时,解包操作除了用在函数调用,还可以作用在表达式中。

新的语法使得我们的代码更加优雅了,例如拼接两个列表可以这样:

可不可以直接用 + 操作呢?不行,因为 list 类型无法与 range 对象相加,你必须先将 list2 强制转换为 list 对象才能做 +操作。
再来看一个例子:如何优雅的合并两个字典

在3.5之前的版本,你不得不写更多的代码:

到此,关于 Python 解包给你介绍完了。
最后总结一下:
- 自动解包支持一切可迭代对象
- 函数调用时,可以用 * 或者 ** 解包可迭代对象,作为参数传递
- python3.5,函数调用和表达式中可支持更多的解包操作。
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,
其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问。
ok